XGBoost分类
# 1、作用
xgboost是GBDT的一种高效实现,和GBDT不同,xgboost给损失函数增加了正则化项;且由于有些损失函数是难以计算导数的,xgboost使用损失函数的二阶泰勒展开作为损失函数的拟合。
# 2、输入输出描述
输入:自变量X为1个或1个以上的定类或定量变量,因变量Y为一个定类变量。
输出:模型的分类结果和模型分类的评价效果。
# 3、案例示例
根据红酒的颜色强度,脯氨酸,类黄酮等变量,生成一个能够区分琴酒,雪莉,贝尔摩德三种品种的红酒的xgboost。
# 4、案例数据

xgboost分类案例数据
# 5、案例操作
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;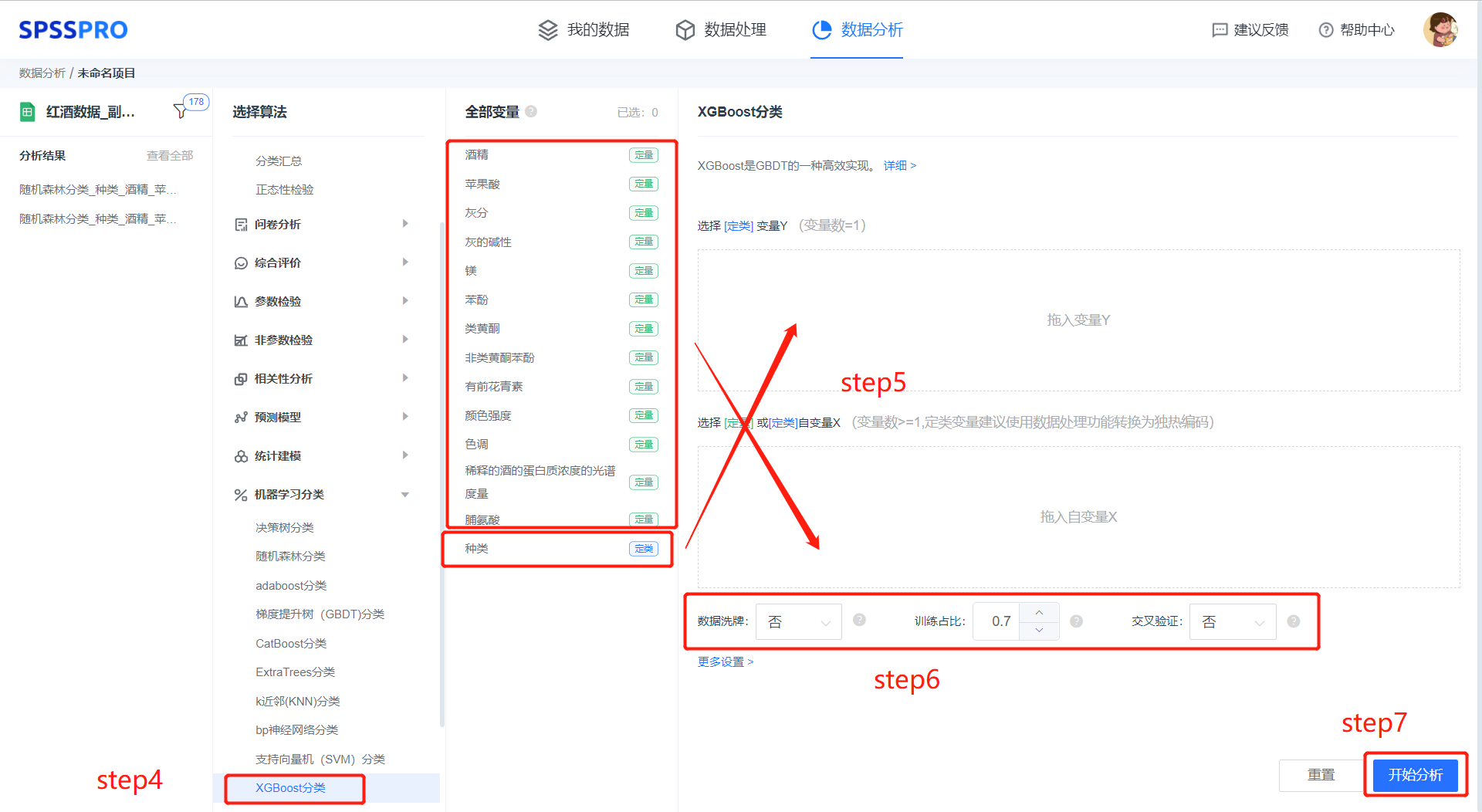
step4:选择【xgboost分类】;
step5:查看对应的数据数据格式,按要求输入【xgboost分类】数据;
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step7:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果1:模型参数 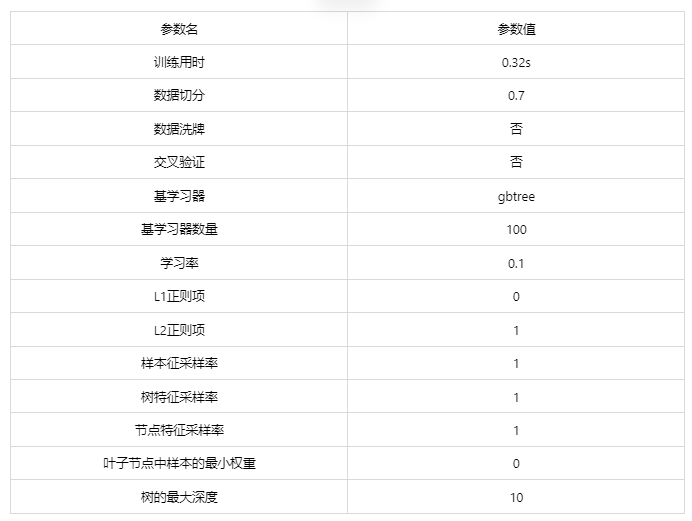
