模糊综合评价
# 模糊综合评价
# 1、作用
模糊综合评价借助模糊数学的一些概念,对实际的综合评价问题提供评价,即模糊综合评价以模糊数学为基础,应用模糊关系合成原理,将一些边界不清、不易定量的因素定量化,进而进行综合性评价的一种方法。
# 2、输入输出描述
输入:至少两项或以上的定量变量。
输出:反应考核指标在量化评价中的综合得分。
# 3、案例示例
案例:某饮食行业品牌发布一款新零食,欲了解消费者对该种零食的接受程度。一共有五个评价指标(分别是价格、味道、包装、营养与性价比),以及评语共有四项(分别是很欢迎,欢迎,一般,不欢迎)。
# 4、案例数据
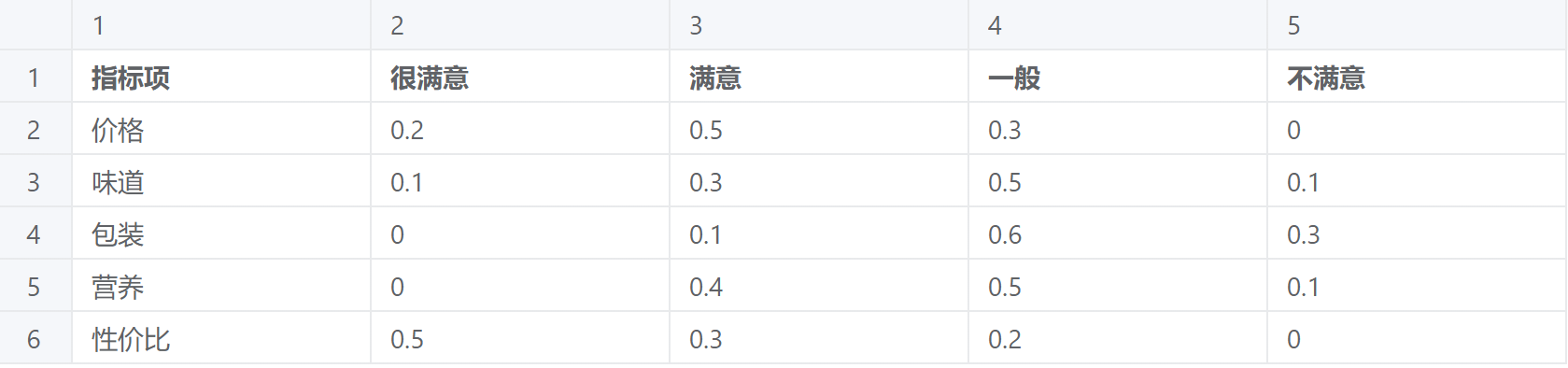
模糊综合评价案例数据
# 5、案例操作
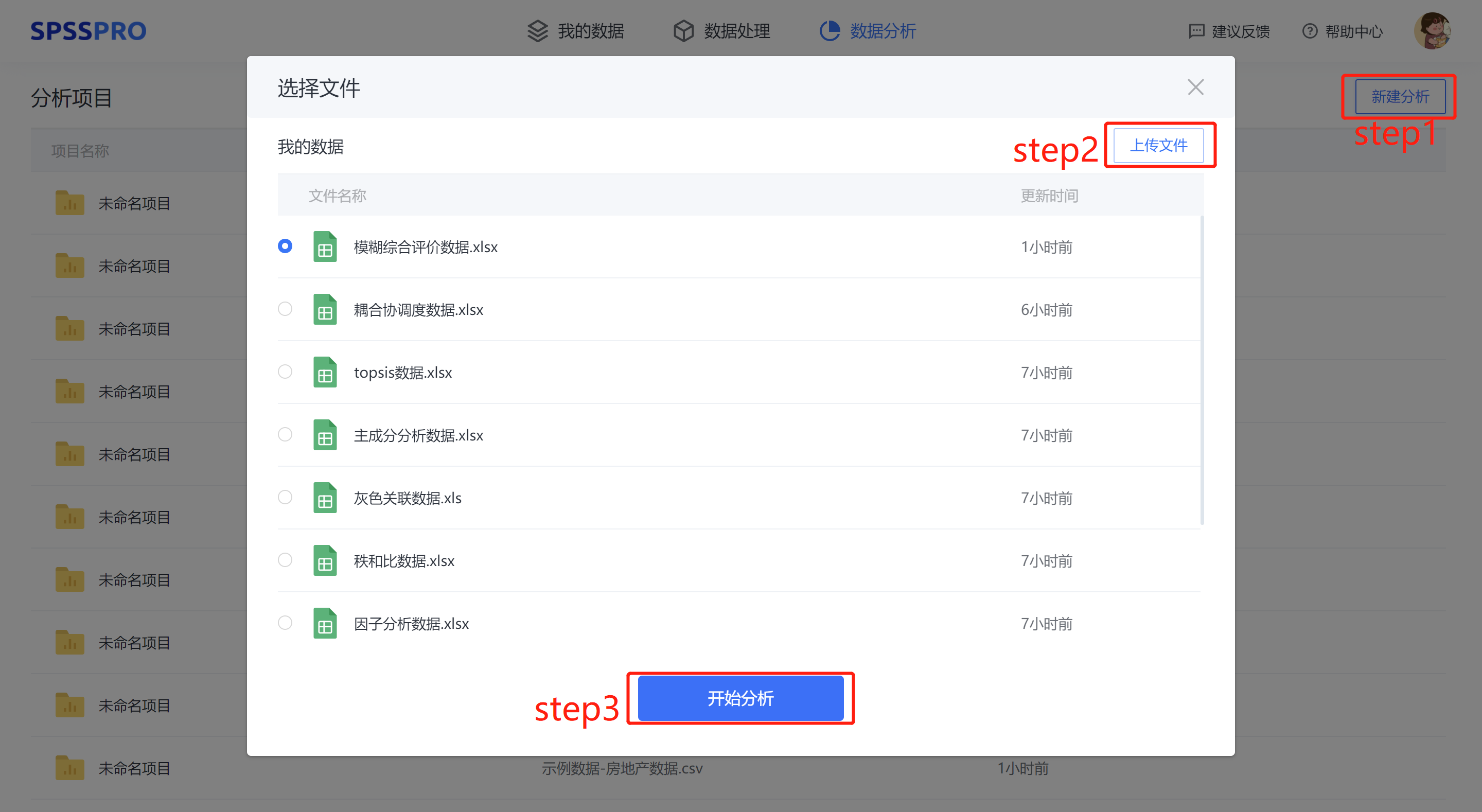
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;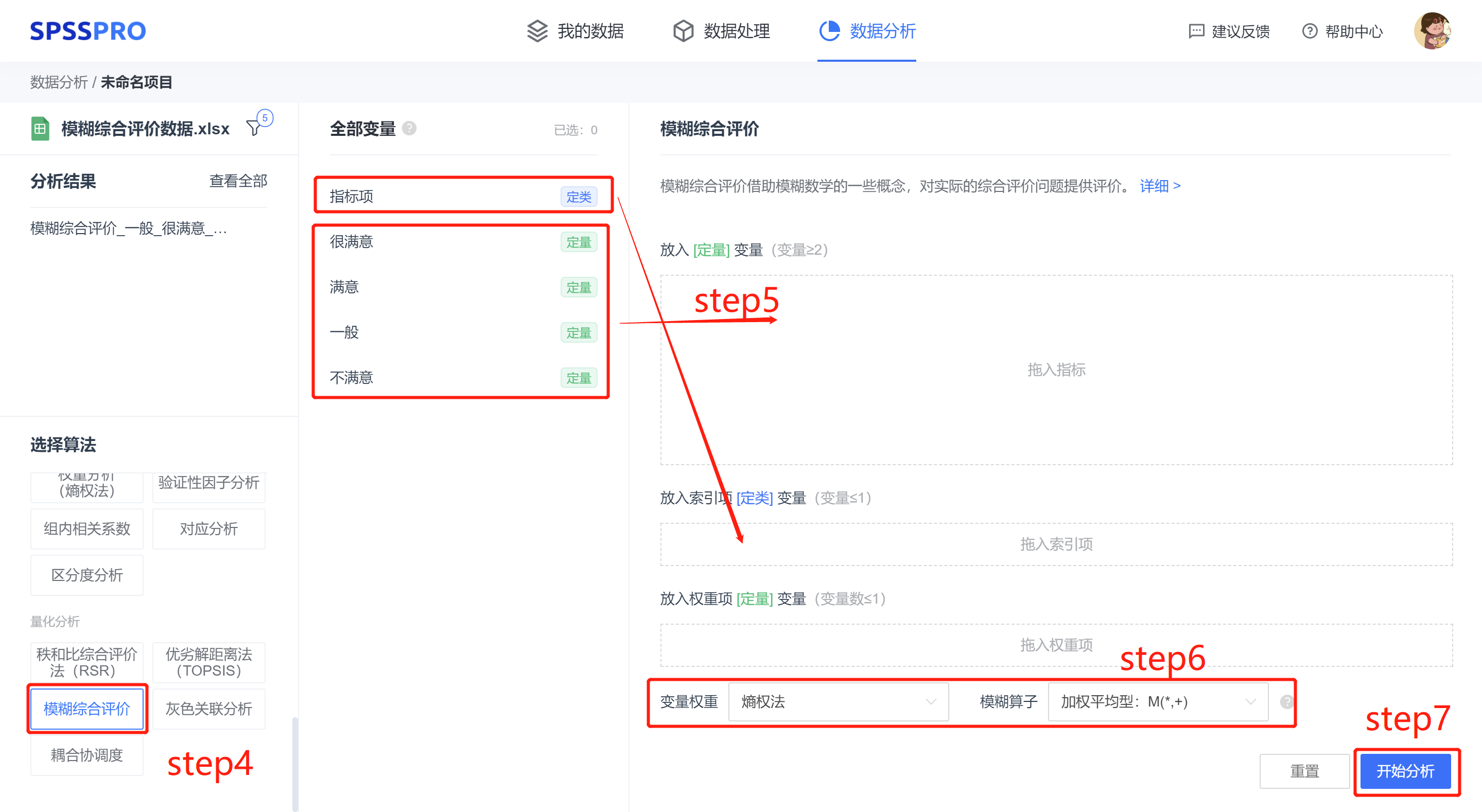
step4:选择【模糊综合评价】;
step5:查看对应的数据数据格式,【模糊综合评价】求输入数据为放入 [定量] 自变量 X(变量数 ≥2)。
