线性判别
# 1、作用
线性判别的原理是将样本投影到一条直线上,使得同类样本的投影点尽可能接近,不同样本的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的直线上,再根据投影点的位置来确定新样本的类别。其中线性判别(LDA)也常用于数据降维,可在数据处理的降维部分使用。
# 2、输入输出描述
输入:自变量X为1个或1个以上的定量变量,因变量Y为一个定类变量。
输出:模型的分类结果和模型分类的评价效果。
# 3、案例示例
示例:根据红酒的颜色强度,脯氨酸,类黄酮等变量,生成一个能够区分琴酒,雪莉,贝尔摩德三种品种的红酒的线性判别模型。
# 4、案例数据
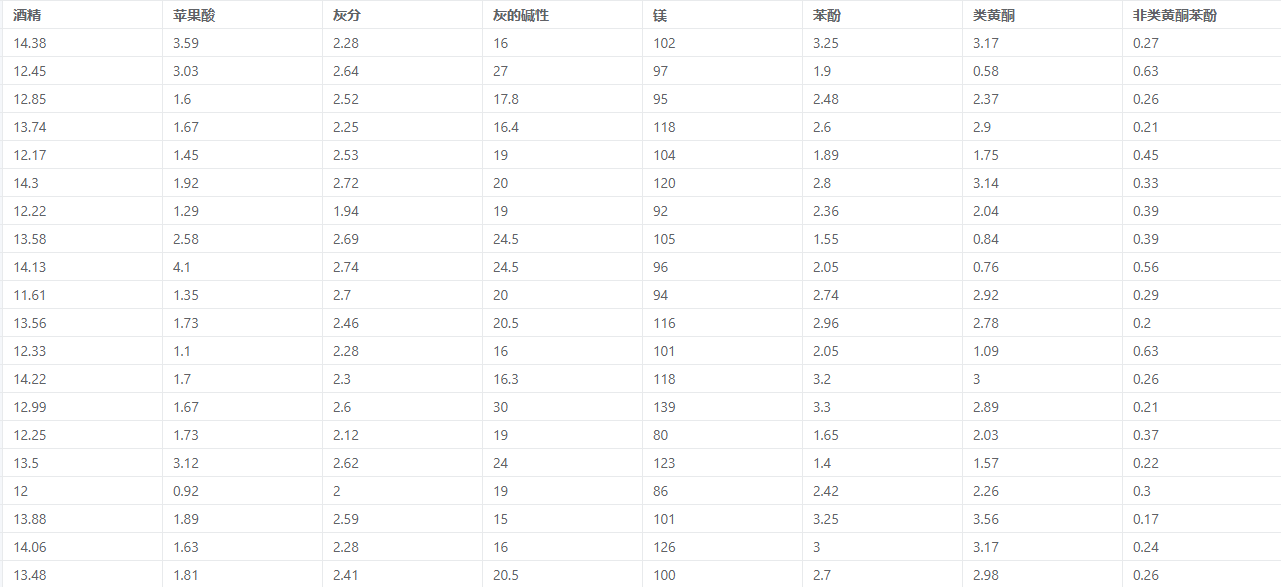
判别分析案例数据
# 5、案例操作
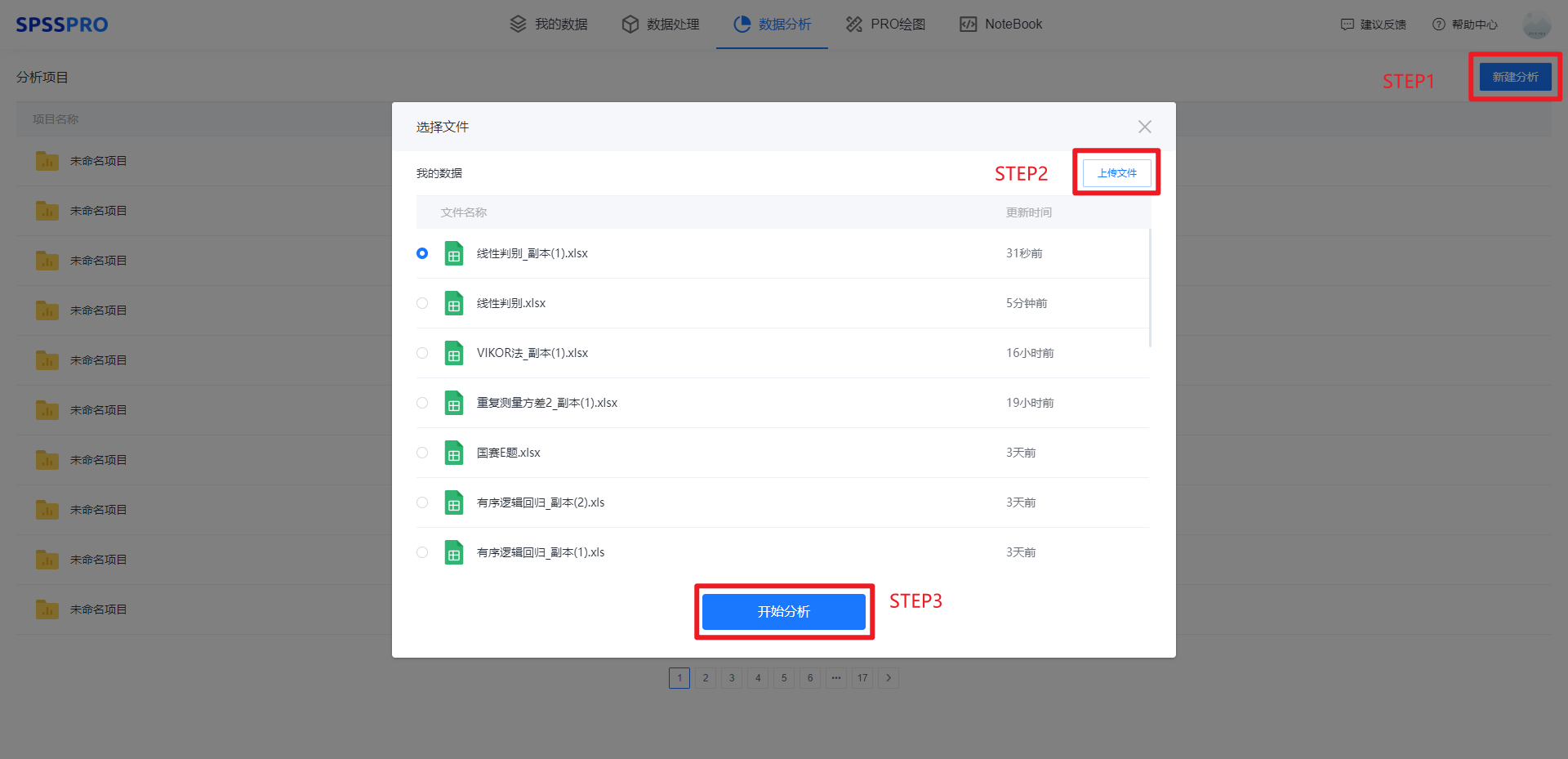
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;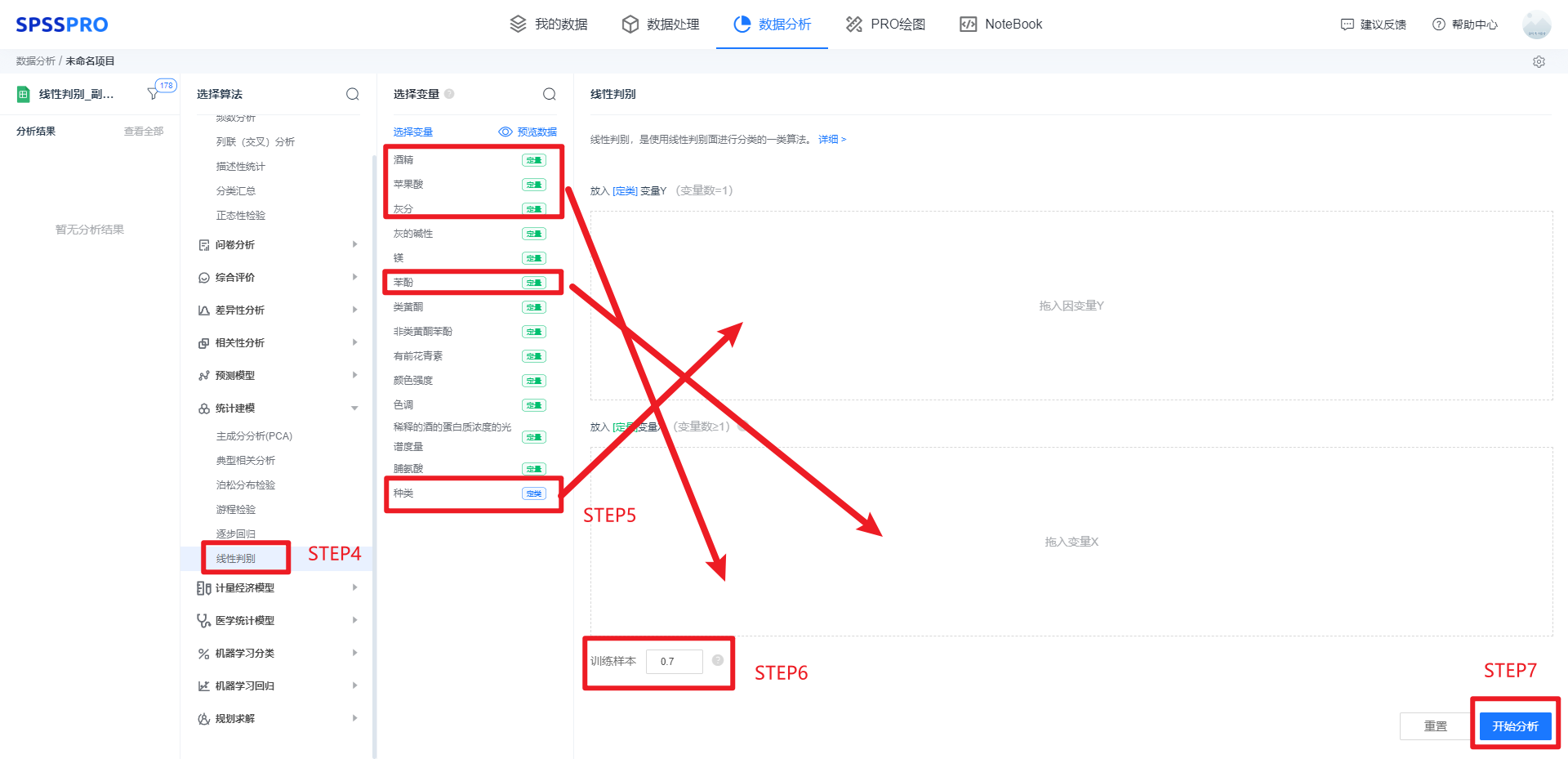
step4:选择【判别分析】;
step5:查看对应的数据数据格式,按要求输入【判别分析】数据;