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
输出结果2:特征重要性
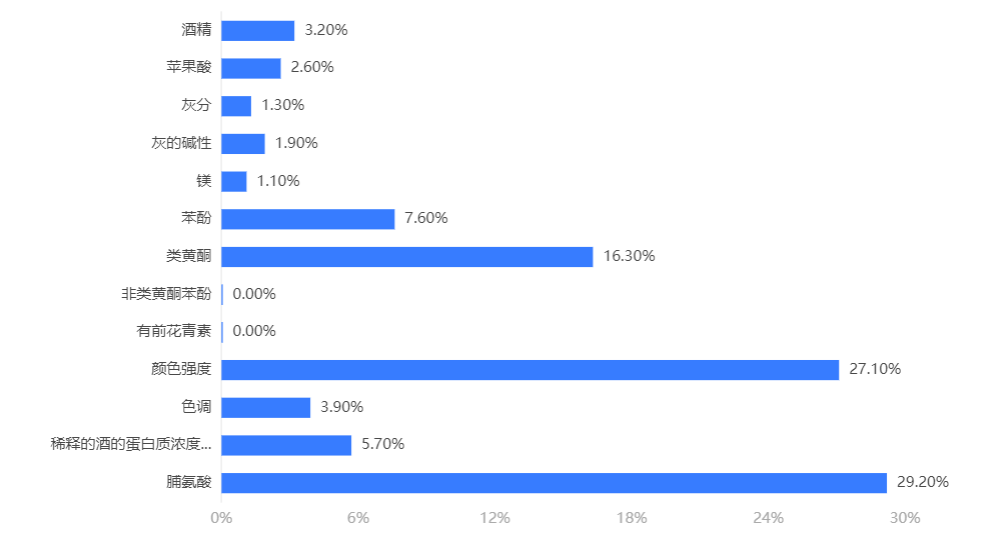
图表说明:上柱形图或表格展示了各特征(自变量)的重要性比例。(附:有时候可以利用特征重要性反推该变量在实际生活中的价值,因为该重要性往往决定分类结果。)
分析:xgboost模型中决定分类结果的重要因素是脯氨酸、颜色强度、类黄酮。
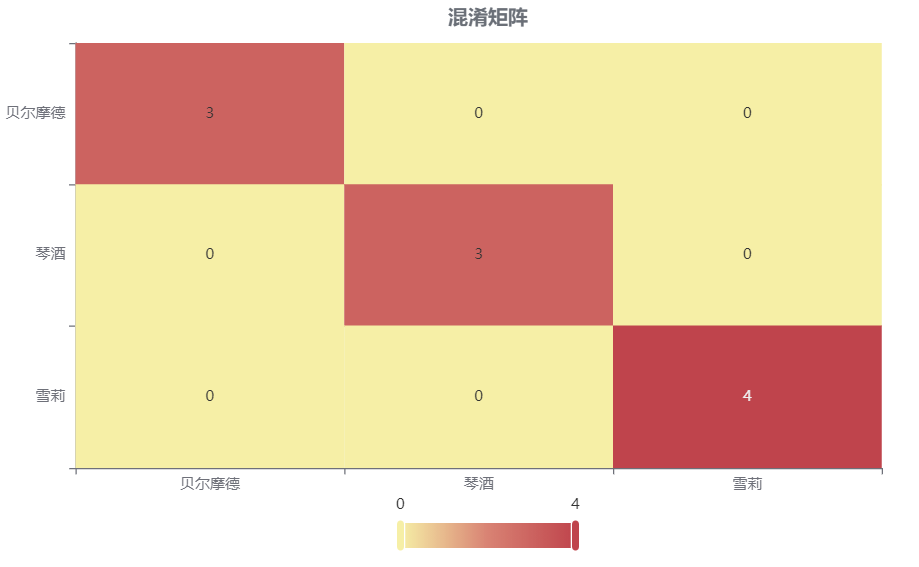
输出结果3:混淆矩阵热力图
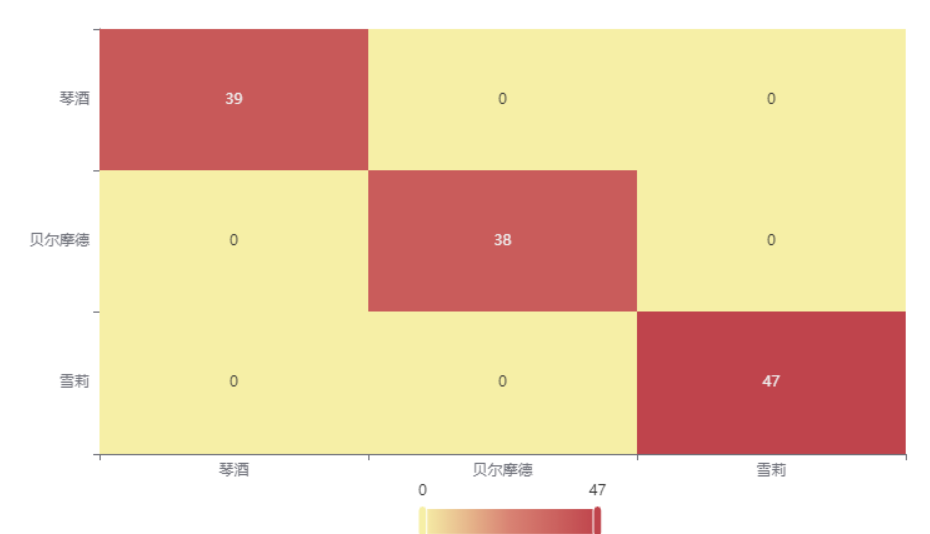
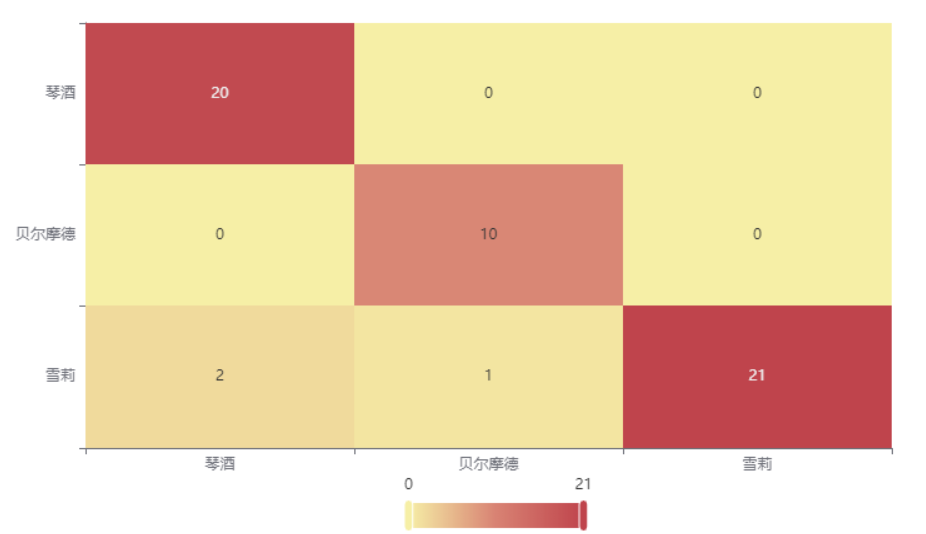
图表说明: 上表以热力图的形式展示了混淆矩阵,可以通过右上角切换在测试数据集和训练数据集中的情况。
分析:
上图是训练集的分类结果,所有样本分类正确,说明分类效果极好。
