优劣解距离法(TOPSIS)
# 优劣解距离法(TOPSIS)
# 1、作用
TOPSIS 法是一种常用的组内综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。基本过程为基于归一化后的原始数据矩阵,采用余弦法找出有限方案中的最优方案和最劣方案,然后分别计算各评价对象与最优方案和最劣方案间的距离,获得各评价对象与最优方案的相对接近程度,以此作为评价优劣的依据。该方法对数据分布及样本含量没有严格限制,数据计算简单易行。
# 2、输入输出描述
输入:至少两项或以上的定量变量。
输出:反应考核指标在量化评价中的综合得分。
# 3、案例示例
案例:为了客观地评价各风景地点的性价比,根据风景、人文、拥挤程度、票价等因素对各风景地点进行评估。
# 4、案例数据

优劣解距离法案例数据
# 5、案例操作
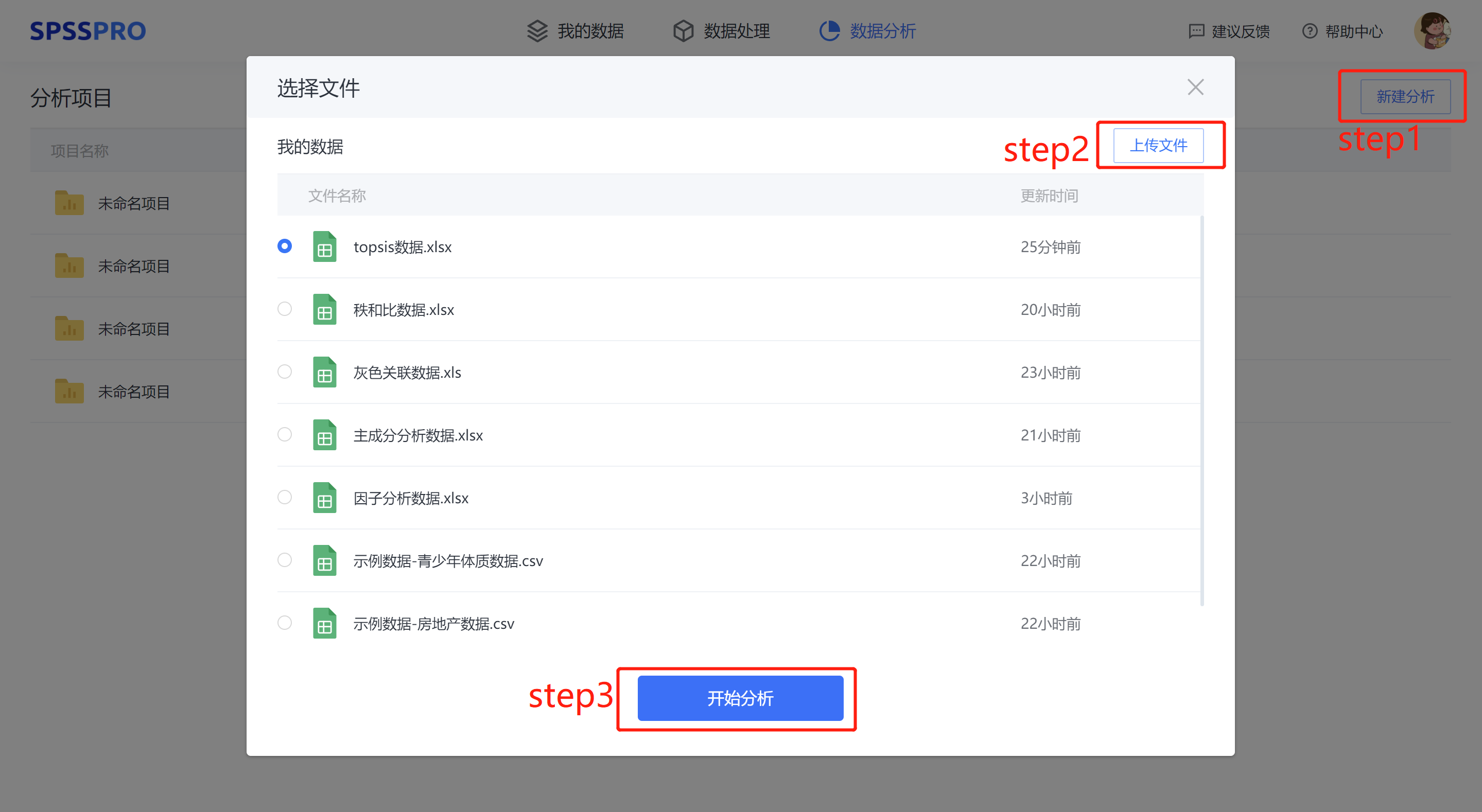
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;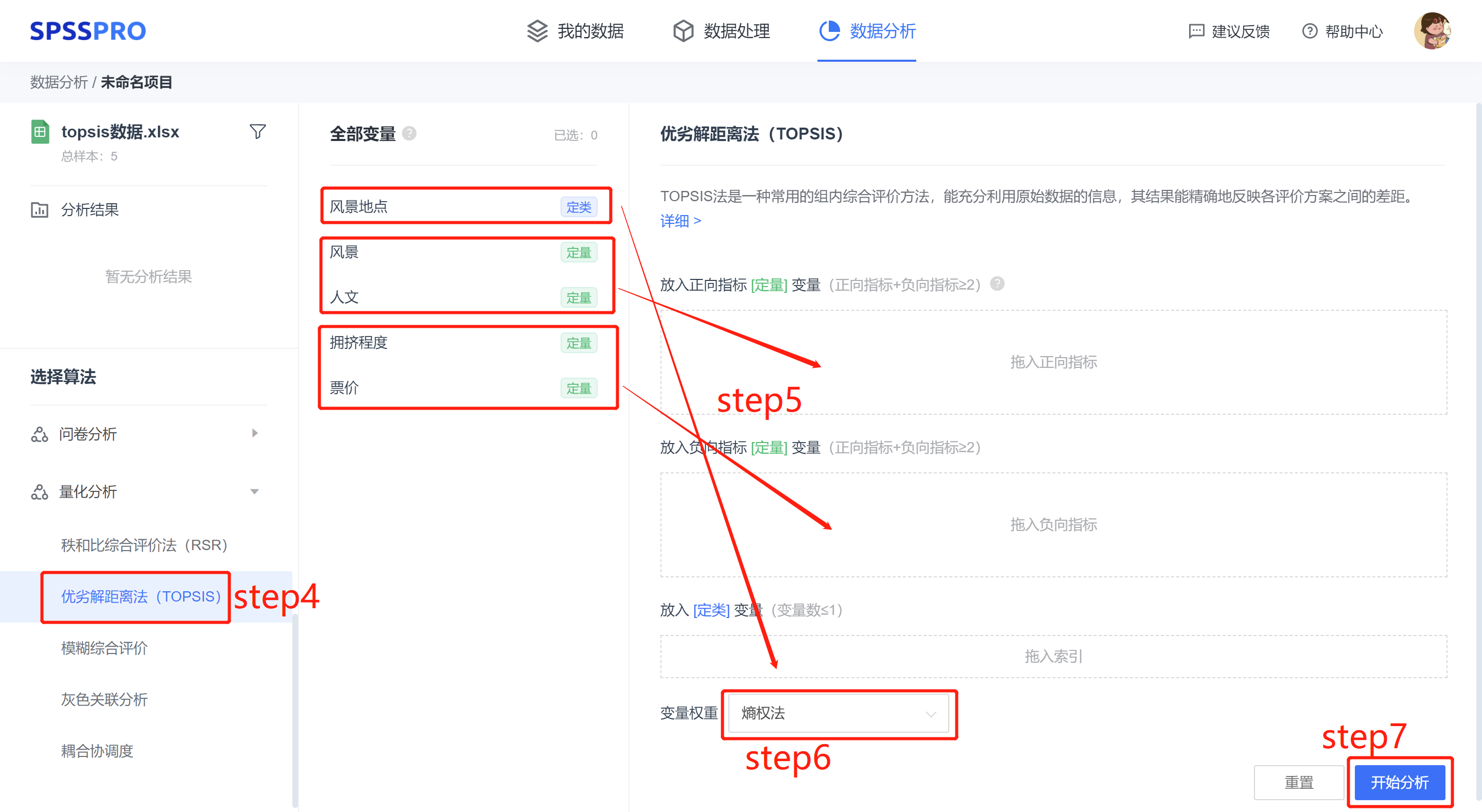
step4:选择【优劣解距离法(TOPSIS)】;
step5:查看对应的数据数据格式,【优劣解距离法(TOPSIS)】要求特征序列为定量变量,分为正向指标变量和负向指标变量,且正向指标变量和负向指标变量的个数之和大于等于两项。
step6:设置变量权重(熵权法、不设置权重)。
step7:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:指标权重计算 
图表说明:熵权法的权重计算结果显示,风景的权重为25.79%、人文的权重为22.684%、拥挤程度的权重为25.737%、票价的权重为25.79%,其中指标权重最大值为风景、票价(25.79%),最小值为人文(22.684%)。
输出结果 2:TOPSIS 评价法计算结果
