逐步回归
# 1、作用
逐步回归是以线性回归为基础的方法。其思路是将变量一个接着一个引入,并在引入一个新变量后,对已入选回归模型的旧变量逐个进行检验,将认为没有意义的变量删除,直到没有新变量引入也没有旧变量删除,从而保证回归模型中每一个变量都有意义。
# 2、输入输出描述
输入:自变量X为1个或1个以上的定类或定量变量,因变量Y为一个定量变量。
输出:变量筛选结果和模型输出的预测值及模型预测效果。
# 3、案例示例
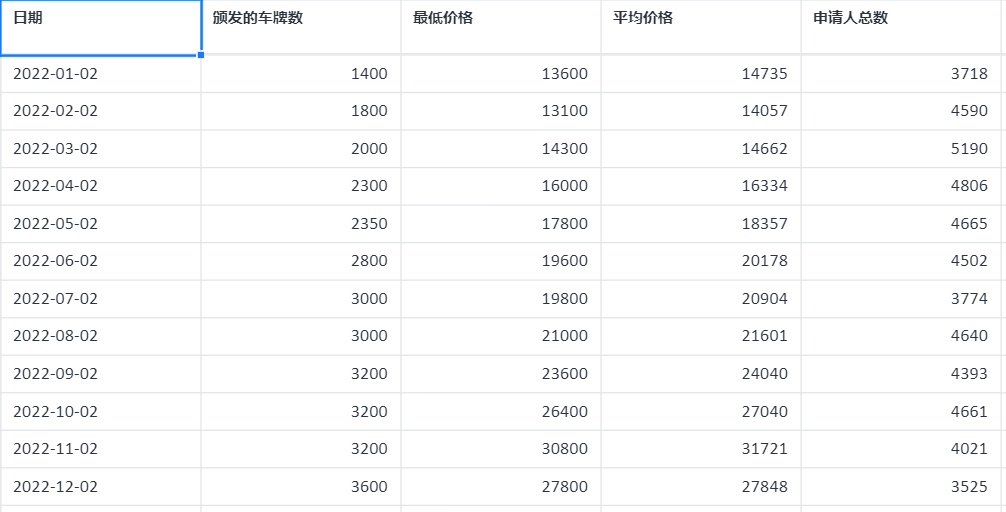
案例:上海每个月都会向化石燃料汽车购买者拍卖数量有限的车牌,在逐步回归方法中使用该月颁发的车牌数、最低价格和申请人总数预测下个月的平均价格。
# 4、案例数据
# 5、案例操作
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;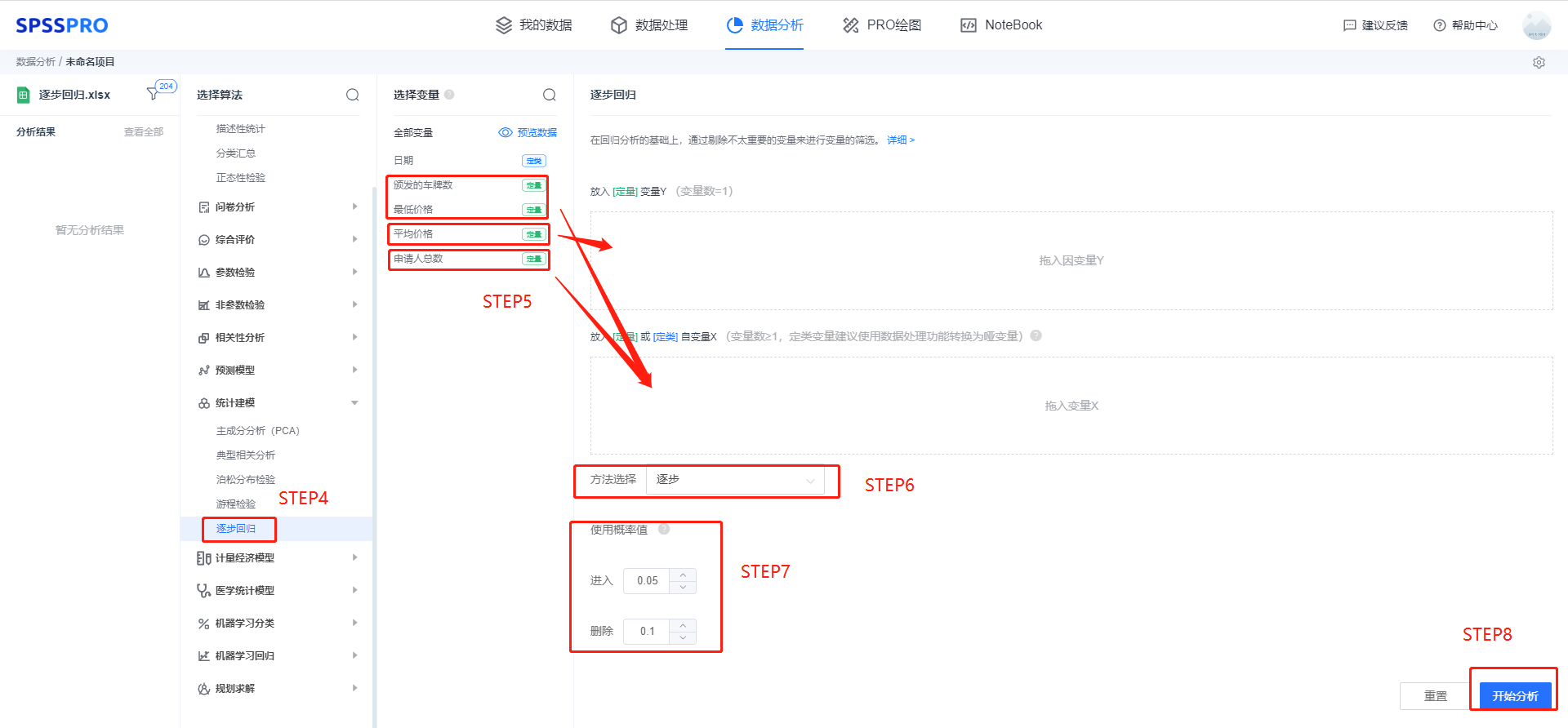
step4:选择【逐步回归】;
step5:查看对应的数据数据格式,【逐步回归】要求自变量X至少一项或以上的定量变量或二分类定类变量,因变量Y要求为定量变量。
step6:选择逐步回归的方法,本例使用逐步法;
step7:输入进入和删除的概率值,本例使用默认值;
step8:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果1:模型数据摘要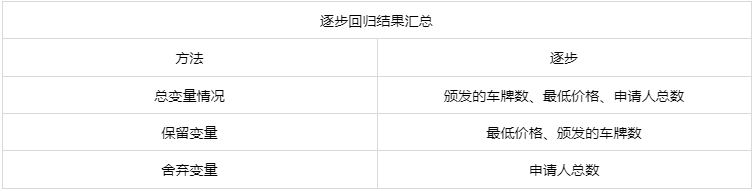
图表说明:上图展示了本次模型使用的逐步回归方法和筛选结果。
分析:一般逐步回归是用作变量筛选的,这一步的结果给出了哪些变量被舍弃,哪些变量被保留,从而关注变量的重要性。
输出结果2:逐步回归模型结果表 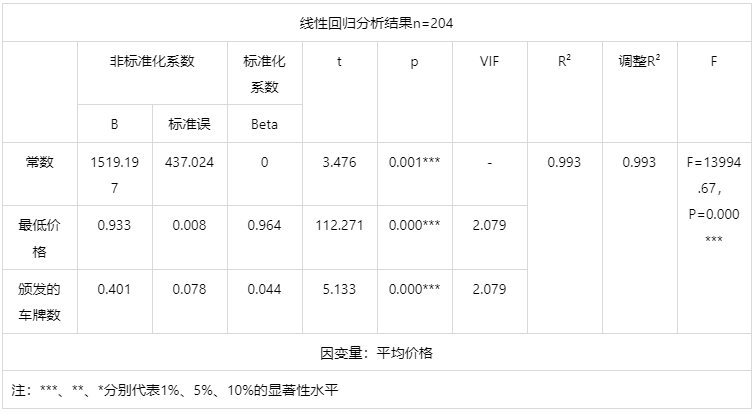
图表说明:上表格展示了本次模型的分析结果,包括模型的标准化系数、t值、VIF值、R²、调整R²等,用于模型的检验,并分析模型的公式。
1. 线性回归模型要求总体回归系数不为0,即变量之间存在回归关系。根据F检验结果对模型进行检验;
2. R²代表曲线回归的拟合程度,越接近1效果越好;
3. VIF值代表多重共线性严重程度,用于检验模型是否呈现共线性,即解释变量间存在高度相关的关系(VIF应小于10或者5,严格为5)若VIF出现inf,则说明VIF值无穷大,建议检查共线性,或者使用岭回归;
4. B是有常数情况下的的系数;
5. 标准误=B/t值;
6. 标准化系数是将数据标准化后得到的系数;
7. VIF是共线性;
