双指数平滑法
# 1、作用
当数据有趋势但没有季节性分量时,使用双指数平滑作为一般平滑处理方法并提供短期预测值。此过程计算以下两个分量的动态估计值:水平和趋势。
# 2、输入输出描述
输入:一项定量或一项定量和时间变量
输出:双指数平滑图
# 3、案例示例
一位在线零售商想要预测2023年1月-2023年6月内的计算机销售量。该零售商收集了2021年-2022年两年内有关计算机销量和软件销量的数据,可以利用双指数平滑法预测2023年未来6个月的计算机销售量趋势。
# 4、案例数据
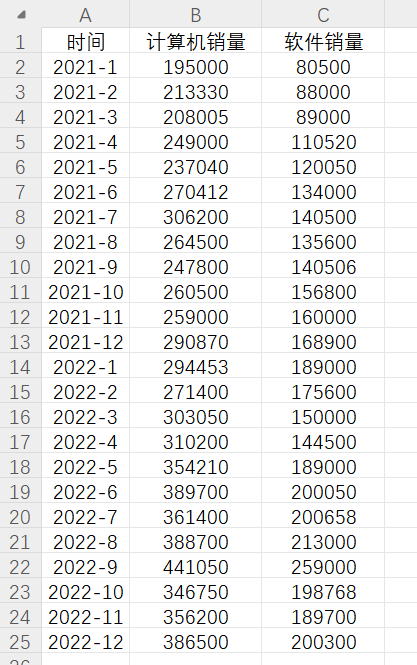
# 5、案例操作
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
Step4:选择【双指数平滑法】;
Step5:查看对应的数据数据格式,按照【双指数平滑法】要求输入数据。
Step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
# 输出结果1:双指数平滑图
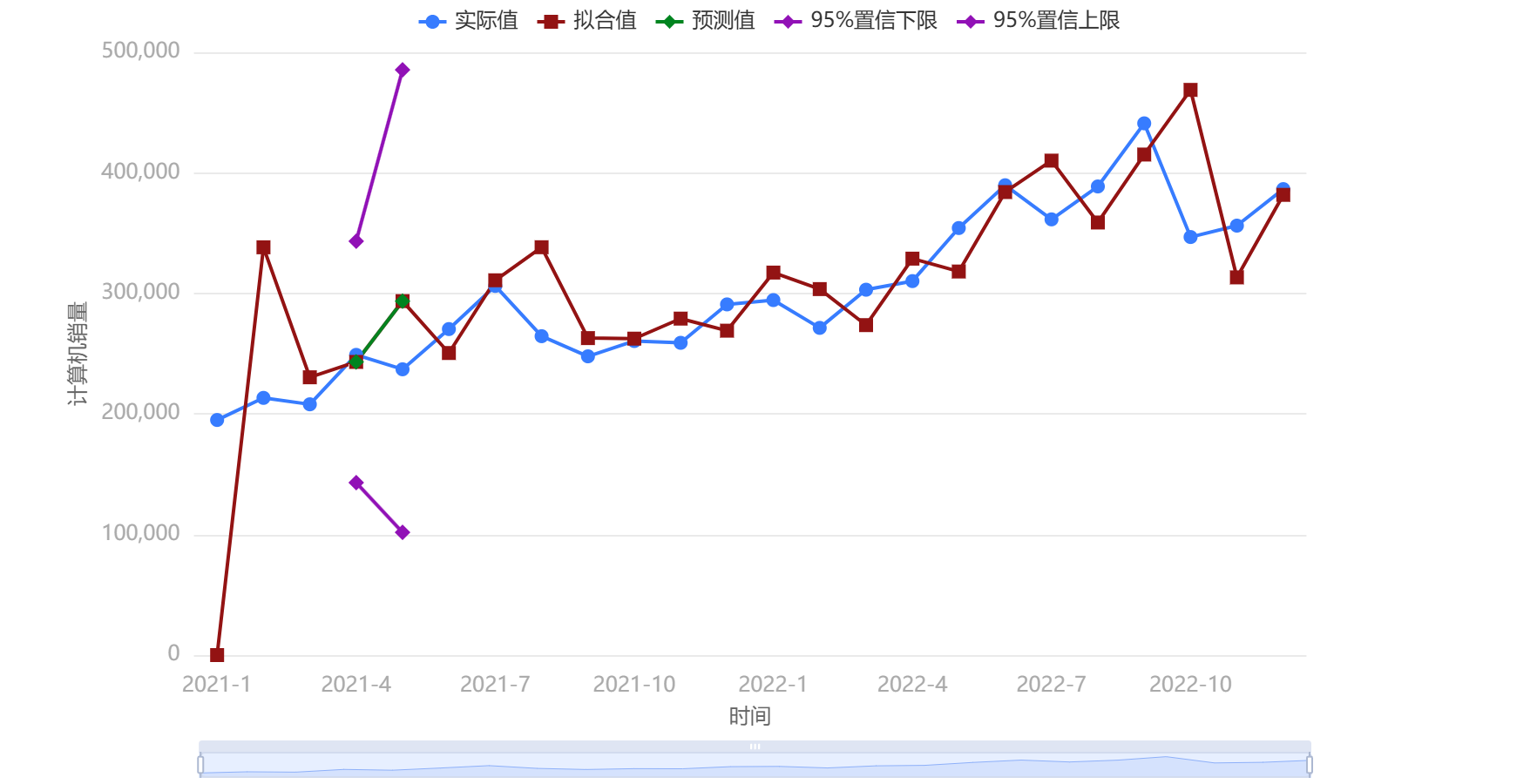
图表说明:通过双指数平滑法可以平滑数据波动,展示历史趋势及短期预测结果。关于图表中的“实际值”、“拟合值”、“预测值”、“95%置信下限”和“95%置信上限”的解释如下:
(1)实际值 :各时间点真实数据,反映即时波动。
(2)拟合值 :基于历史数据计算的模型拟合结果,凸显趋势。
(3)预测值 :对未来时间的销量预估,延续拟合趋势。
(4)95%预测区间 :预测值的置信范围,体现不确定性。
# 输出结果2:误差指标汇总表
| 评价指标 | 平均绝对百分比误差(MAPE) | 平均绝对误差(MAD) | 平均偏差平方和(MSD) |
|---|---|---|---|
| 结果 | 15.702 | 40870.662 | 3713481275.925 |
图表说明:关于平均绝对百分比误差 (MAPE)、平均绝对误差 (MAD) 及平均偏差平方和(MSD)解释如下:
(1)平均绝对百分比误差 (MAPE)度量拟合值与实际值绝对偏差占实际值的百分比均值,反映相对误差幅度;
(2)平均绝对误差 (MAD) 度量拟合值与实际值绝对偏差的算术平均值,直接体现误差绝对大小;
(3)平均偏差平方和(MSD)度量拟合值与实际值偏差平方的算术平均值,对异常大误差赋予更高权重。
