MaxDiff模型
# MaxDiff模型
# 1、作用
用于受访者客户对产品属性的偏好程度,目前被广泛的应用在市场调研领域。
# 2、输入输出描述
输入: ”最重要“次数是某属性被选中为最重要的次数。
”最不重要“次数是某属性被选中为最不重要的次数。
总出现次数是在指某属性出现在问卷中,等待被选择的次数。
索引项是指各个属性的名称。
输出:受访者对属性的偏好程度。
# 3、案例示例
案例:某饮食行业品牌公司欲了解消费者对零食的偏好。一共有六个属性指标(分别是价格、分量、味道、包装、营养、能量),可以通过用户反馈回来的信息(也就是输入数据)来判断消费者更看中零食的哪个属性。
# 4、案例数据
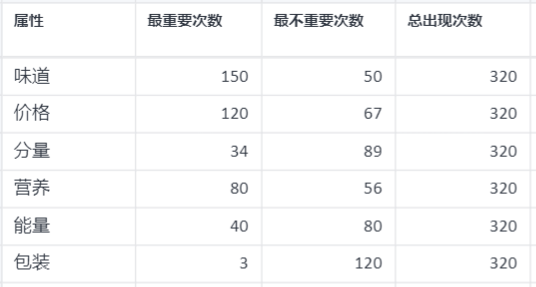
MaxDiff模型案例数据
MaxDiff输入的数据为一个特定的问卷数据,它的编写和搜集方案如下:
它要求受访者在每一次任务中选出“最重要属性”和“最不重要属性”,比如,以上零食有 6 个属性。问卷是设置了 6 个任务,每一个任务包括三种选择项。它的意思是每一个受访者需要完成 6 个任务,每一个任务都是从三个选择项中选出“最重要属性”和“最不重要属性”。第一个任务是指受访者需要从"价格、味道、分量"中选出认为最重要的以及最不重要的。