下图是测试集的分类结果,绝大部分样本分类正确,只有3个被分错的样本,说明训练集训练出来的模型结果是有效实用的。
输出结果4:模型评估结果
图表说明: 上表中展示了训练集和测试集的分类评价指标,通过量化指标来衡量xhboost对训练、测试数据的分类效果。
● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用F1指标。
分析:
训练集的各分类评价指标都大于0.9,说明模型在训练集的分类效果极好,模型具有实用性。
测试集的各分类评价指标都大于0.9,说明模型在测试集的分类效果极好,模型具有实用性。
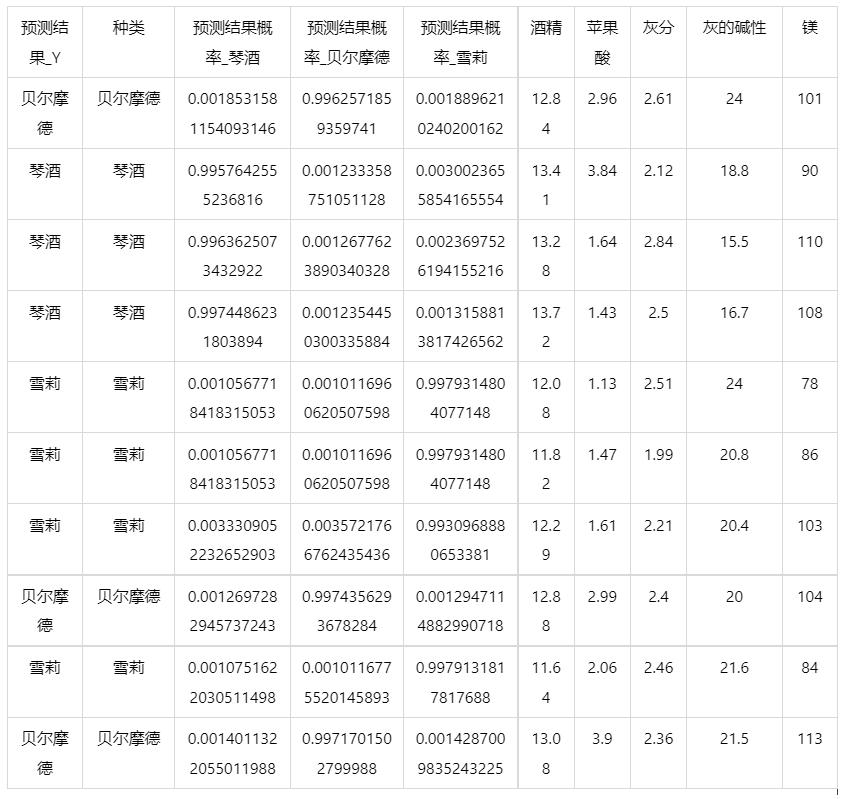
输出结果5:测试数据预测评估结果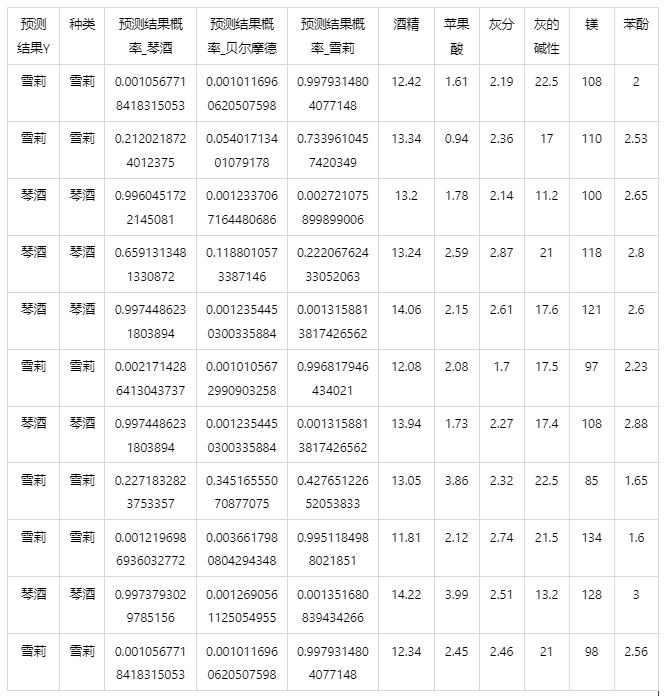
图表说明: 上表格为预览结果,只显示部分数据,全部数据请点击下载按钮导出。
上表展示了xgboost模型对测试数据的分类结果,第一列是预测结果,第二列是因变量真实值,第三、四、五列分别是对所属每一个分类水平概率的预测结果,最终分类预测结果值是拥有最大预测概率的分类组别。
输出结果6:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