根据误差指标汇总表可知,平均绝对百分比误差为{ 15.702 },平均绝对误差为{ 40870.662 },平均偏差平方和为{ 3713481275.925 }。
# 7、注意事项
- 按时间顺序记录数据:时间序列数据按照固定的间隔收集,而且按时间顺序记录。应当按照数据的收集顺序将数据记录到工作表中。
- 收集足够的数据以评估趋势或模式:请收集足够的数据,以便您可以完全评估数据中的趋势或模式。
- 按照适当的时间间隔收集数据:基于您要检测的模式选择时间间隔。例如,要在过程中查找每个月的模式,请在每个月的同一时间收集数据。
# 8、模型理论
双指数平滑在每个周期处采用水平分量和趋势分量。双指数平滑使用两个权重(又称为平滑参数)在每个周期处更新分量。双指数平滑方程如下所示:
式中,
权重的计算如下:
(1)最优ARIMA权重:
①使用ARIMA(0,2,2)模型与数据拟合,以尽可能使误差平方和最小。;
②随后,向后预测方法对趋势和水平分量进行初始化。
(2)指定权重的方法:
①将线性回归模型与时间序列数据(y变量)和时间(x变量)的关系进行拟合;
②此回归中的常量是水平分量的初始估计值,斜率系数是趋势分量的初始估计值。
水平和趋势的初始值计算方法:
(1)选择最优综合自回归移动平均(ARIMA),则使用以下方法来计算水平和趋势的第一个值:
①使用ARIMA(0,2,2)计算对应的MA值及残差值
②使用后续观测值的数据计算回初始观测值:
式中,
③计算水平 (L1) 的初始值
④计算趋势 (T1) 的初始值
(2)选择自定义水平和趋势权重,则使用以下方法来计算水平和趋势的初始值:
①水平的初始值是:
②趋势的初始值是:
式中,
预测上下限的计算:
式中,MAD表示平均绝对误差,
平均绝对百分比误差 (MAPE):
平均绝对百分比误差(MAPE)度量时间序列值拟合的准确度。MAPE以百分比表示准确度。
其中,
平均绝对误差 (MAD):
平均绝对偏差(MAD)度量时间序列值拟合的准确度。MAD以与数据相同的单位表示准确度,从而有助于使误差量概念化。
其中,
平均偏差平方和 (MSD):
无论采用哪种模型,平均偏差平方和(MSD)始终是使用相同的分母
其中,
# 9、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]黎锁平,武会超.基于双指数平滑方法的通信软件可靠性分析[J].兰州理工大学学报,2006,(04):102-104.