问卷设计好后应发放给受访者回答,然后需要对所有问卷结果进行基本汇总,得到满足 SPSSPRO 输入要求的案例数据。那么总出现次数,就是在所有问卷的任务中,某个属性出现的次数,以及它被选为"最重要"的次数、它被选为"最不重要"的次数。 假设下面是两个受访者的回答情况:
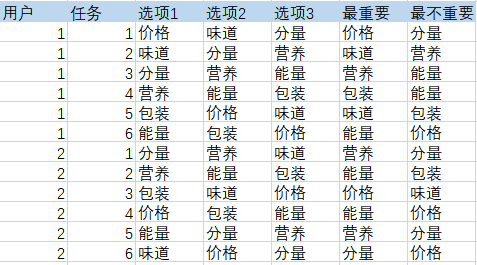
可以统计得到:
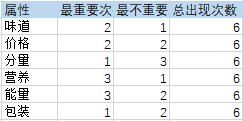
以上只是举例,对所有问卷结果进行基本汇总,就可以得到满足 SPSSPRO 输入要求的案例数据。
# 5、案例操作
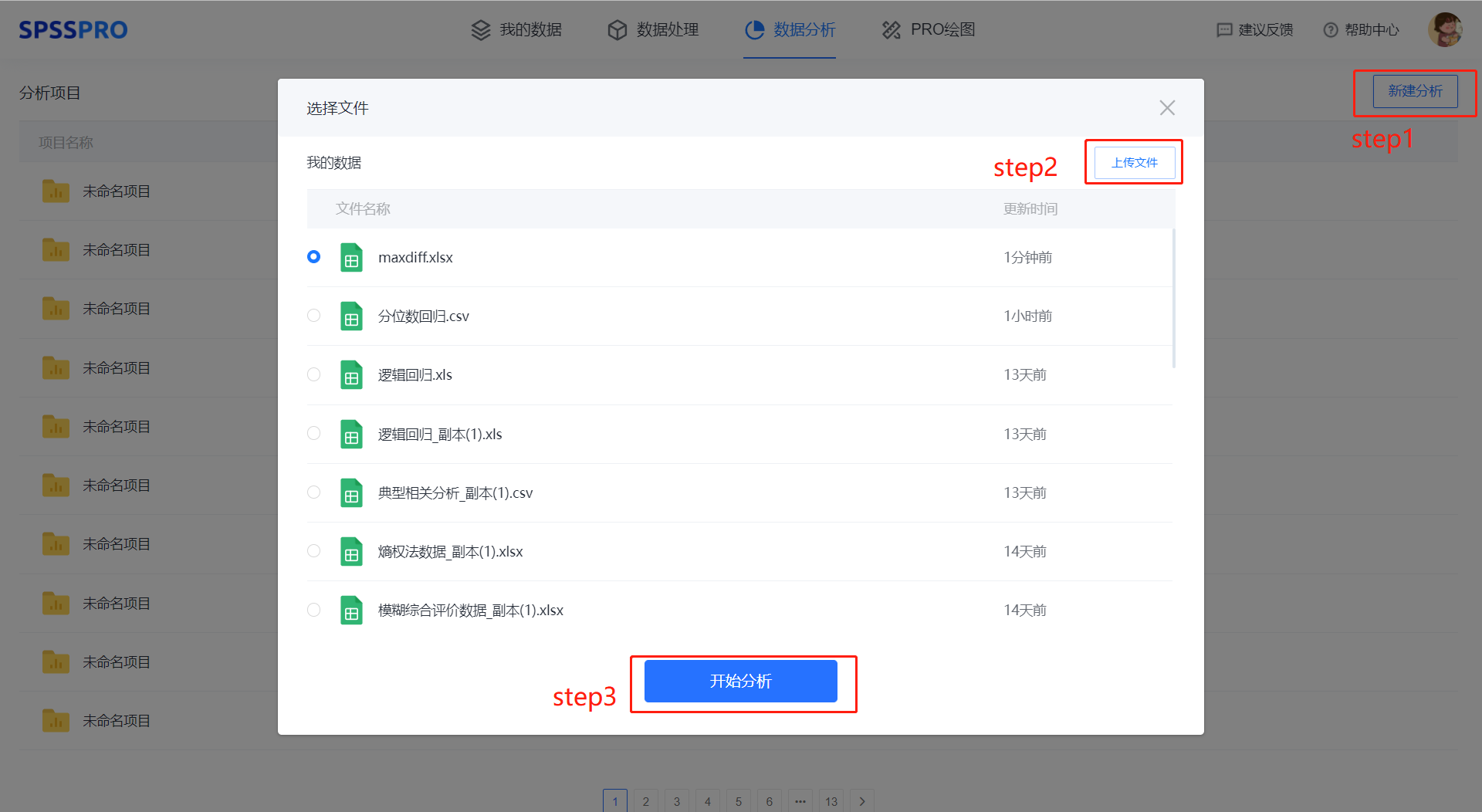
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
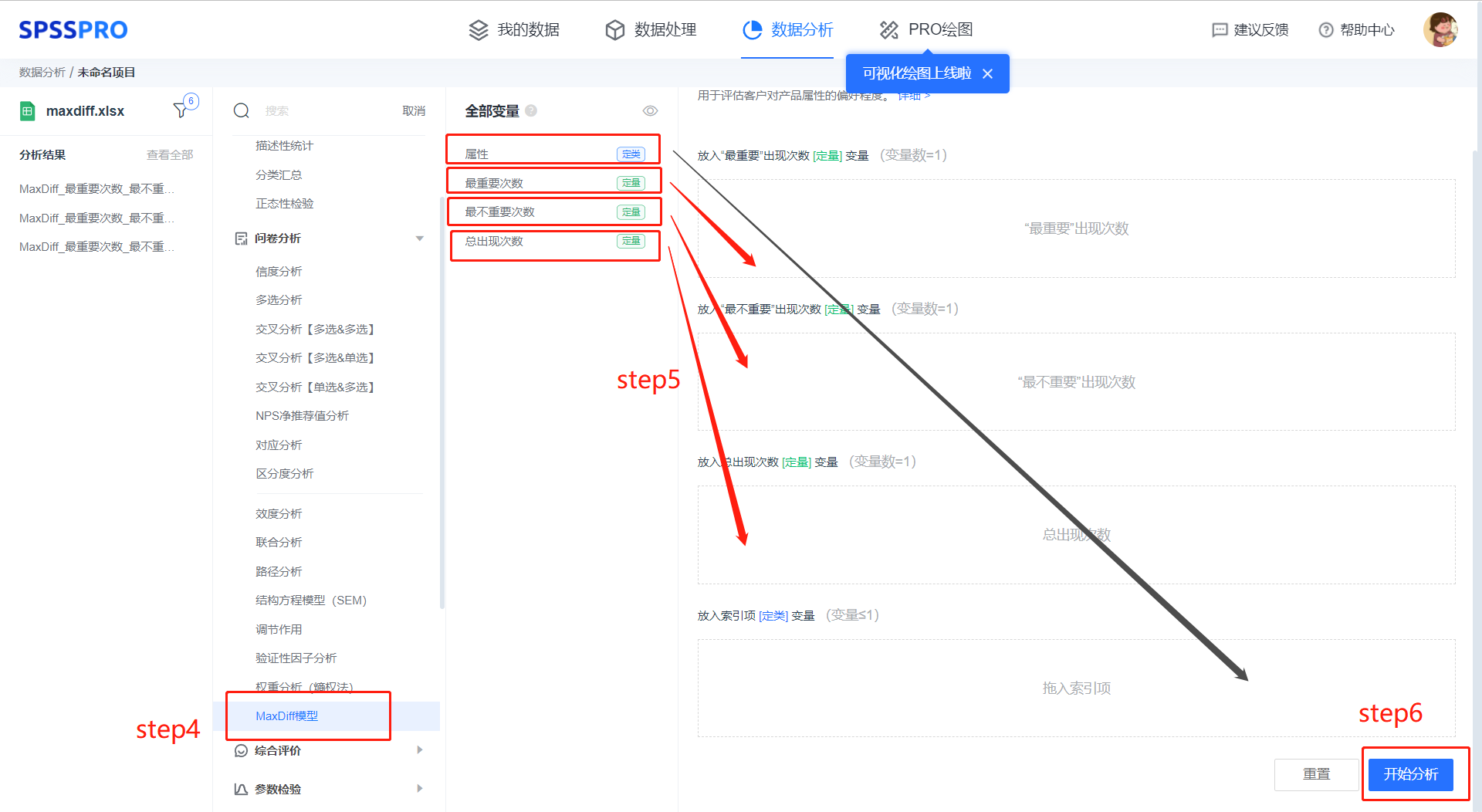
Step4:选择【MaxDiff模型】;
Step5:查看对应的数据数据格式,按要求拖入数据。
Step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果1:Maxdiff 属性估计结果 
图表说明:上表格展示了 Maxdiff 属性结果及偏好份额,包括效用系数、标准误差、统计量、p 值、偏好份额等,用于评估用户对属性的偏好。
● 效用系数:正分意味着该属性被选为最重要的次数多于最不重要的次数;负分意味着该属性被选为最不重要的次数比最重要的次数要多。
