Yates校正卡方检验
# 1、作用
卡方检验主要是比较定类变量与定类变量之间的差异性分析。当用皮尔森卡方检验做独立性检验时,若任何一个字段的期望次数小于 5,会使“近似于卡方分配”的假设不可信,统计值会系统性地偏高,导致过度地拒绝虚无假设。此时可以做叶氏连续性校正(Yates's correction for continuity)。
校正的目的:是在小样本情况下,降低将离散型频数数据近似到连续性卡方统计量的过程中的误差。
# 2、输入输出描述
输入:一个定类变量 X(如班级字段,包括 A、B)与定类变量 Y(如 A 班级 28 名学生与 B 班级 14 名学生的成绩)。
输出:模型输出的检验结果,如 A 与 B 班级的学生成绩存在/不存在显著性差异。
# 3、案例示例
从某高中学随机抽取两班级,调查考试成绩是否有显著差异。
# 4、案例数据
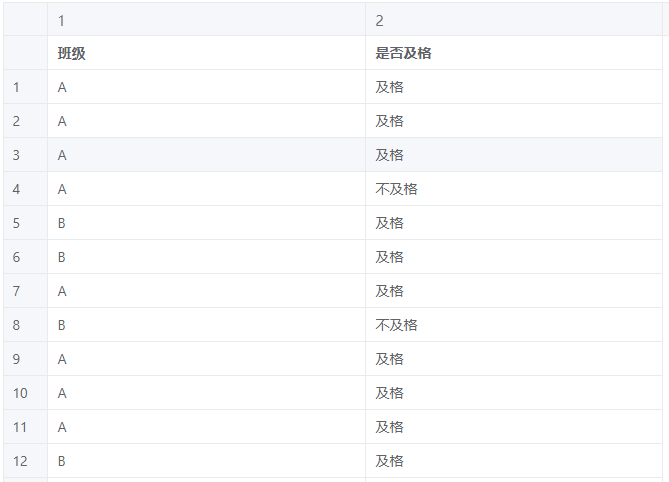
Yates校正卡方检验案例数据
# 5、案例操作
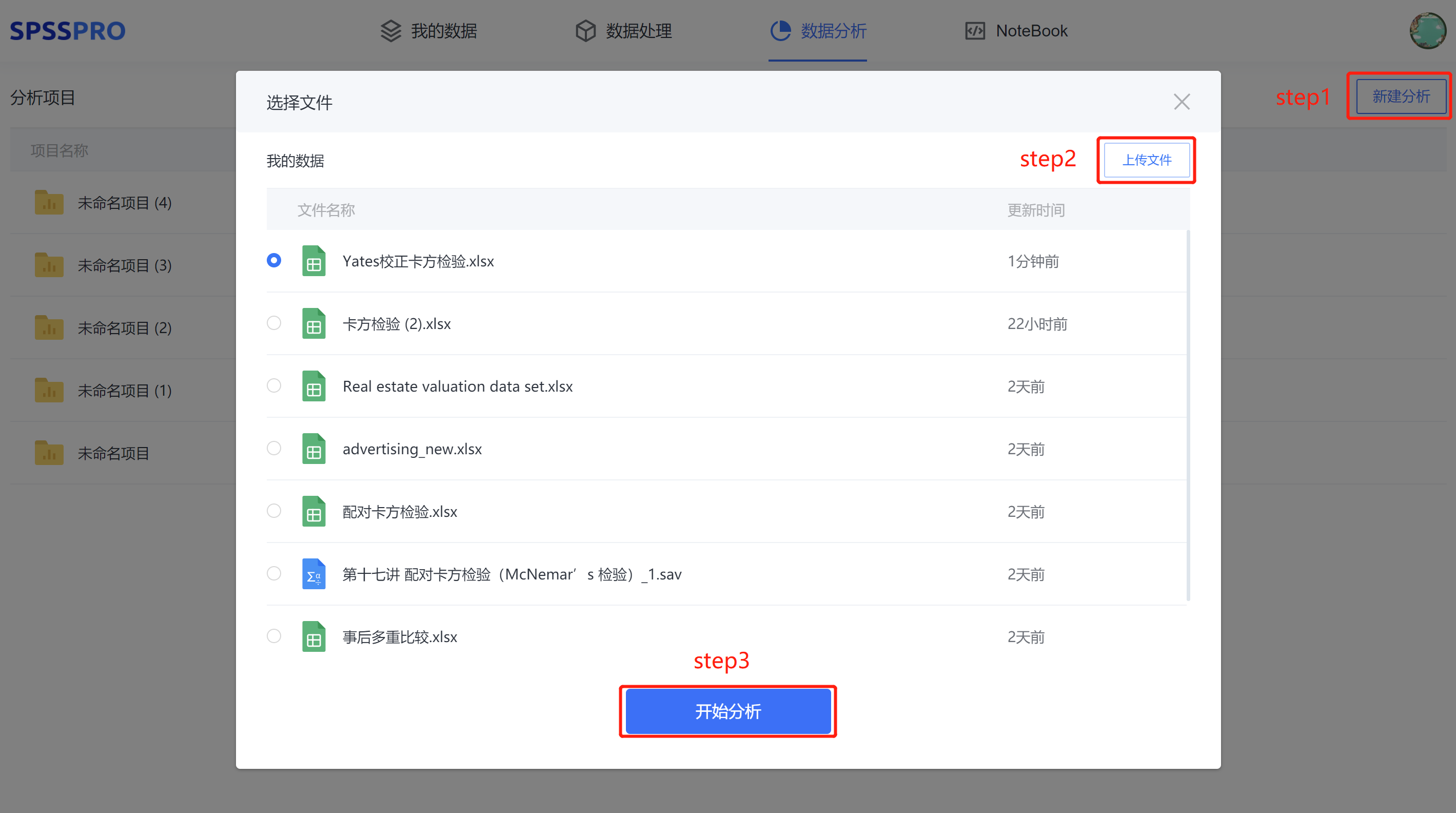
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析; 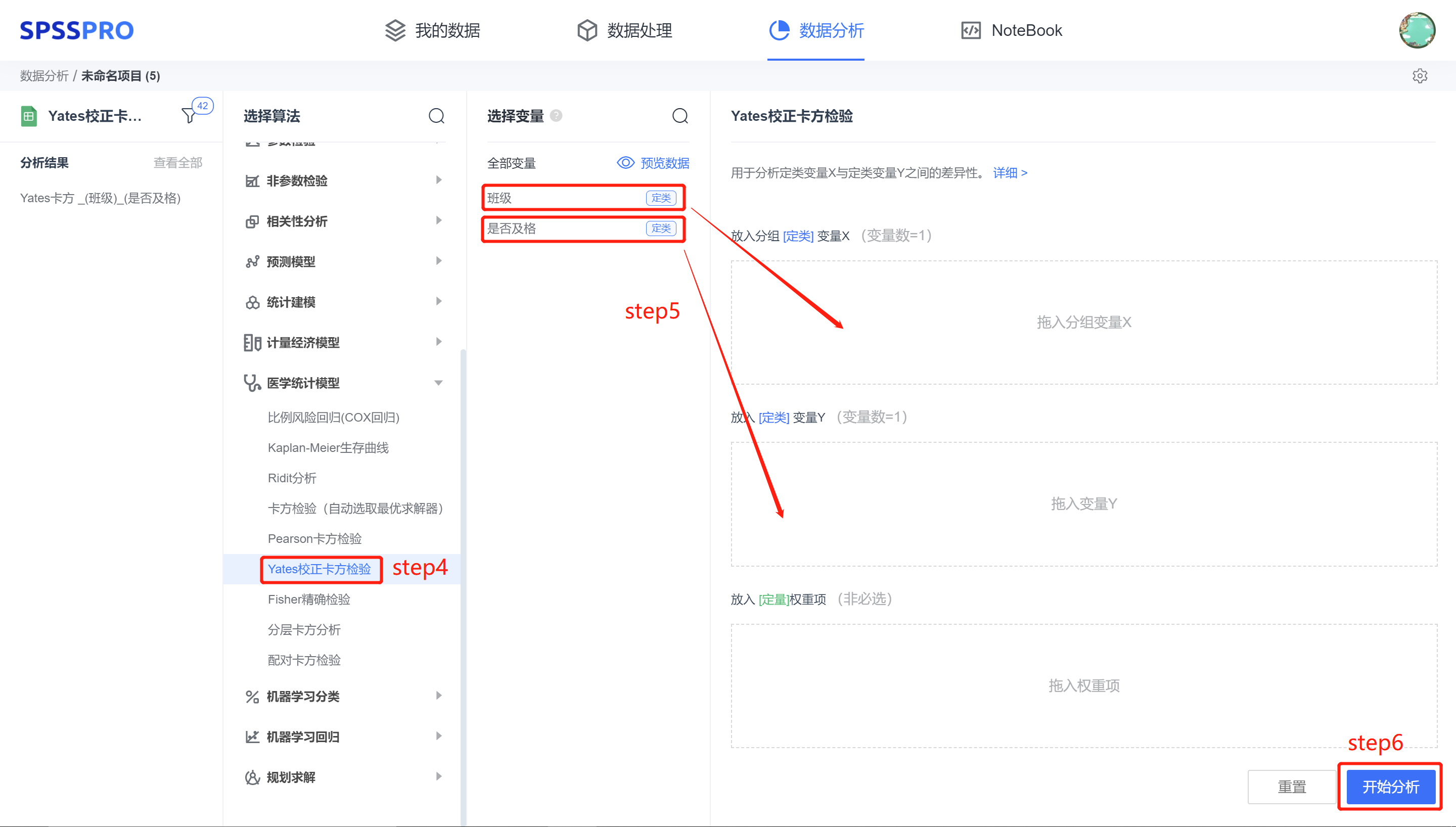