step6:设置变量权重(熵权法、不设置权重)、模糊算子(主因素决定型、主因素突出型、取小与有界型、加权平均型)。
step7:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:指标权重计算 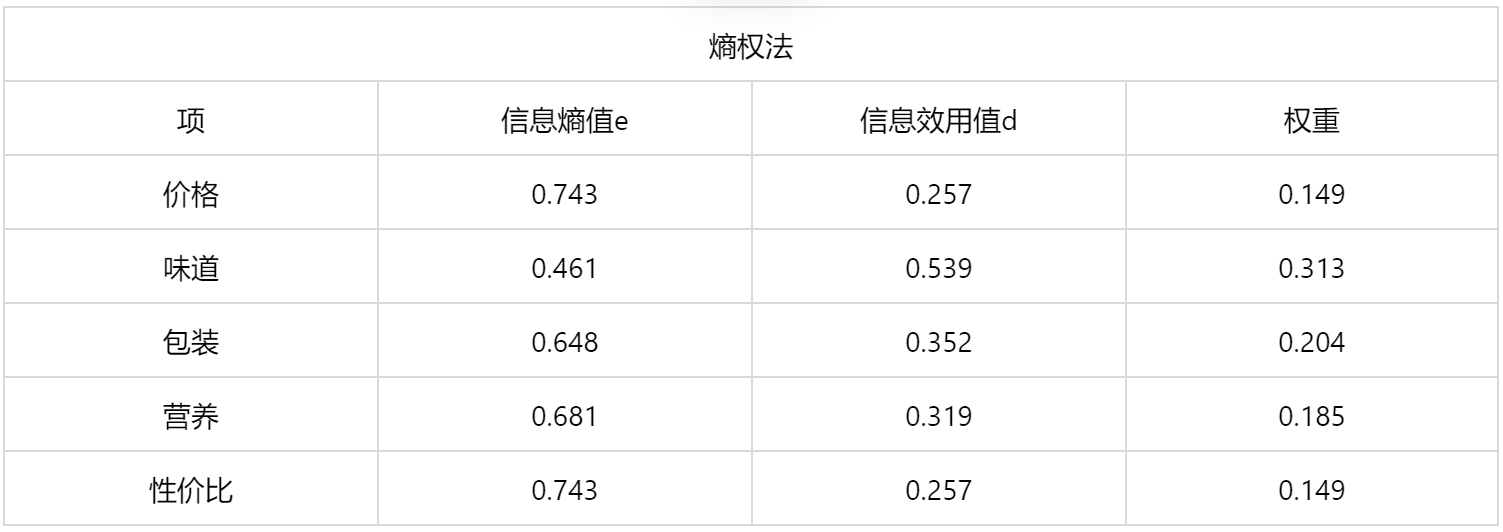
图表说明:熵权法的权重计算结果显示,价格的权重为 14.899%、味道的权重为 31.279%、包装的权重为 20.412%、营养的权重为 18.511%、性价比的权重为 14.899%,其中指标权重最大值为味道(31.279%),最小值为价格(14.899%)。
输出结果 2:隶属度矩阵计算结果
| 很满意 | 满意 | 一般 | 不满意 | |
|---|---|---|---|---|
| 隶属度 | 0.1355 | 0.3074 | 0.4459 | 0.1110 |
| 隶属度归一化【权重】 | 0.136 | 0.307 | 0.446 | 0.111 |
图表说明:由上表可知,针对 5 个指标(价格、味道、包装、营养、性价比)与 4 个评语(很满意、满意、一般、不满意)进行模糊综合评价,在使用加权平均型 M(*,+)算子进行研究; 首先由评价指标权重向量 A(由熵权法可以得到),通过构建出 5X4 的权重判断矩阵 