梯度提升树(GBDT)分类
# 1、作用
GBDT 模型是一个加法模型,它串行地训练一组 CART 回归树,最终对所有回归树的预测结果加和,由此得到一个强学习器,每一颗新树都拟合当前损失函数的负梯度方向。最后输出这一组回归树的加和,套用 sigmod 或者 softmax 函数获得二分类或者多分类结果。
# 2、输入输出描述
输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定类变量。
输出:模型的分类结果和模型分类的评价效果。
# 3、案例示例
根据红酒的颜色强度,脯氨酸,类黄酮等变量,生成一个能够区分琴酒,雪莉,贝尔摩德三种品种的红酒的梯度提升树。
# 4、案例数据

梯度提升树分类案例数据
# 5、案例操作
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
step4:选择【梯度提升决策树(GBDT)分类】;
step5:查看对应的数据数据格式,按要求输入【梯度提升决策树(GBDT 分类】数据;
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:模型参数 
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
输出结果 2:特征重要性
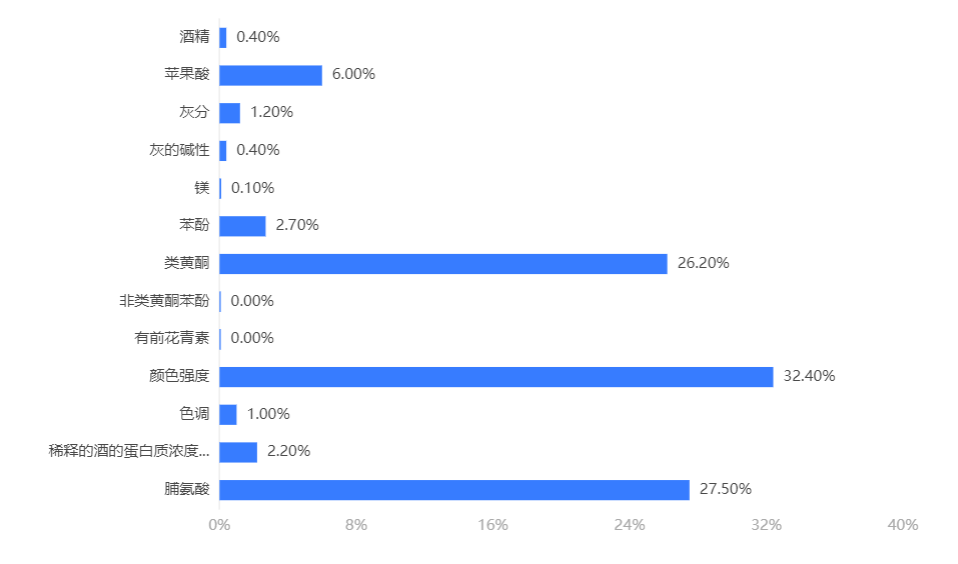
图表说明:上柱形图或表格展示了各特征(自变量)的重要性比例。(附:有时候可以利用特征重要性反推该变量在实际生活中的价值,因为该重要性往往决定分类结果。)
分析:gbdt 模型中决定分类结果的重要因素是颜色强度、脯氨酸、类黄酮和苹果酸。
输出结果 3:混淆矩阵热力图
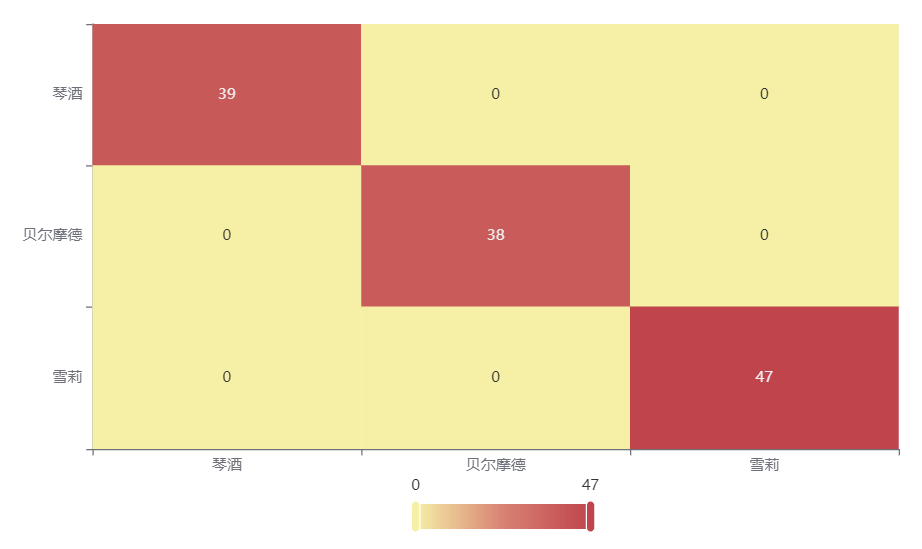
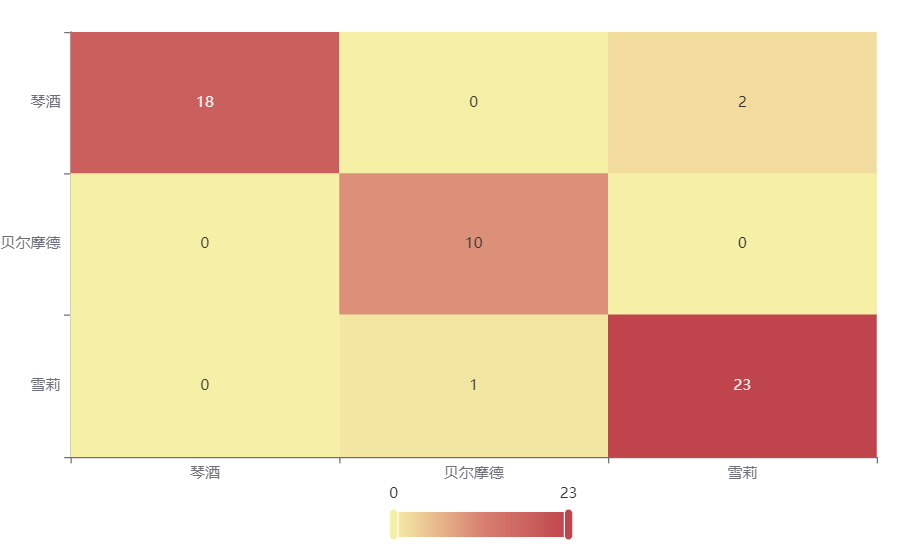
图表说明: 上表以热力图的形式展示了混淆矩阵,可以通过右上角切换在测试数据集和训练数据集中的情况。
分析:
上图是训练集的分类结果,所有样本分类正确,说明分类效果极好。
下图是测试集的分类结果,绝大部分样本分类正确,只有 3 个被分错的样本,说明训练集训练出来的模型结果是有效实用的。
输出结果 4:模型评估结果
图表说明: 上表中展示了训练集和测试集的分类评价指标,通过量化指标来衡量 gbdt 对训练、测试数据的分类效果。
● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用 F1 指标。
分析:
训练集的各分类评价指标都大于 0.9,说明模型在训练集的分类效果极好,模型具有实用性。
测试集的各分类评价指标都大于 0.9,说明模型在测试集的分类效果极好,模型具有实用性。
输出结果 5:测试数据预测评估结果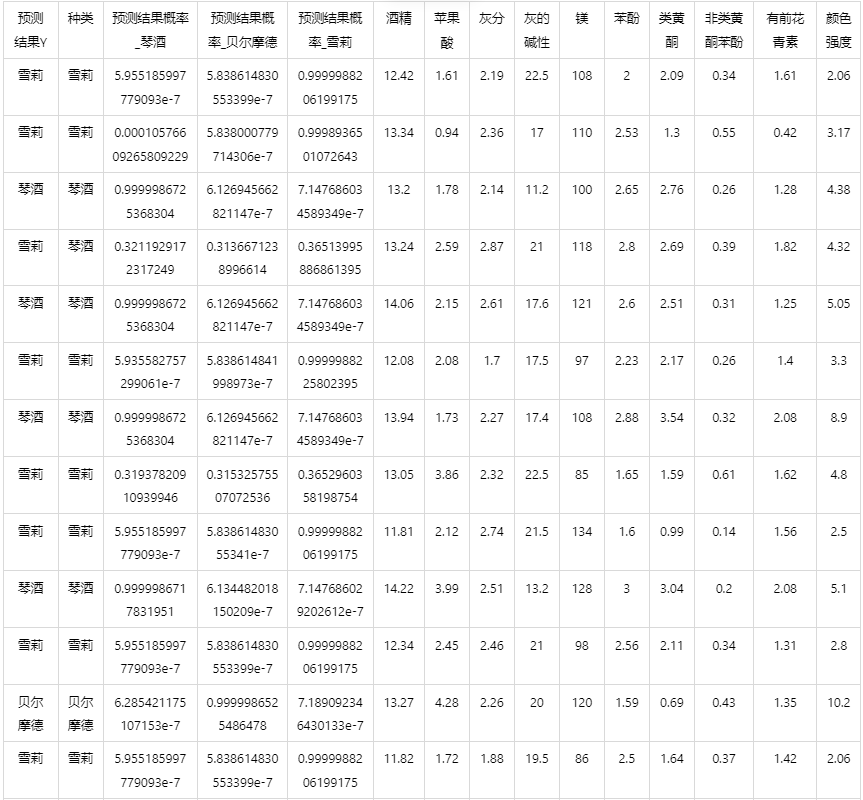
图表说明: 上表格为预览结果,只显示部分数据,全部数据请点击下载按钮导出。
上表展示了 gbdt 模型对测试数据的分类结果,第一列是预测结果,第二列是因变量真实值,第三、四、五列分别是对所属每一个分类水平概率的预测结果,最终分类预测结果值是拥有最大预测概率的分类组别。
输出结果 6:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
● 当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
● 当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况 1:在上面模型评估后,模型分类结果较好,具有实用性,这时我们将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
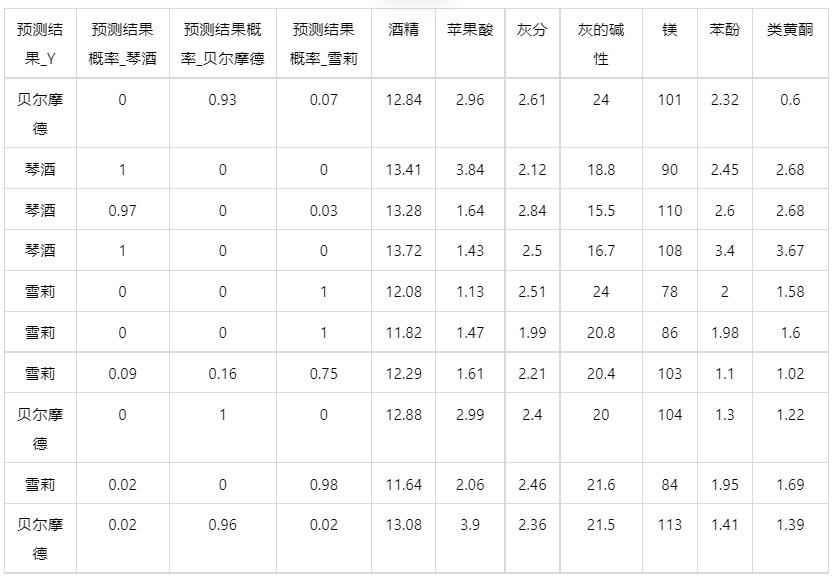
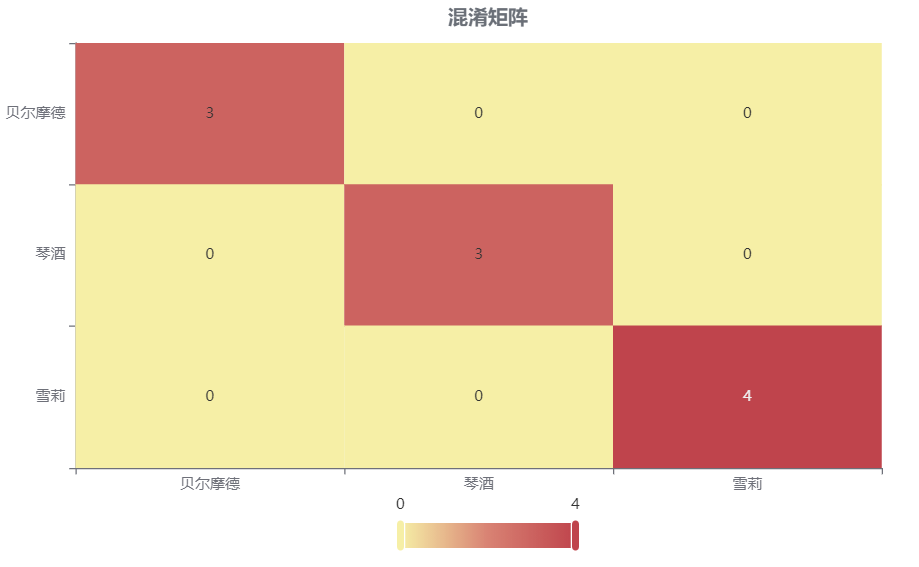
情况 2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到当前数据分类混淆矩阵和分类评价效果。

# 7、注意事项
- 由于 GBDT 具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用 SPSSPRO 客户端进行。
- GBDT 的参数修改需要使用 SPSSPRO 客户端进行。
# 8、模型理论
GBDT 是以 CART 回归树为基学习器的 Boosting 算法。GBDT 由 Friedman 提出,主要解决一般损失函数的优化问题,其核心思想是通过损失函数的负梯度拟合前一轮基学习器的残差,使每一轮的残差估计逐渐减小,因此每一轮基学习器的输出逐渐逼近真值; 负梯度方向上拟合,可以保证每轮训练都能让损失函数尽可能快减小,加速收敛到局部或全局最优解。
算法实现:
模型输入:训练集 T= {(x1,y1),(x2,y2),…,(xN,yN)},损失函数 L(y,f(x))。 
式中:N 表示样本数量,M 表示回归树数量,J 表示回归树叶子节点数量,I(x)表示用于判断集合中元素的指示函数,θ 表示超越参数。
# 9、手推步骤
现有4个样本,两列特征分别为年龄和体重,label为身高是否大于1.5米,具体数据情况如下表:
| 编号 | 年龄 | 体重 | label |
|---|---|---|---|
| 0 | 5 | 20 | 0 |
| 1 | 7 | 30 | 0 |
| 2 | 21 | 70 | 1 |
| 3 | 30 | 60 | 1 |
测试数据集:1个样本,需要预测其身高是否大于1.5米,具体数据情况如下:
| 编号 | 年龄 | 体重 | label |
|---|---|---|---|
| 0 | 25 | 65 | ? |
应用GBDT分类算法求解过程如下:
step1:设置参数
学习器个数 m = 2
树深 max_depth = 3
step2:初始化学习器
这里4个样本的初始值均为0。
step3:计算负梯度
sigmoid函数:
| 编号 | y | F₀(x) | sigmoid(F₀) | 负梯度 (r₁) |
|---|---|---|---|---|
| 0 | 0 | 0 | 0.5 | -0.5 |
| 1 | 0 | 0 | 0.5 | -0.5 |
| 2 | 1 | 0 | 0.5 | 0.5 |
| 3 | 1 | 0 | 0.5 | 0.5 |
step4:构建CART树
分裂过程:
根节点分裂:年龄<=14
● 左节点:样本0,1
● 右节点:样本2,3
左节点继续分裂:体重<=25
● 左左节点:样本0
● 左右节点:样本1
右节点继续分裂:体重<=65
● 右左节点:样本3
● 右右节点:样本2
step5:第一轮迭代
计算每个叶节点的拟合值:
叶节点1(样本0):
● 负梯度:[-0.5]
● 分子 = -0.5
● 分母 =
● 拟合值 =
叶节点2(样本1):
● 负梯度:[-0.5]
● 分子 = -0.5
● 分母 =
● 拟合值 =
叶节点3(样本3):
● 负梯度:[0.5]
● 分子 = 0.5
● 分母 =
● 拟合值 =
叶节点4(样本2):
● 负梯度:[0.5]
● 分子 = 0.5
● 分母 =
● 拟合值 =
更新模型:
| 编号 | F₀(x) | f₁(x) | F₁(x) |