step4:选择【Yates 校正卡方检验】;
step5:查看对应的数据数据格式,按要求输入【Yates 校正卡方检验】数据;
step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:Yates 校正卡方检验结果
| 题目 | 名称 | 班级 | 合计 | 卡方值 | p 值 | |
|---|---|---|---|---|---|---|
| A | B | |||||
| 成绩 | 不及格 | 2 | 5 | 7 | 3.621 | 0.057* |
| 及格 | 26 | 9 | 35 | |||
| 合计 | 28 | 14 | 42 |
注:*、**、*分别代表 1%、5%、10%的显著性水平
图表说明:上表展示了 Yates 校正卡方检验的结果,包括数据的频数、卡方值、显著性 P 值。
● 若 p<0.05,呈现显著性,拒绝原假设,则说明分类变量 X 与分类变量 Y 之间存在显著性差异。
● 若 p>=0.05,不呈现显著性,接受原假设,则说明分类变量 X 与分类变量 Y 之间不存在显著性差异。
分析:Yates 校正卡方检验分析的结果显示,显著性 P 值为 0.057*,水平上不呈现显著性,不能拒绝原假设,因此班级和是否及格数据不存在显著性差异。
输出结果 2:交叉列联表热力图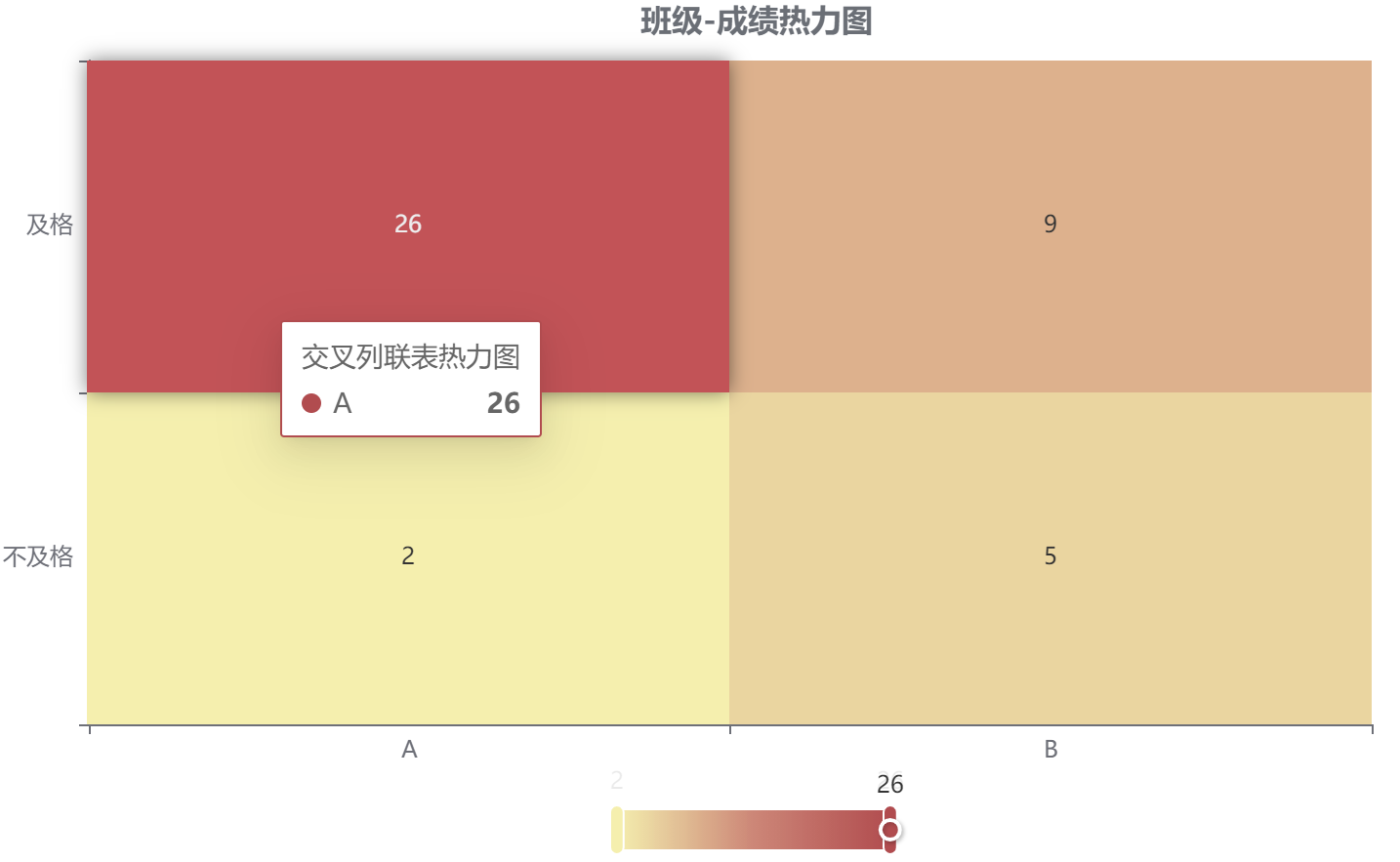
图表说明:上图展示了热力图的形式展示了交叉列联表的值,主要通过颜色深浅去表示值的大小。
输出结果 3:效应量化分析
| 字段名/分析项 | Phi | Crammer‘s V | 列联系数 | lambda |
|---|---|---|---|---|
| 成绩-班级 | 0.294 | 0.294 | 0.282 | 0 |
图表说明:上表展示了效应量化分析的结果,包括 phi、Crammer's V、列联系数、lambda ,用于分析样本的相关程度。
- 当呈现出显著性差异(前提),结合分析效应量指标对差异性进行量化分析;
- 效应量化指标反映的是变量之间的相关程度;
- 根据交叉类型的不同,可以选用不同的效应量指标。(交叉类型表示:交叉表横向格子数 × 纵向格子数);
- phi 系数: phi 相关系数的大小,表示两样本之间的关联程度。当 phi 系数小于 0.3 时,表示相关较弱;当 phi 系数大于 0.6 时,表示相关较强。(用于 2×2 交叉类型表);