● 偏好份额:直观展现了各个属性的重要性程度,值越大说明该属性越重要。
结果分析:由上表可知,味道的偏好份额为29.749%,价格的偏好份额为21.77%,分量的偏好份额为11.012%,营养的偏好份额为18.11%,能量的偏好份额为12.12%,包装的偏好份额为7.239%;这说明用户最看重属性味道,最不看重属性包装。
输出结果 2:属性偏好程度
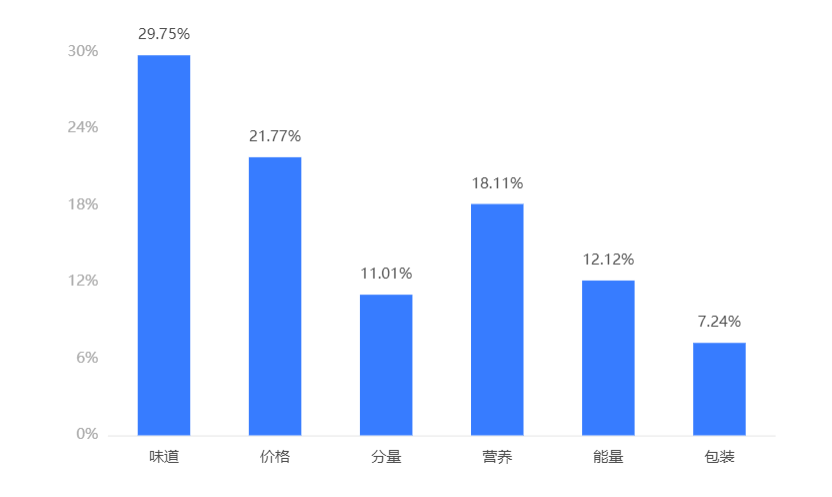
图表说明:上图展示了属性的偏好程度。
# 7、注意事项
- 进行 MaxDiff 模型的分析数据是需要根据 Maxdiff 的要求定制的,MaxDiff 要求受访者在每一次任务中选出"最重要属性"与"最不重要属性"。
- 拖入 SPSSPRO 进行运算的数据是对所有问卷结果进行基本汇总得到的。
# 8、模型理论
MaxDiff 模型是通过多项式逻辑回归的解析估计得到各个属性的回归系数(效用系数)
MaxDiff 主要是得到各属性的偏好份额,可以通过以下公式得到:
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] Lipovetsky S , Conklin M . Best-Worst Scaling in analytical closed-form solution[J]. Journal of Choice Modelling, 2014, 10(1):60-68.