| 索引值 | 正理想解距离(D+) | 负理想解距离(D-) | 综合得分指数 | 排序 |
|---|---|---|---|---|
| A | 0.58864816 | 0.73970426 | 0.55685844 | 1 |
| B | 0.68956081 | 0.46675749 | 0.40365831 | 5 |
| C | 0.55297597 | 0.48326338 | 0.4663627 | 4 |
| D | 0.58134203 | 0.66059147 | 0.53190567 | 2 |
| E | 0.63882607 | 0.61200454 | 0.48927851 | 3 |
图表说明:由上表可知,景点 A 的综合评价最高,说明综合评估风景、人文、拥挤程度、票价后,景点 A 的性价比较高,距离负理想解相对远,距离正理想解相对近。
输出结果 3:中间值展示
| 项 | 正理想解 | 负理想解 |
|---|---|---|
| 风景 | 1 | 0 |
| 人文 | 1 | 0 |
| 拥挤程度 | 1 | 0 |
| 票价 | 1 | 0 |
图表说明:表格给出的是正理想解(最优解)和负理想解(最劣解)的值。
# 7、注意事项
- 进行 TOPSIS 分析时,各个指标有着权重属性(当然通常情况并没有),那么可对应设置各个指标的权重(输入的权重值可以为相对数字,SPSSPRO 默认都会进行归一化处理让权重加和为 1),在进行 D+和 D-值计算时,SPSSPRO 会对应乘上权重值(如果没有权重则下述公式中权重值为 1);
# 8、模型理论
TOPSIS 法的基本思想是: 对原始数据同趋 势后构建归一化矩阵, 计算评价对象与最优向量和最劣向量的 差异, 以此测度评价对象的差异。 假设有 n 个评价对象,m 个 指标, TOPSIS 法的基本步骤为:
(1)步骤 1 :原始数据正向化+同趋势化