R,最终进行分析得到 4 个评语集隶属度,分别为 0.136、0.307、0.446、0.111,因此可以得到,4 个评语集中一般的权重最高,集合最大隶属度法则可以得到,最终综合评价的结果为“一般”
输出结果 3:综合得分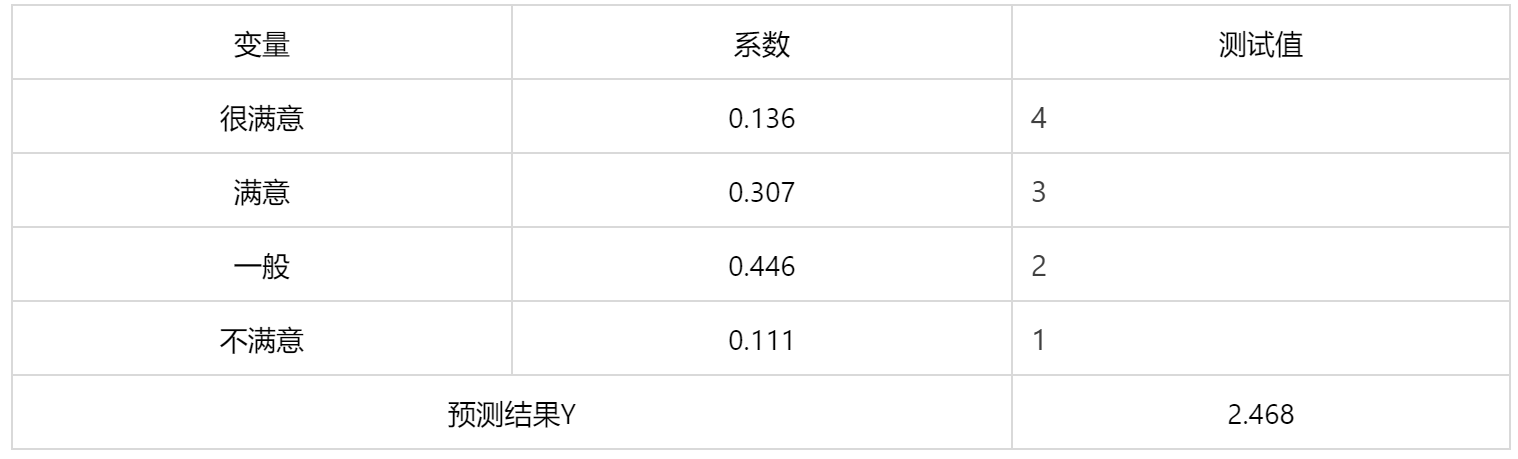
图表说明:我们还可以对评价结果可以进一步处理。规定(很满意,满意,一般,不满意)所代表的分数为(4,3,2,1)分;通过 0.136×4+0.307×3+0.446×2+0.111×1=2.468,计算得出综合得分值是 2.468 分,说明综合得分介于“满意”和“一般”之间。
# 7、注意事项
- SPSSPRO 模糊综合评价里的指标是按行形式的,评语集是按列形式的;
- 模糊综合评价是一种综合评价方法,其涉及到 4 个关键术语名词,分别是:指标项、评语、权重判断矩阵、权重向量矩阵,分别如下说明:
指标项:比如对于新零食在价格、味道、包装、营养与性价比 5 个方面的满意程度;
评语:指标项的“选项”,比如很欢迎,欢迎,一般,不欢迎等;模糊综合评价即用来判断最终到底应该属于那个评语项;
权重判断矩阵:指标项及各评语的选择频数(或者比例),即需要上传的原始数据;
权重向量矩阵:如果价格、味道、包装、营养与性价比 5 个方面满意度的权重不一样,则需要设置,如果权重一样则不需要处理。
