Kano模型
# Kano 模型
# 1、作用
卡诺模型(Kano 模型)是对产品功能定位以及确定产品功能优先级的工具,以分析产品功能对用户满意的影响为基础,体现了产品功能和用户满意之间的非线性关系。
# 2、输入输出描述
输入: 正向题是指假设产品拥有该项功能,用户的满意情况。
反向题是指假设产品不拥有该项功能,用户的满意情况。
输出:基于根据产品功能具备度与用户满意度的关系,得到产品功能的定位结果及优先级。
# 3、案例示例
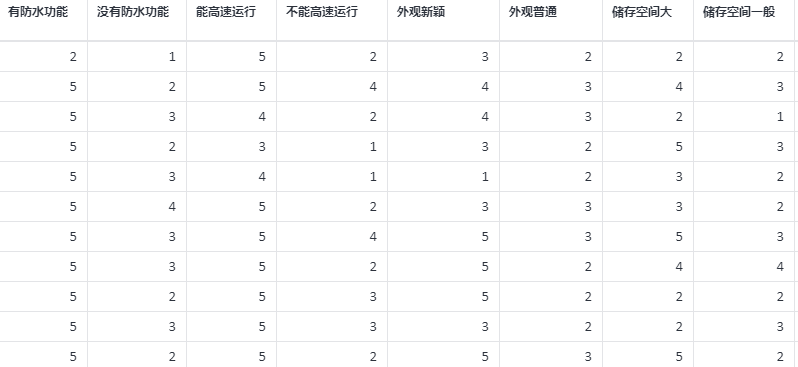
案例:如某电脑公司开发新电脑为例,新电脑有速度快、防水、外形新颖、存储空间大这 4 种功能,某公司用 Kano 模型对这组需求进行功能定位,由此根据功能定位结果可以帮助公司优先开发哪种功能。(其中 1,2,3,4,5 分别代替不喜欢、能忍受、无所谓、理应如此、喜欢。)
# 4、案例数据

# 5、案例操作
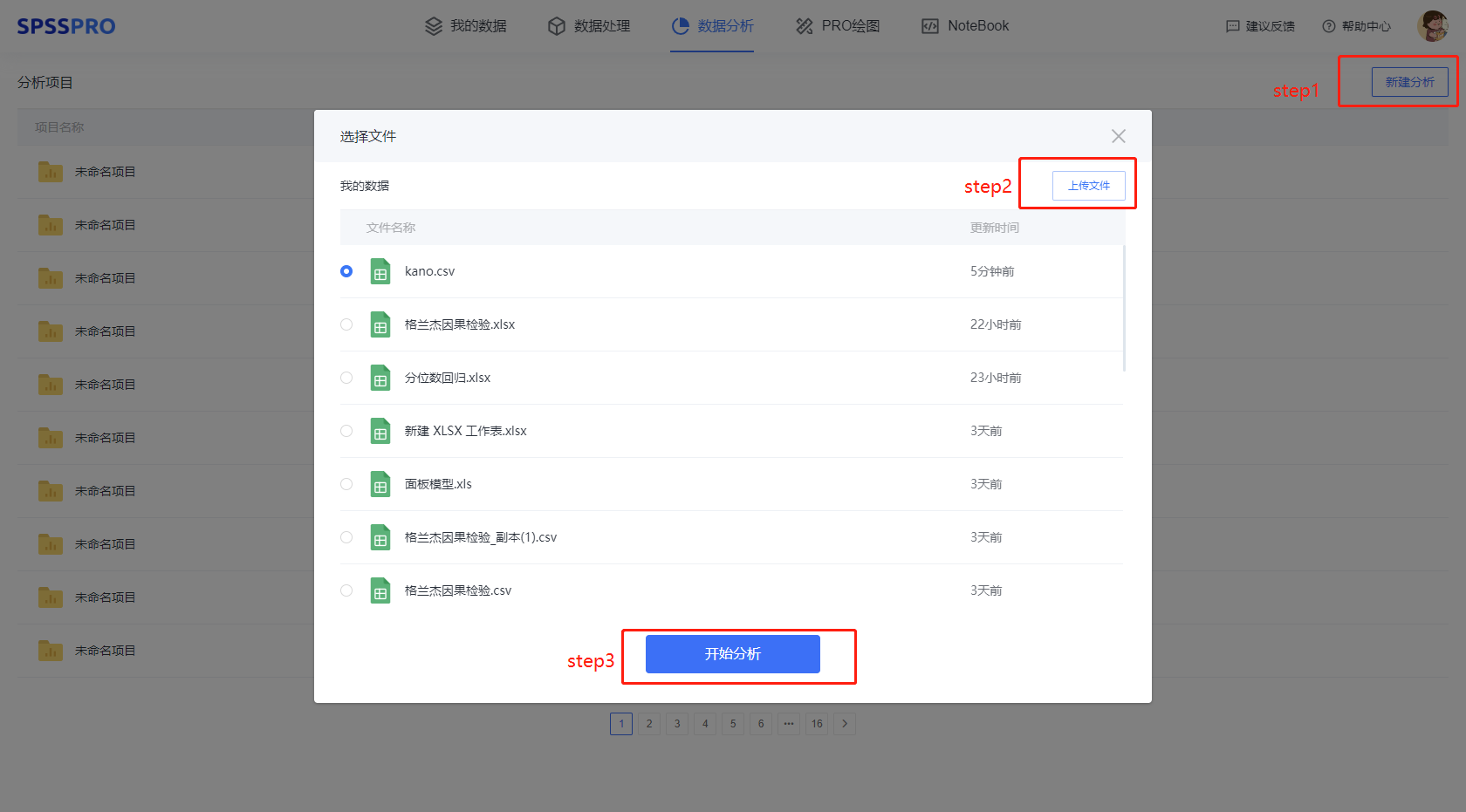
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;

Step4:选择【Kano 模型】;
Step5:查看对应的数据数据格式,按要求拖入数据。
Step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:Kano 模型定位对照表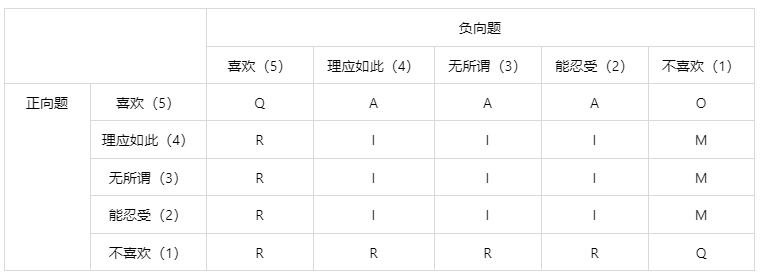
图表说明:上表展示了 Kano 模型定位对照表,根据产品功能具备度与用户满意度的关系,将产品功能分为五类特性(魅力特性 A、期望特性 O、必备特性 M、无差异特性 I、反向特性 R)以及一类可疑结果 Q。
1)魅力特性(A),若不提供此类功能,使用者满意度不会降低,但当提供此类功能时,满意度会极大提升,有时是产品具有竞争力的保证。
2)期望特性(O),若提供此类功能时,使用者满意度会提升,反之则降低。
3) 必备特性(M),当提供此类功能时,使用者满意度不会明显提升,但不提供此类功能时满意度会大幅降低,是必须被保障的基础需求。
4)无差异特性(I),即无论提供或不提供此类功能,使用者满意度并不会有明显变化。在条件有限的情况下,可以不优先提供此类功能。