|---|---|---|---|
| 0 | 0 | -2.0 | -2.0 |
| 1 | 0 | -2.0 | -2.0 |
| 2 | 0 | 2.0 | 2.0 |
| 3 | 0 | 2.0 | 2.0 |
step:6:第二轮迭代
计算负梯度
| 编号 | y | F₁(x) | sigmoid(F₁) | 负梯度 (r₂) |
|---|---|---|---|---|
| 0 | 0 | -2.0 | 0.1192 | -0.1192 |
| 1 | 0 | -2.0 | 0.1192 | -0.1192 |
| 2 | 1 | 2.0 | 0.8808 | 0.1192 |
| 3 | 1 | 2.0 | 0.8808 | 0.1192 |
计算每个叶节点的拟合值:
叶节点1(样本0):
● 负梯度:[-0.1192]
● 分子 = -0.1192
● 分母 =
● 拟合值
叶节点2(样本1):
● 负梯度:[-0.1192]
● 分子 = -0.1192
● 分母 =
● 拟合值
叶节点3(样本3):
● 负梯度:[0.1192]
● 分子 = 0.1192
● 分母 =
● 拟合值
叶节点4(样本2):
● 负梯度:[0.1192]
● 分子 = 0.1192
● 分母 =
● 拟合值
更新模型:
| 编号 | F₁(x) | f₂(x) | F₂(x) |
|---|---|---|---|
| 0 | -2.0 | -1.135 | -3.135 |
| 1 | -2.0 | -1.135 | -3.135 |
| 2 | 2.0 | 1.135 | 3.135 |
| 3 | 2.0 | 1.135 | 3.135 |
step7:组合强学习器
step8:预测样本结果
预测样本(年龄=25,体重=65)
预测路径:
● 年龄=25 > 14 → 进入右子树
● 体重=65 ≤ 65 → 进入右左节点(样本3所在的节点)
两棵树的预测值:
● 第一棵树:
● 第二棵树:
最终预测:
预测结果:概率为0.958 > 0.5,预测为类别1,即身高大于1.5米。
# 10、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]He X , Pan J , Ou J , et al. Practical Lessons from Predicting Clicks on Ads at Facebook[M]. ACM, 2014.