8. F(df1,df2)是df1等于自变量数量;df2等于样本量-(自变量数量+1)。
9. F检验是为了判断是否存在显著的线性关系,R方是为了判断回归直线与此线性模型拟合的优劣。在线性回归中主要关注F检验是否通过,而在某些情况下,R方大小和模型解释度没有必然关系。
注: 对于分类型自变量,spsspro会对其做哑变量处理,它是将具有n分类水平的变量转化成(n-1)个哑变量。举一个例子,假设变量“上班交通工具”的取值分别为:公交、地铁、私家车、自行车、电动车,5种选项,我们可以转化4个哑变量来代替“交通工具”这个变量,分别为D1(1=公交/0=非公交)、D2(1=地铁/0=非地铁)、D3(1=私家车/0=非私家车)、D4(1=自行车/0=非自行车),最后一个选项“电动车”的信息已经包含在这4个变量中了,即当(非公交、非地铁、非私家车、非自行车)的情况,那么只可能是电动车,所以不需要再增加一个D5(1=电动车/0=非电动车)了。
智能分析:从F检验的结果分析可以得到,显著性P值为0.000***,水平呈现显著性,拒绝回归系数为0的原假设。对于变量共线性表现,VIF全部小于10,因此模型没有多重共线性问题,模型构建良好。 模型的公式如下: y=1519.197+0.933*最低价格+0.401*颁发的车牌数
分析:这一步对构建好的模型进行F检验,检查模型构建情况,是否存在多重共线性问题,一般经过筛选后的逐步回归模型都能通过这个检验。
输出结果3:拟合效果图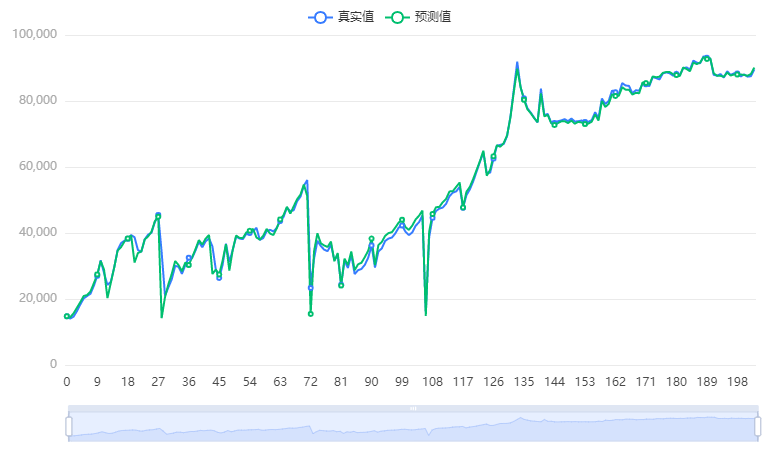
图表说明:上图展示了本次模型的原始数据图、模型拟合值、模型预测值。
输出结果4:模型路径图
图表说明:上图以路径图形式展示了本次模型结果,主要包括模型的系数,用于分析X对于Y的影响关系情况。
输出结果5:模型结果预测
图表说明:上表格显示了经过逐步回归后的模型预测情况。
# 7、注意事项
- 逐步回归一般有三种策略:正向、向后和逐步选择。一般采用默认的逐步选择即可。
- 逐步回归一般用于变量的筛选(哪些变量重要,且最终结果没有多重共线性),结果可以作为其他模型的输入。也可以对共线性严重的数据进行回归分析的预测或者解释。
- 如果输出“模型无显著变量”,说明可能所有的自变量均无太大意义。
# 8、模型理论
逐步回归主要解决的是多变量共线性问题,也就是不是线性无关的关系,它是基于变量解释性来进行特征提取的一种回归方法。
逐步回归的主要做法有三种:
(一)向前选择:
将自变量逐个引入模型,引入一个自变量后要查看该变量的引入是否使得模型发生显著性变化(F检验),如果发生了显著性变化,那么则将该变量引入模型中,否则忽略该变量,直至所有变量都进行了考虑。即将变量按照贡献度从大到小排列,依次加入。
