Ridit分析
# 1、作用
用于考察定类变量与有序定类变量之间的差异性。常用于医学研究中,如研究两三种药物对疗效的差异性。其中疗效分为(痊愈、显效、有效、无效),用卡方检验只能反映药物与疗效之间是否有差异,当出现差异性时,无法进一步比较各药物的疗效水平情况。
# 2、输入输出描述
输入:一个分组定类变量 X(如药物,包括甲药物、乙药物、丙药物)与有序定类变量 Y(如药物的疗效等级,包括痊愈、显效、有效、无效)。
输出:分组定类变量与有序(等级)定类变量之间是否存在差异性,以及各分组的平均等级情况。
# 3、案例示例
案例:根据三种药物对于疾病的疗效情况,来分析三种药物的疗效是否有显著差异。本例中以编码的形式给疗效变量的水平进行排序--无效(1)、有效(2)、显效(3)、痊愈(4)。
# 4、案例数据
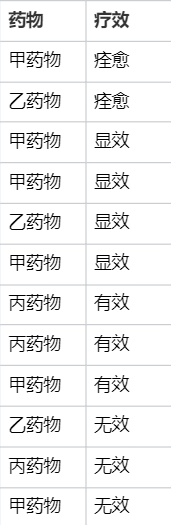
Ridit 分析案例数据
# 5、案例操作
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
step4:选择【Ridit 分析】;
step5:查看对应的数据数据格式,拖入对应的选项;
step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:数据汇总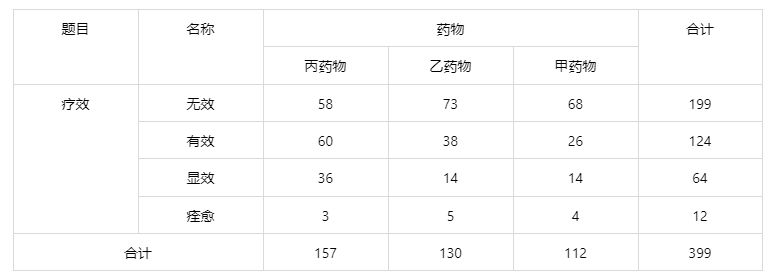
图表说明:上表以列联表的形式对分组定类变量和有序定类变量进行汇总。
输出结果 2:Ridit 分析结果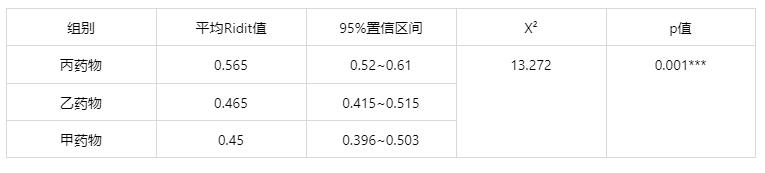
图表说明:首先,卡方检验分析的结果显示,显著性 p 值为 0.001***,水平上呈现显著性,拒绝原假设,因此药物对于疗效存在显著性差异。
其次,通过对比三种药物的平均 Ridit 值来判断哪种药物是最佳的。本例中给疗效变量的水平进行排序--无效(1)、有效(2)、显效(3)、痊愈(4),是由劣到优排序,Ridit 值越大越好,丙药物的平均 Ridit 值最大,说明丙药物的疗效是最佳的。
输出结果 3:Ridit 箱线图分析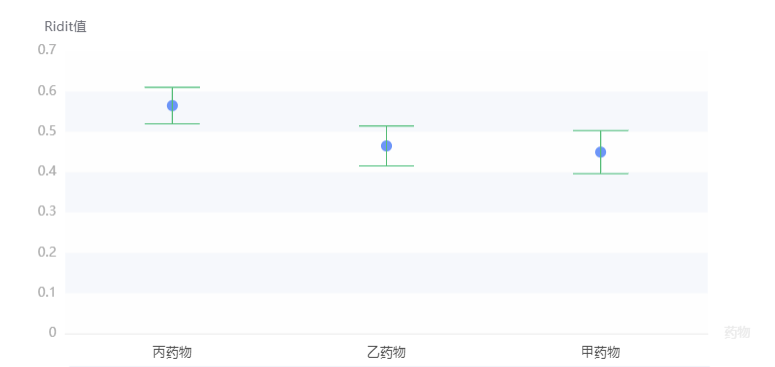
图表说明:当上述分析结果显示分组定类变量 X 对于有序定类变量 Y 出现显著性差异时,可通过该图来对比各组具体的差异情况。
● 每组别的中间的圆点,是 Ridit 值的均值,代表了组别的 Ridit 值平均水平。
● 每组别的上、下方,各有一条线,分别代表着组别的 Ridit 值的 95%置信区间上限、95%置信区间上限。
本例中给疗效变量的水平进行排序--无效(1)、有效(2)、显效(3)、痊愈(4),是由劣到优排序,Ridit 值越大越好,所以由图可以直观发现,丙药物的疗效是最佳的,
# 7、注意事项
-有序定类变量要求对各分类水平进行有序编码或者直接以数值来代替各分类水平。比如收入水平,有三个分类(低、中、高),可以分别编码为 1,2,3,收入水平高为最优,是由劣到优排序,Ridit 值越大越好。比如获奖等价,有三个分类(一等奖、二等奖、三等奖),可以分别编码为 1,2,3,一等奖为最优,是由优到劣排序,Ridit 值越小越好。
# 8、模型理论
Ridit 用于考察定类变量与定类有序变量之间的差异性的方法。常用于医学研究中,该方法不仅能反映变量之间是否有差异,当出现差异性时,还可以进一步比较各层次的水平情况。步骤:
(1)选择标准组。
确定标准组是 Ridit 分析的关键。常用的方法:一是以样本量最大的组作为标准组,如果存在某一组的例数特别多于其他组,可将该组选为参照组;二是当各组样本量接近时,将各组合并后作为标准组。其中后者更常用,较前者系统误差小。
(2)计算标准组的平均 Ridit 值(简写为 R 值)。
对于标准组各等级 Ridit 值, 是将各等级的频数之半与累计频数(移下一行)相加除以总例数即得到 Ridit 值。
(具体举例可参照引文【2】)
(3)利用参照组计算各组的平均 Ridit 值。![]()
(具体举例可参照引文【2】)
(4)判断结论。
对于由劣到优排序的有序分类变量,Ridit 值越大越好;对于由优到劣排序的有序分类变量,Ridit 值越小越好。比如收入水平,有三个分类(低、中、高),可以分别编码为 1,2,3,收入水平高为最优,是由劣到优排序,Ridit 值越大越好。比如获奖等价,有三个分类(一等奖、二等奖、三等奖),可以分别编码为 1,2,3,一等奖为最优,是由优到劣排序,Ridit 值越小越好。
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]贾贵玉,王士珍. Ridit 法在病历质量评价中的应用[J]. 中国医院统计,2012,19(1):21-22. DOI:10.3969/j.issn.1006-5253.2012.01.008.