step6:选择训练样本的比例,本例为默认0.7;
step7:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果1:判别函数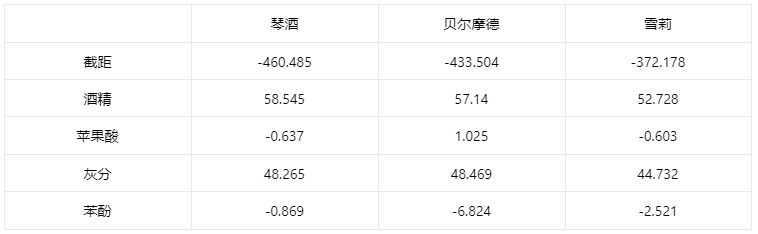
图表说明:
上表展示了线性判别的判别函数,可以将数据代入其中,然后比较不同类别的判别函数值大小进行分类,最大的值即为被判断的种类。
智能分析:
模型的判别函数如下:
琴酒=-460.485 + 58.545×酒精 - 0.637×苹果酸 + 48.265×灰分 - 0.869×苯酚
贝尔摩德=-433.504 + 57.14×酒精 + 1.025×苹果酸 + 48.469×灰分 - 6.824×苯酚
雪莉=-372.178 + 52.728×酒精 - 0.603×苹果酸 + 44.732×灰分 - 2.521×苯酚
分析:
可以将新的样本代入判别函数进行计算,用于对新样本进行类别判断。
输出结果2:混淆矩阵热力图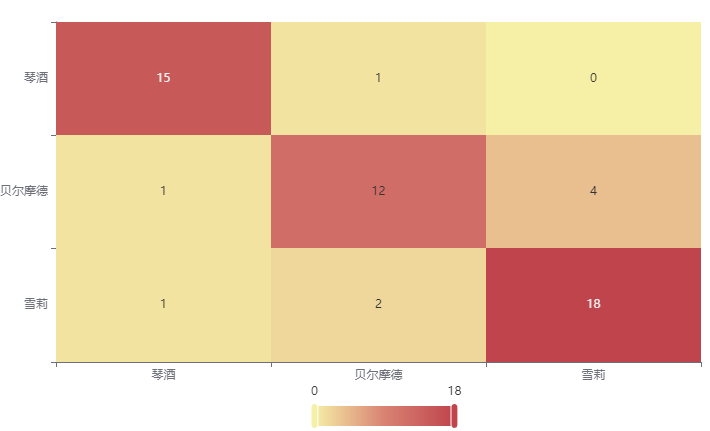
图表说明:
上表以热力图的形式展示了混淆矩阵。
输出结果3:模型评估结果 