5)反向特性(R),即使用者没有此功能,若提供反而会导致满意度下降。
6)可疑结果(Q),即受访者没有很好理解某问项或误答。
输出结果 2:Kano 模型分析结果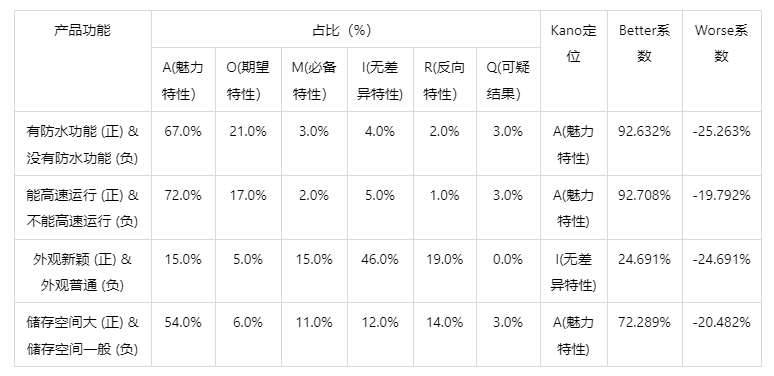
图表说明:上表展示了 Kano 模型分析结果,包括产品功能的 Kano 定位结果,根据定位结果有利于确定产品开发功能的优先级。
- 每个产品功能的最终 Kano 定位结果是指拥有最大占比的类别,通常情况下产品开发的优先级为:必备特性 > 期望特性 > 魅力特性 > 无差异特性。
- Better-Worse 系数的计算:
(1)增加后的满意系数的数值通常为正,正值越大 / 越接近 1,也就是 100%,则表示用户满意度提升的效果会越强,满意度上升的越快。
(2)消除后的不满意系数的数值通常为负,其负值越小 / 越接近 -1,也就是-100%,则表示对用户不满意度的影响最大,满意度降低的影响效果越强,下降的越快。
输出结果 3:Better-Worse 矩阵分析图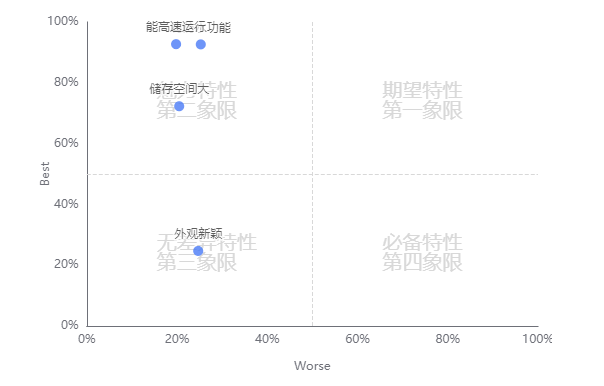
图表说明:上图展示了 Better-Worse 矩阵分析图,通过矩阵图直观地展现了产品功能的定位,根据定位结果有利于确定产品开发功能的优先级。
- 根据 Better-Worse 系数值(其中 Worse 是取绝对值)将散点图划分为四个象限。
1、第一象限(期望特性)表示:better 系数值高,worse 系数绝对值也很高的情况。即表示产品提供此功能,用户满意度会提升,当不提供此功能,用户满意度就会降低,这是质量的竞争性属性,应尽力去满足用户的期望型需求。提供用户喜爱的额外服务或产品功能,使其产品和服务优于竞争对手并有所不同,引导用户加强对本产品的良好印象。
2、第二象限(魅力特性):better 系数值高,worse 系数绝对值低的情况。即表示不提供此功能,用户满意度不会降低,但当提供此功能,用户满意度和忠诚度会有很大提升。
3、第三象限(无差异特性):better 系数值低,worse 系数绝对值也低的情况。即无论提供或不提供这些功能,用户满意度都不会有改变,这些功能点是用户并不在意的功能。
