密度聚类
操作视频
SPSSPRO教程-密度聚类 # 1、作用
密度聚类(DBSCAN)是一种无需事先指定聚类数量的聚类算法。通过不断扩展核心点的邻域,将所有密度相连的核心点划分为同一个聚类。对于边界点,如果它属于某个核心点的邻域内,但本身不是核心点,则被划分到该核心点所属的聚类中。最终,不属于任何核心点邻域的样本点被标记为噪声。
# 2、输入输出描述
输入:1个及以上的定量变量。 输出:数据样本被划分为具有区分性的类别。
# 3、案例示例
案例:假设存在二维数据集,尝试使用DBSCAN来识别其中的聚类。
# 4、案例数据
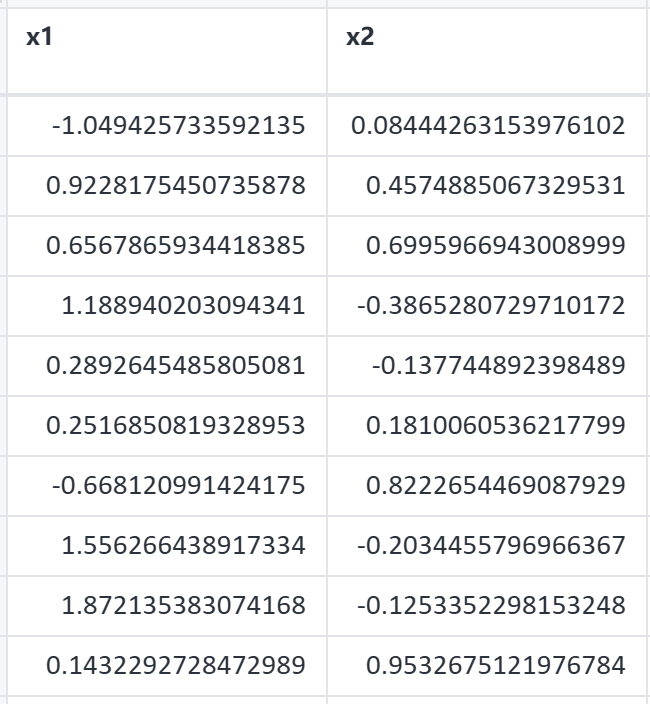
案例数据
# 5、案例操作
 Step1:新建项目;