图表说明:
上表中展示了训练集和测试集的预测评价指标,通过量化指标来衡量线性判别的预测效果。 ● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用F1指标。
输出结果4:测试数据预测评估结果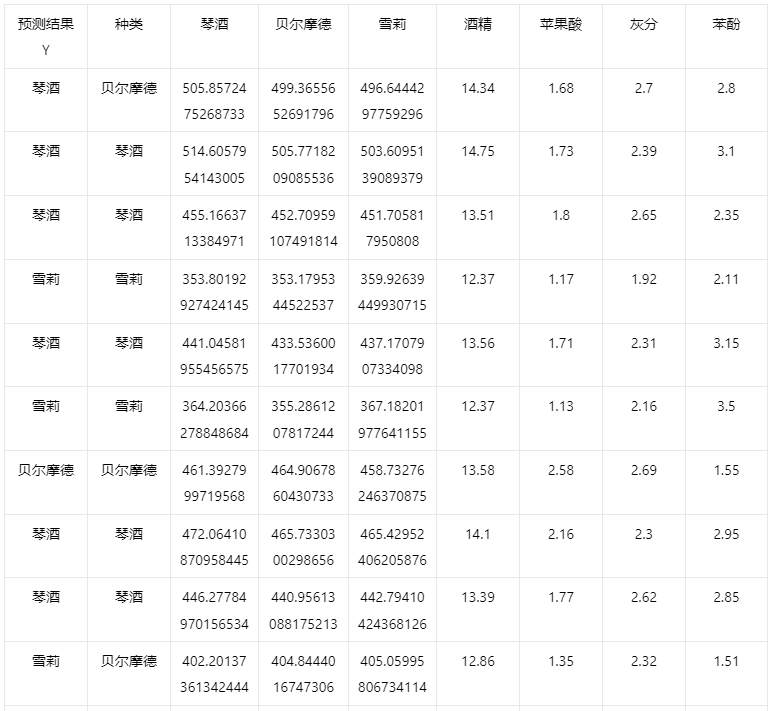
图表说明:
上表格为预览结果,只显示部分数据,全部数据请点击下载按钮导出。
上表展示了线性判别对测试数据的分类结果,分类结果值是拥有最大判别函数计算值的分类组别。
# 7、注意事项
- 对于本判别分析模型而言,二分类与多分类的计算方法并不一致。
- 本判别分析模型使用的为Fisher判别法。
# 8、模型理论
线性判别分析(LDA)是一种经典的有监督(supervised)降维(Dimensionality Reduction)与分类(Classification)方法,主要应用于多类别分类任务。LDA的核心思想是:找到一个投影方向,使得同类样本尽量聚集,不同类别样本尽量分开。
LDA既可用于降维(特征压缩),也可直接用于分类(判别分析)。
二分类
由于需要考虑如何使得不同类样例的投影点尽可能远离,因此需要采用一个标准来衡量类间距离,LDA中采用的是两个类别的均值向量
其中,
同样的,也需要提出一个指标来衡量同类样例投影点的接近程度,方差可以用来度量一组数据间的离散程度,方差越大则数据就越分散。基于此我们可以分别计算出
两个类别的方差和
其中,
根据LDA的目标,我们需要使得同类样例间的投影点尽可能接近,即使得
令
判别函数的阈值
当
当
当
当
多分类
对于多分类任务,过程与二分类大致相同。
假设存在N个类,样本总数为m,样本中第i类示例集合为
类内散度矩阵
类间散度矩阵
目标函数
此时w的解是
# 9、手推步骤
有如下10个样本,样本有2个特征,前5项为负类,后5项为正类。
线性判别过程如下:
step1:计算均值
令负类为
step2:计算类内散度矩阵
各类的类内散度矩阵
同理计算得到
计算得到类内总散度矩阵
计算得到逆矩阵
step3:求解判别函数
计算得到
所以判别函数为
阈值
因为
# 10、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] 陈华豪.介绍判别分析——一种多元分析工具[J].林业勘查设计,1981(04):49-52.
[3] 赵丽娜. Fisher判别法的研究及应用[D]. 东北林业大学, 2013.