- 模糊综合评价时,首先会计算出权重值,然后研究者可输入指标项的分值,则会得到综合得分值,其计算原理为指标项分值与权重值相乘后累加。一般情况下并不需要使用综合得分,其意义频率较低。
# 8、模型理论
模糊综合评价
步骤 1 确定评价对象的因素论域,也就是有 m 个指标,表面我们对被评价对象从哪些方面来进行评判描述。在上例中也就是(价格、味道、包装、营养、性价比)。
![]()
步骤 2 确定评语等级论域,评语集是评价者对被评价对象可能做出的各种总的评价结果组成的集合。在上例中也就是(很满意,满意,一般,不满意)。
![]()
步骤 3 建立模糊关系矩阵 R

rij 表示被评价对象从因素 ui 来看对 vi 等级模糊子集的隶属度。
步骤 4 确定评价因素的模糊权向量
为了反映各因素的重要程度,对各因素分配一个相应的权重![]() ,权重会对最终的评价结果产生一个很大的影响。
,权重会对最终的评价结果产生一个很大的影响。
步骤 5 模糊综合评价的模型为:
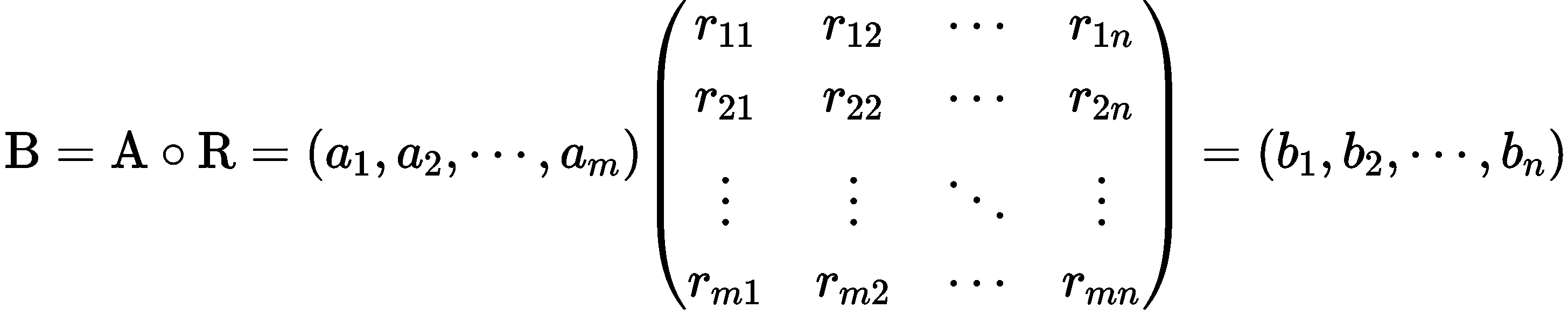
其中 bi 表示被评级对象从整体上看对 vj 等级模糊子集的隶属程度。
# 9、手推步骤
| 指标项 | 很满意 | 满意 | 一般 | 不满意 |
|---|---|---|---|---|
| 价格 | 0.2 | 0.5 | 0.3 | 0 |
| 味道 | 0.1 | 0.3 | 0.5 | 0.1 |
| 包装 | 0 | 0.1 | 0.6 | 0.3 |
| 营养 | 0 | 0.4 | 0.5 | 0.1 |
| 性价比 | 0.5 | 0.3 | 0.2 | 0 |
step1:确定评价指标与评语等级
根据案例数据可以得到:
模糊矩阵R
step2:计算权重
这里用熵权法计算权重,首先需要将数据进行归一化,这里将{价格,味道,包装,营养,性价比}都作为正向指标,归一化公式:
归一化后有
计算第i项指标下第j个样本值占该指标的比重:
计算第i项指标的熵值:
计算得到
计算信息熵冗余度:
计算得到
计算权重:
计算得到权重
step3:计算加权平均模糊算子
加权平均就是矩阵乘法:
所以评语等级的隶属度为
step4:计算综合得分
对评语等级赋值:
很满意=4,满意=3,一般=2,不满意=1
则综合得分:
# 10、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] 董春燕,周运涛,李君轶,等. 基于模糊综合评价的长江中游水质分析[J]. 淡水渔业,2021,51(2):55-62.