- Cramer's V: 与 phi 系数作用相似,但 Cramer's V 系数的作用范围较广。当两个变量相互独立时,V=0,当数据中只有 2 个二分类变量时,Cramer's V 系数的结果与 phi 相同(若 m≠n,建议使用 Cramer's V );
- 列联系数:简称 C 系数,用于 3×3 或 4×4 交叉表,但其受行列数的影响,随着 R 和 C 的增大而增大。因此根据不同的行列和计算的列联系数不便于比较,除非两个列联表中行数和列数一致;
- lambda:用于反应自变量对因变量的预测效果,一般情况下,其值为 1 时表示自变量预测因变量效果较好,为 0 时表明自变量预测因变量较差(X 或 Y 有定序数据时,建议使用 lambda)。
分析:效应量化分析的结果显示,分析项:成绩 Cramer's V 值为 0.294,因此班级和成绩的差异程度为中等程度差异。
# 7、注意事项
- 一般优先考虑皮尔森卡方检验,当 n ≥40,T(理论频数) ≥ 5,用 Pearson 统计量
- 当 n≥40 时,如果某个格子出现 1≤ T ≤5,则需作叶氏连续性校正
- 当 n<40,或任何格子出现 T<1,或检验所得的 P 值接近于检验水准
,采用 Fisher 精确检验
# 8、模型理论
1.简介
当用皮尔森卡方检验做独立性检验时,若任何一个字段的期望次数小于 5,会使“近似于卡方分配”的假设不可信,统计值会系统性地偏高,导致过度地拒绝虚无假设,此时可以做叶氏连续性校正。