Step1:新建项目;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
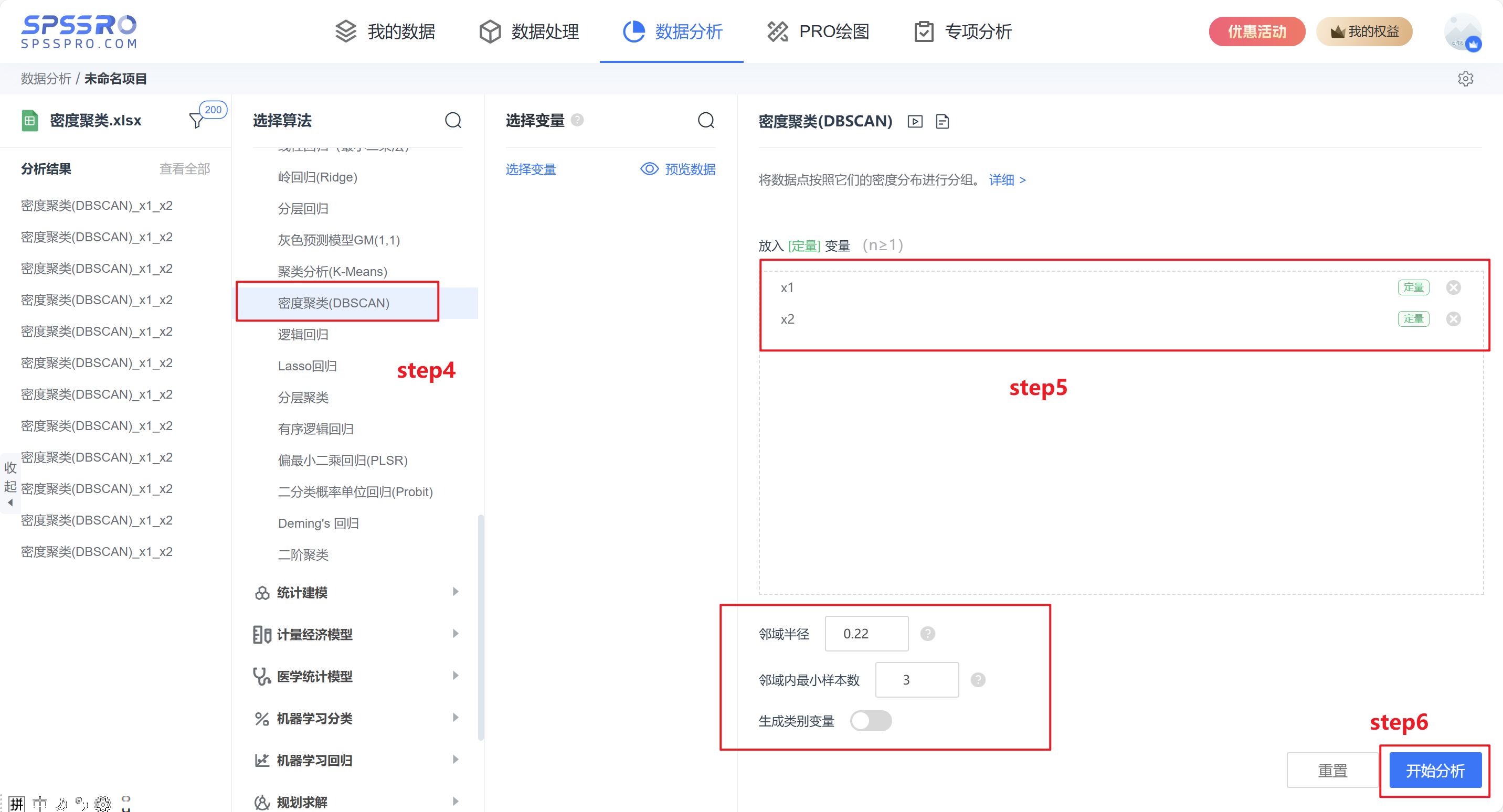 step4:选择【密度聚类(DBSCAN)】;
step4:选择【密度聚类(DBSCAN)】;
step5:选择密度聚类的相关参数;
step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果1:聚类汇总
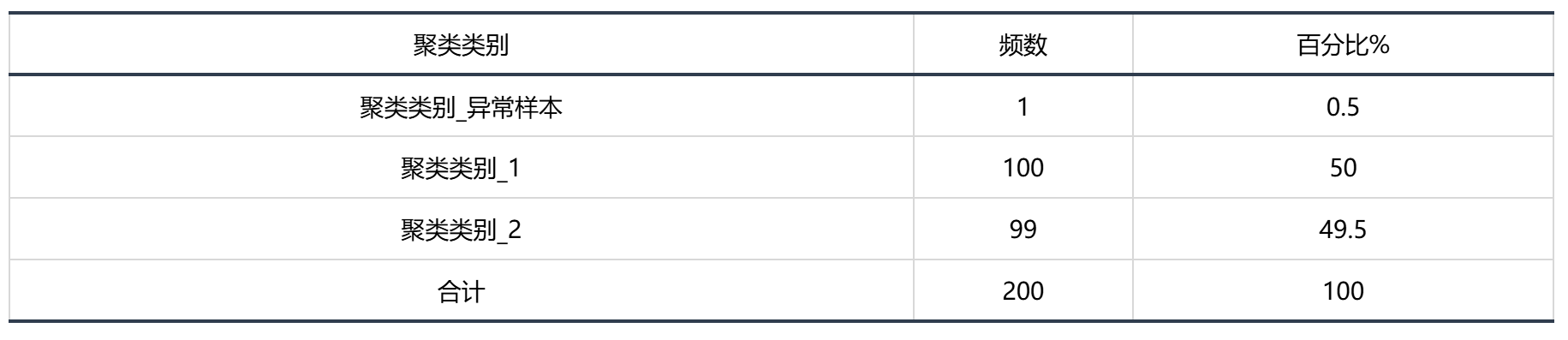
图表说明:上表展示了模型聚类的结果,包括频数,所占百分比。
输出结果2:数据集聚类标注