步骤:
(1)建立每个自变量与因变量的一元回归方程:![]()
(2)分别计算m个一元回归方程中的回归系数的检验统计量F,并求出最大值为![]() ,
,
若![]() ,停止筛选,否则将选入变量集,此时可以将看做,进入步骤(3)
,停止筛选,否则将选入变量集,此时可以将看做,进入步骤(3)
(3)分别将自变量组(x1,x2),(x1,x3),...,(x1,xm),与因变量建立二元回归方程,(此时是步骤2中的xk1)计算方程中x1,x2,x3,...,xm的回归系数检验统计量F,取![]() ,若
,若![]() 则停止筛选,否则将xk2选入变量集,此时将xk2看做x2....如此迭代直到自变量的最大的F值小于临界值,此时回归方程就是最优的回归方程。
特点:自变量一旦选入,则永远保存在模型中;不能反映自变量选进模型后的模型本身的变化情况。
则停止筛选,否则将xk2选入变量集,此时将xk2看做x2....如此迭代直到自变量的最大的F值小于临界值,此时回归方程就是最优的回归方程。
特点:自变量一旦选入,则永远保存在模型中;不能反映自变量选进模型后的模型本身的变化情况。
(2)向后选择:
与向前选择相反,在这个方法中,将所有变量放入模型,然后尝试将某一变量进行剔除,查看剔除后对整个模型是否有显著性变化(F检验),如果没有显著性变化则剔除,若有则保留,直到留下所有对模型有显著性变化的因素。即将自变量按贡献度从小到大,依次剔除。
步骤:
(1)建立全部x1,x2,x3,...,xm对因变量y的回归方程,对方程中的m个自变量进行F检验,取最小值为:![]() ,若
,若![]() ,则没有自变量可剔除,此时回归方程就是最优的;否则将xk2剔除,在此时可令xk1为xm,进入步骤(2)。
(2)建立与因变量y的回归方程,对方程中的回归系数进行F检验,取最小值
,则没有自变量可剔除,此时回归方程就是最优的;否则将xk2剔除,在此时可令xk1为xm,进入步骤(2)。
(2)建立与因变量y的回归方程,对方程中的回归系数进行F检验,取最小值![]() ,若
,若![]() ,则无变量需要剔除,此时方程就是最优的,否则将xk2剔除,此时设xk2为xm-1,...,一直迭代下去,直到各变量的回归系数F值均大于临界值,即方程中没有变量可以剔除为止,此时的回归方程就是最优的回归方程。
,则无变量需要剔除,此时方程就是最优的,否则将xk2剔除,此时设xk2为xm-1,...,一直迭代下去,直到各变量的回归系数F值均大于临界值,即方程中没有变量可以剔除为止,此时的回归方程就是最优的回归方程。