●当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
●当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况1:在上面模型评估后,模型分类结果较好,具有实用性,这时我们将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
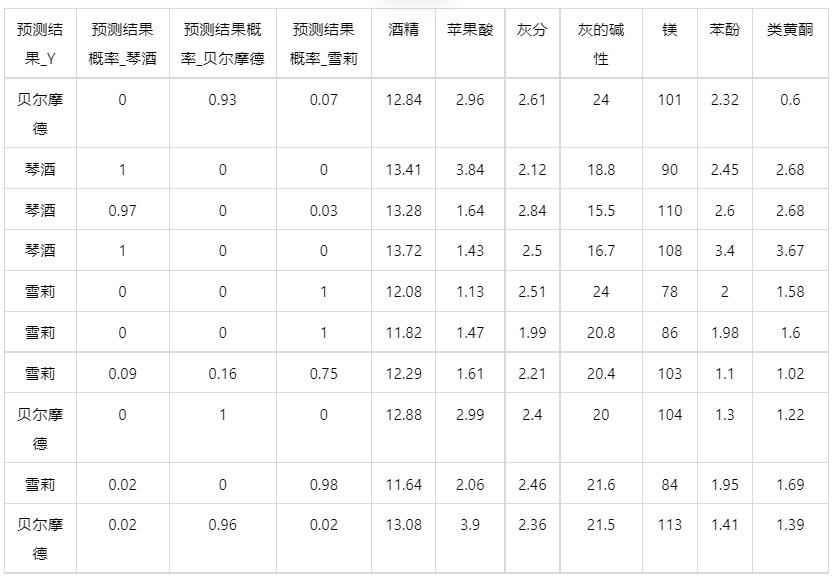
情况2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到当前数据分类混淆矩阵和分类评价效果。

# 7、注意事项
- 由于xgboost具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用SPSSPRO客户端进行。
- xgboost的参数修改需要使用SPSSPRO客户端进行。