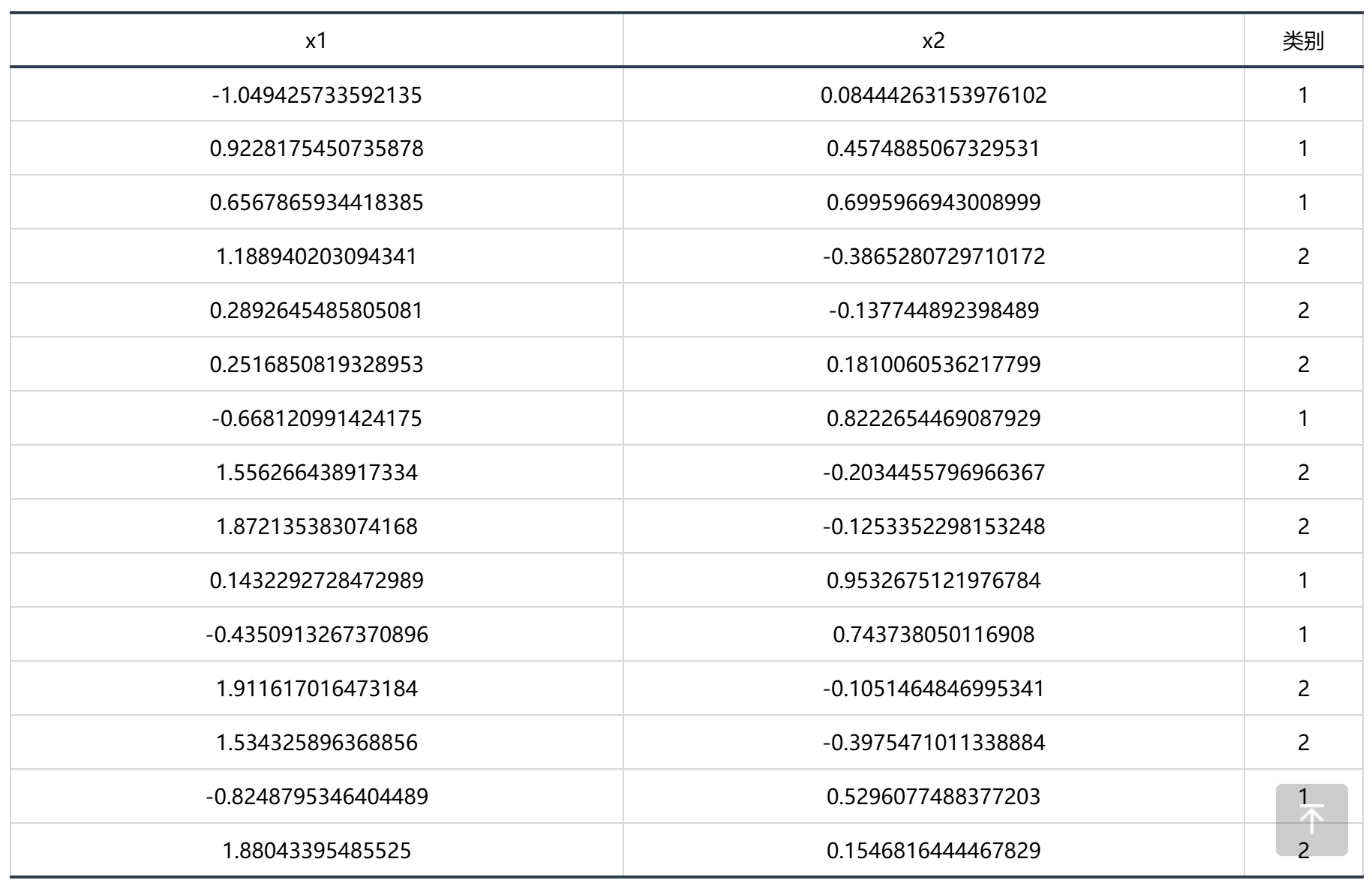
图表说明:上表展示了数据聚类的类别标注。
输出结果3:聚类散点图
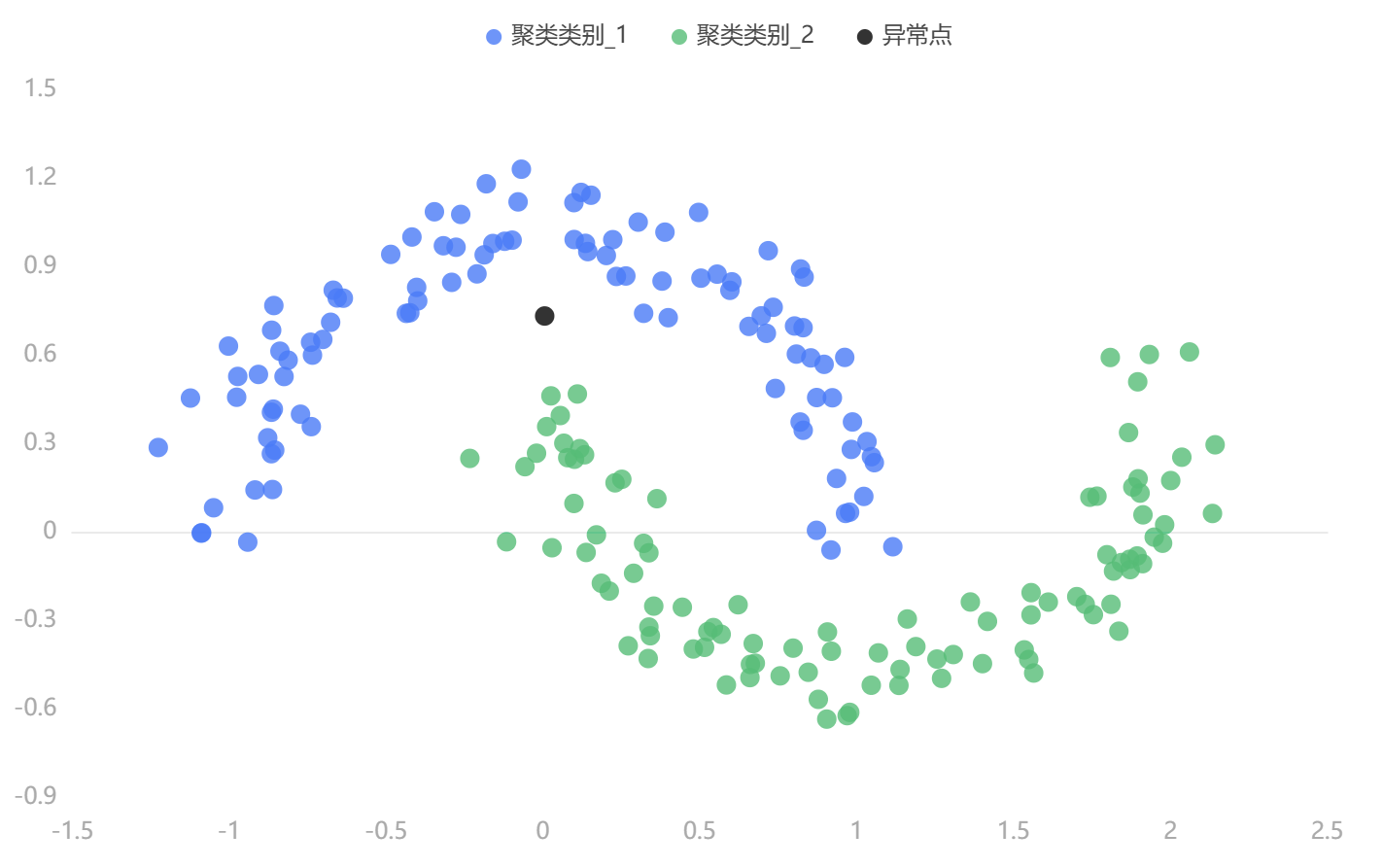
图表说明:若变量数等于两个,上图是根据两变量的数据绘制出来的散点图;若变量数大于两个,上图是t-SNE降维后前两个主成分来绘制散点图。由此图可以大致观察聚类的效果,
# 7、注意事项
- 该模型对参数很敏感,需要不断调整参数达到较好的聚类效果;
- 该模型在高维数据中表现不佳,可能面临“维度灾难”。
# 8、模型理论
DBSCAN基于“密度”的概念来定义聚类。简单来说,聚类是由密集区域中的点组成的,稀疏区域则被视为噪声。三个关键定义:
- 核心点: 如果一个点周围在指定的半径(称为ε)内,至少有一定数量(minPts)的点,那么这个点就是核心点。核心点是聚类的“中心”。
- 边界点: 如果一个点在核心点的邻域内,但自身不是核心点,那么这个点是边界点。边界点靠近核心点,但不是密集区域的中心。
- 噪声点: 如果一个点既不是核心点,也不是边界点,那么它被视为噪声点,属于离群点。
聚类过程:
- 从一个未访问的点开始,检查它是否是核心点。
- 如果是核心点,将它和周围的点归为同一聚类。
- 然后,检查周围的点,如果发现新的核心点,继续扩展聚类。
- 这个过程会一直进行,直到没有更多的核心点可以扩展为止。
- 重复以上步骤,直到所有点都被访问过。
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.