2.校正
在满足 Yates 校正的条件下,将每个观察值的离差减去 0.5 之后再做平方,如下:
3.总结
分布是一连续型分布,而四格表资料属离散型分布,由此计算得的统计量的抽样分布亦呈离散性质。为改善统计量分布的连续性,则进行连续性校正。
当 n≥40 时,如果某个格子出现 1≤ T ≤5,作连续性校正。
当 n<40,或任何格子出现 T<1,或检验所得的 P 值接近于检验水准 a,采用 Fisher 确切概率检验。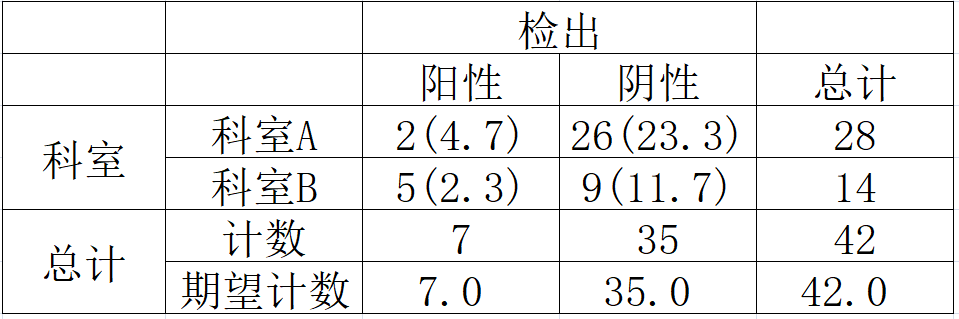 频数")
频数")
如上表例子,A,B 两个科室检查癌症的情况,满足 n≥40,且出现理论频数 1 ≤ T ≤ 5,则作 Yates 连续性校正。
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]方积乾.生物医学研究的统计方法[M].高等教育出版社:北京,2007:138-139.
[3]Greenwood, P. (1996).A Guide to Chi-Squared Testing (Wiley Series in Probability and Statistics)1st Edition. Wiley Interscience.