由于平台存在“正向指标”、“负向指标”,将分别对这两类数据做预处理 。这里对最小值减去0.0001,对最大值加上0.0001是为了兼容一整列都为相同的值的情况,对整体结果影响不大,可忽略不计
对于正向指标:
对于负向指标:
(2)步骤2:计算最优解和最劣解
最优解:
最劣解:
(3)步骤 3 :计算各评价指标与最优及最劣向量之间的差距
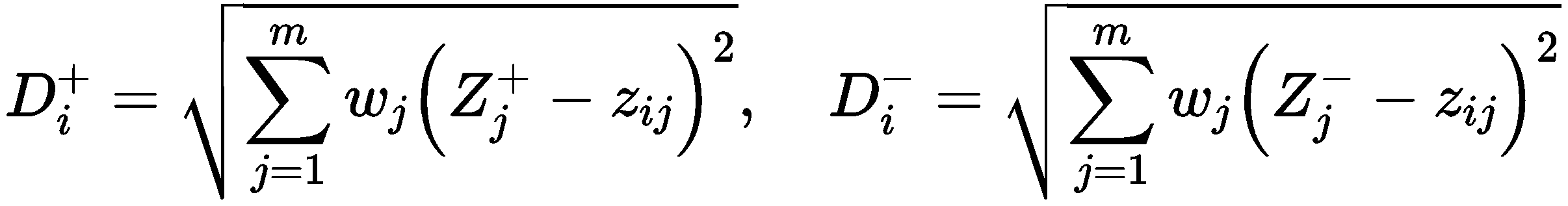
其中w_j为第 j 个属性的权重(重要程度)。
(4)步骤 4 :测度 评价对象与最优方案的接近程度
![]()
C_i 值越大, 表明评价对象越优
# 9、手推步骤
# Step 1:数据预处理:正向化与归一化
对正向指标,使用公式:
计算过程:
风景(正向指标):
,
人文(正向指标):
,
拥挤程度(负向指标):
,
票价(负向指标):
,
归一化矩阵:
| 风景地点 | 风景( | 人文( | 拥挤程度( | 票价( |
|---|---|---|---|---|
| A | 0.000025 | 0.375 | 0.9999875 | 0.999995 |
| B | 0.75 | 0.5 | 0.2500025 | 0.000005 |
| C | 0.25 | 0.625 | 0.5000025 | 0.5 |
| D | 0.5 | 0.9999875 | 0.0000125 | 0.75 |
| E | 0.999975 | 0.0000125 | 0.625 | 0.25 |
# Step 2:确定指标权重(熵权法)
计算指标概率矩阵
风景(sum=30):
人文(sum=30):
拥挤程度(sum=19.0005):
票价(sum=50.0005):
计算信息熵
风景(
):
人文(
):
拥挤程度(
):
票价(
):
计算信息效用值
| 指标 | 信息熵 | 信息效用 | 权重 |
|---|---|---|---|
| 风景 | 0.795 | 0.205 | |