# 8、模型理论
XGBoost 是"极端梯度上升"(Extreme Gradient Boosting)的简称,XGBoost 算 法是一类由基函数与权重进行组合形成对数据拟合效果佳的合成算法。由于 XGBoost 模型具有较强的泛化能力、较高的拓展性、较快的运算速度等优势, 从2015年提出后便受到了统计学、数据挖掘、机器学习领域的欢迎。
对于包含 n 条 m 维的数据集 , XGBoost 模型可表示为:
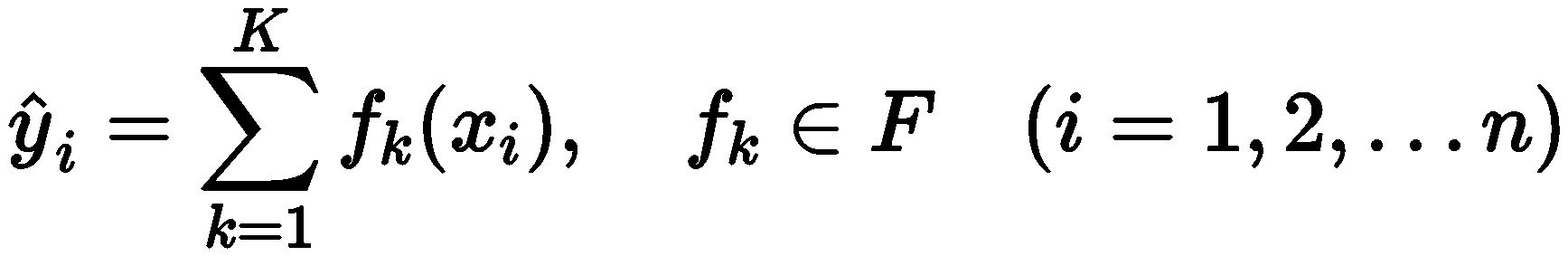 其中,
其中,![]() 是CART决策树结构集合, q 为样本映射到叶子节点的树结构,T 为叶子节点数,w 为叶节点的实数分数。 构建 XGBoost 模型时,需要根据目标函数最小化的原则寻找最优参数,以建立最优模型。XGBoost 模型的目标函数可分为误差函数项 L 和模型复杂度函数项 Ω。目标函数可写为:
是CART决策树结构集合, q 为样本映射到叶子节点的树结构,T 为叶子节点数,w 为叶节点的实数分数。 构建 XGBoost 模型时,需要根据目标函数最小化的原则寻找最优参数,以建立最优模型。XGBoost 模型的目标函数可分为误差函数项 L 和模型复杂度函数项 Ω。目标函数可写为:![]()

其中: ![]() 是 L1 正则项,
是 L1 正则项,![]() 是 L2 正则项.
是 L2 正则项.