4、第四象限(必备特性):better 系数值低,worse 系数绝对值高的情况。即表示当产品提供此功能,用户满意度不会提升,当不提供此功能,用户满意度会大幅降低;说明落入此象限的功能是最基本的功能,这些需求是用户认为我们有义务做到的事情。 - 通常情况下,产品开发需求的优先级为:必备特性>期望特性>魅力特性>无差异特性。
# 7、注意事项
- 在使用 SPSSPRO 进行运算前,需要将问卷的五个等级进行量化,使用 1,2,3,4,5 分别代替不喜欢、能忍受、无所谓、理应如此、喜欢。
# 8、模型理论
Kano 模型根据收集整理的功能分析设计问卷调查表,在问卷设计时,把问卷尽量设计得清晰易懂、语言尽量简单具体,避免语意产生歧义。同时,可以在在问卷中加入简短且明显的提示或说明。方便用户顺利填答。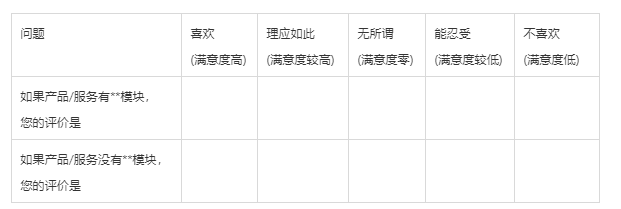
待收集得到数据后,根据下图的规则对产品功能分为五类特性(魅力特性 A、期望特性 O、必备特性 M、无差异特性 I、反向特性 R)以及一类可疑结果 Q。
1)魅力特性(A),若不提供此类功能,使用者满意度不会降低,但当提供此类功能时,满意度会极大提升,有时是产品具有竞争力的保证。
2)期望特性(O),若提供此类功能时,使用者满意度会提升,反之则降低。
3) 必备特性(M),当提供此类功能时,使用者满意度不会明显提升,但不提供此类功能时满意度会大幅降低,是必须被保障的基础需求。
4)无差异特性(I),即无论提供或不提供此类功能,使用者满意度并不会有明显变化。在条件有限的情况下,可以不优先提供此类功能。
5)反向特性(R),即使用者没有此功能,若提供反而会导致满意度下降。
6)可疑结果(Q),即受访者没有很好理解某问项或误答。
还可以计算 Better-Worse 系数来分析用户的满意度。
Better-Worse 系数的计算:
(1)增加后的满意系数
(2)消除后的不满意系数
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] 郑林欣,沃晨雯,王思奇,等. 基于 Kano 模型的蜡染技艺体验设计[J]. 丝绸,2022,59(1):102-108. DOI:10.3969/j.issn.1001-7003.2022.01.015.