| 人文 | 0.820 | 0.180 | |
| 拥挤程度 | 0.796 | 0.204 | |
| 票价 | 0.795 | 0.205 |
# Step 3:计算最优解与最劣解
- 最优解(正理想解)
:正向指标取归一化最大值1,负向指标取归一化最大值1(因已正向化),即 。 - 最劣解(负理想解)
:取归一化最小值0,即 。
# Step 4:计算与最优解和最劣解的距离
公式:
计算过程(以A为例):
全部结果:
| 风景地点 | ||
|---|---|---|
| A | 0.58864816 | 0.73970426 |
| B | 0.68956081 | 0.46675749 |
| C | 0.55297597 | 0.48326338 |
| D | 0.58134203 | 0.66059147 |
| E | 0.63882607 | 0.61200454 |
# Step 5:计算综合得分与排序
公式:
计算结果:
| 风景地点 | 综合得分 | 排序 |
|---|---|---|
| A | 1 | |
| B | 5 | |
| C | 4 | |
| D | 2 | |
| E | 3 |
# 10、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] Shih H S, Shyur H J, Lee E S. An extension of TOPSIS for group decision making[J]. Mathematical & Computer Modelling, 2007, 45(7):801-813.
[3] 刘浩然,汤少梁. 基于 TOPSIS 法与秩和比法的江苏省基本医疗服务均等化水平研究[J]. 中国全科医学,2016,19(7):819-823. DOI:10.3969/j.issn.1007-9572.2016.07.017.