在使用训练数据对模型进行优化训练时,需要保留原有模型不变,加入一个 新的函数 f 到模型中,使目标函数尽可能大的减少,具体过程为: 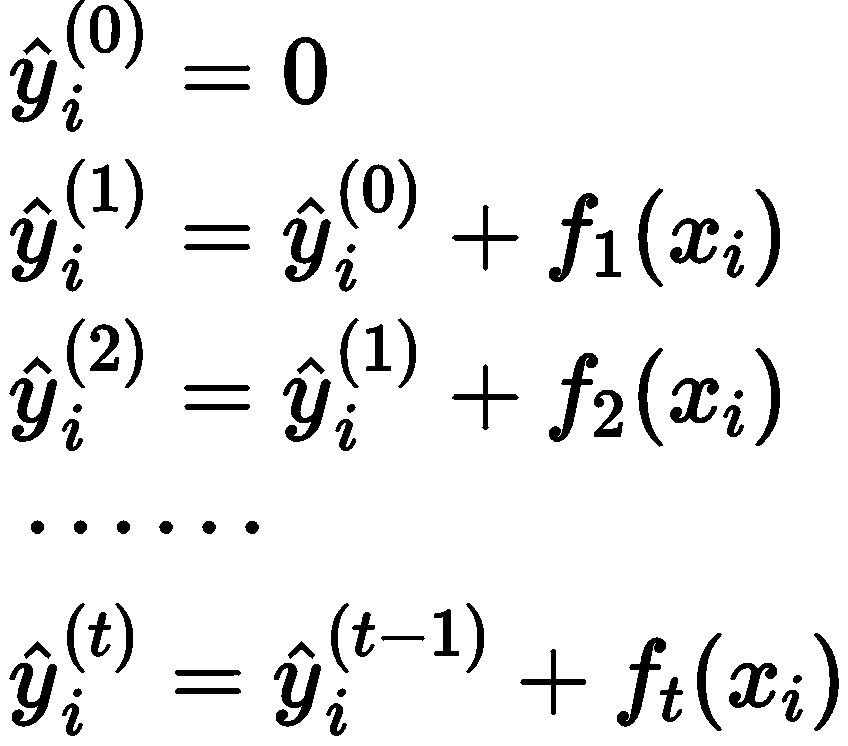
其中: ![]() 为第 t 次模型的预测值,
为第 t 次模型的预测值,![]() 为第 t 次加入的新函数。此时目标函数表示为:
为第 t 次加入的新函数。此时目标函数表示为:
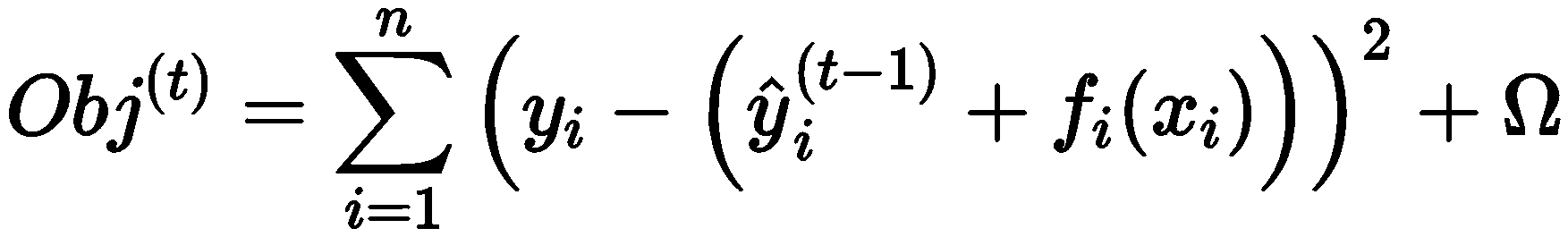
在 XGBoost 算法中,为快速寻找到使目标函数最小化的参数,对目标函数 进行了二阶泰勒展开,得到近似目标函数 
当去掉常数项后可知:目标函数仅仅与误差函数的一阶和二阶导数相关。此 时,目标函数表示为:
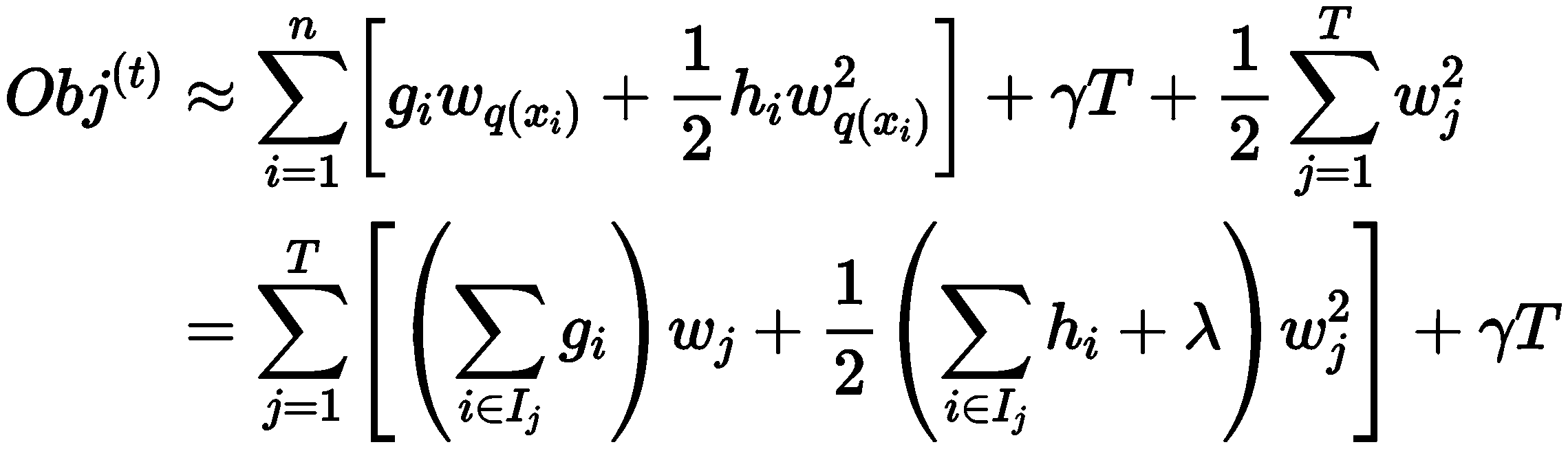 若树的结构部分 q 已知,可使用目标函数寻找最优 Wj,并得到最优目标函数值。其本质可归为二次函数的最小值求解问题。解得:
若树的结构部分 q 已知,可使用目标函数寻找最优 Wj,并得到最优目标函数值。其本质可归为二次函数的最小值求解问题。解得: 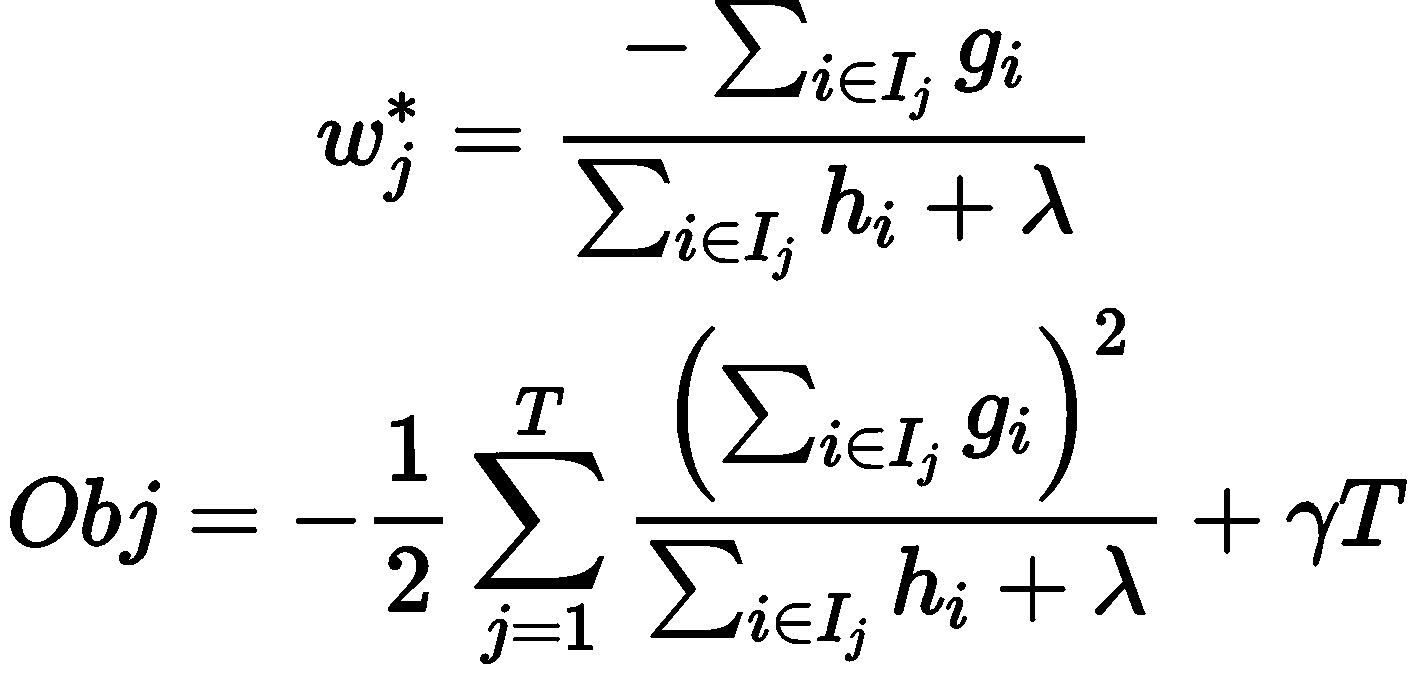
Obj 是可作为评价模型的打分函数, Obj 值越小则模型效果越好。 通过递归调用上述树的建立方法,可得到大量回归树结构,并使用 Obj 搜索 最优的树结构,将其放入已有模型中,从而建立最优的 XGBoost 模型。
# 9、手推步骤
现有4个样本,两列特征分别为年龄和体重,label为身高是否大于1.5米,具体数据情况如下表:
| 编号 | 年龄 | 体重 | label |
|---|---|---|---|
| 0 | 5 | 20 | 0 |
| 1 | 7 | 30 | 0 |
| 2 | 21 | 70 | 1 |
| 3 | 30 | 60 | 1 |
测试数据集:1个样本,需要预测其身高是否大于1.5米,具体数据情况如下:
| 编号 | 年龄 | 体重 | label |
|---|---|---|---|
| 0 | 25 | 65 | ? |
XGBoost分类算法预测过程如下:
step1:设置初始参数
这个案例是二分类问题,用Logistic函数把预测分数