特点:自变量一旦剔除,则不再进入模型;开始把全部自变量引入模型,计算量过大。
(3)逐步筛选法:
是在第一个的基础上做一定的改进,当引入一个变量后,首先查看这个变量是否使得模型发生显著性变化(F检验),若发生显著性变化,再对所有变量进行t检验,当原来引入变量由于后面加入的变量的引入而不再显著变化时,则剔除此变量,确保每次引入新的变量之前回归方程中只包含显著性变量,直到既没有显著的解释变量选入回归方程,也没有不显著的解释变量从回归方程中剔除为止,最终得到一个最优的变量集合。
# 9、手推步骤
| 日期 | 颁发的车牌数 | 最低价格 | 平均价格 | 申请人总数 |
|---|---|---|---|---|
| 1/2/2022 | 1400 | 13600 | 14700 | 3700 |
| 2/2/2022 | 1800 | 13100 | 14000 | 4600 |
| 3/2/2022 | 2000 | 14300 | 14600 | 5100 |
| 4/2/2022 | 2300 | 16000 | 16300 | 4800 |
| 5/2/2022 | 2350 | 17800 | 18300 | 4600 |
| 6/2/2022 | 2800 | 19600 | 20100 | 4500 |
| 7/2/2022 | 3000 | 19800 | 20900 | 3700 |
| 8/2/2022 | 3000 | 21000 | 21600 | 4600 |
| 9/2/2022 | 3200 | 23600 | 24000 | 4300 |
| 10/2/2022 | 3200 | 26400 | 27000 | 4600 |
这里展示逐步回归的第一种做法:向前选择。
step1:引入第一个变量
对于最低价格
计算得到
回归平方和
总离差平方和
残差平方和
F检验
其中
对于平均价格
因为
step2:引入第二个变量
对于平均价格
参照step1的步骤计算F值
计算得到
所以向前选择逐步回归法得到的最终模型为
# 10、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]刘明,王仁曾.基于t检验的逐步回归的改进[J].统计与决策,2012(06):16-19.DOI:10.13546/j.cnki.tjyjc.2012.06.012.
[3]Foneone. 回归问题-逐步回归.https://blog.csdn.net/foneone/article/details/101945415