二分类的交叉熵损失函数是:
通过求导得到一阶导数
学习率
设置正则化项参数:
为了简化计算设置树深为2,这里只进行三次迭代。
step2:初始状态
设所有样本初始预测概率
| 编号 | ||||
|---|---|---|---|---|
| 0 | 0 | 0.5 | 0.5 | 0.25 |
| 1 | 0 | 0.5 | 0.5 | 0.25 |
| 2 | 1 | 0.5 | -0.5 | 0.25 |
| 3 | 1 | 0.5 | -0.5 | 0.25 |
初始梯度:
step3:第一次迭代
寻找最佳分裂点:
根节点包含所有样本{0,1,2,3}
不分裂时的目标函数值:
分裂后的目标函数值:
特征年龄分裂点:
年龄 ≤ 6(样本 0 vs 样本 1,2,3)
年龄 ≤ 14(样本 0,1 vs 样本 2,3)
年龄 ≤ 25(样本 0,1,2 vs 样本 3)
特征体重分裂点:
体重 ≤ 25(样本 0 vs 样本 1,2,3)
体重 ≤ 50(样本 0,1 vs 样本 2,3)
体重 ≤ 65(样本 0,1,3 vs 样本2)
选择增益最大的点进行分裂,这里选择年龄 ≤ 14。 分裂后的叶子结点权重:
左节点
右节点
step4:更新预测
tree1输出
样本0,1:
样本2,3:
样本0,1:
样本2,3:
更新概率:
左节点(样本 0,1):
右节点(样本 2,3):
step5:第二次迭代
更新
| 编号 | |||||
|---|---|---|---|---|---|
| 0 | 0 | -0.2 | 0.4502 | 0.4502 | 0.2475 |
| 1 | 0 | -0.2 | 0.4502 | 0.4502 | 0.2475 |
| 2 | 1 | 0.2 | 0.5498 | -0.4502 | 0.2475 |
| 3 | 1 | 0.2 | 0.5498 | -0.4502 | 0.2475 |
根节点:
不分裂时的目标函数值:
寻找最佳分裂点:
特征年龄分裂点:
年龄 ≤ 6(样本 0 vs 样本 1,2,3)
年龄 ≤ 14(样本 0,1 vs 样本 2,3)
年龄 ≤ 25(样本 0,1,2 vs 样本 3)
特征体重分裂点:
体重 ≤ 25(样本 0 vs 样本 1,2,3)
体重 ≤ 50(样本 0,1 vs 样本 2,3)
体重 ≤ 65(样本 0,1,3 vs 样本2)
选择增益最大的点进行分裂,这里选择年龄 ≤ 14。
分裂后的叶子结点权重:
左节点
右节点
step6:更新预测
tree2输出
样本0,1:
样本2,3:
样本0,1:
样本2,3:
更新概率:
左节点(样本 0,1):
右节点(样本 2,3):
step7:第三次迭代
更新
| 编号 | |||||
|---|---|---|---|---|---|
| 0 | 0 | -0.3807 | 0.4060 | 0.4060 | 0.2412 |
| 1 | 0 | -0.3807 | 0.4060 | 0.4060 | 0.2412 |
| 2 | 1 | 0.3807 | 0.5940 | -0.4060 | 0.2412 |
| 3 | 1 | 0.3907 | 0.5940 | -0.4060 | 0.2412 |
根节点:
不分裂时的目标函数值:
寻找最佳分裂点:
特征年龄分裂点:
年龄 ≤ 6(样本 0 vs 样本 1,2,3)
年龄 ≤ 14(样本 0,1 vs 样本 2,3)
年龄 ≤ 25(样本 0,1,2 vs 样本 3)
特征体重分裂点:
体重 ≤ 25(样本 0 vs 样本 1,2,3)
体重 ≤ 50(样本 0,1 vs 样本 2,3)
体重 ≤ 65(样本 0,1,3 vs 样本2)
选择增益最大的点进行分裂,这里选择年龄 ≤ 14。
分裂后的叶子结点权重:
左节点
右节点
step8:更新预测
tree3输出
样本0,1:
样本2,3:
样本0,1:
样本2,3:
更新概率:
左节点(样本 0,1):
右节点(样本 2,3):
step9:预测测试样本
测试样本:年龄 25,体重 65,在三棵树中都被划分到右节点,根据右节点权重得到:
概率:
0.6330>0.5,所以预测值为1,即样本身高大于1.5米。
# 10、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]Chen T , Guestrin C . XGBoost: A Scalable Tree Boosting System[J]. ACM, 2016.