K近邻(KNN)分类
# 1、作用
K近邻(KNN)分类器是有监督学习中普遍使用的分类器之一,将观察值的分类判定为离它最近的k个观察值中所占比例最大的分类。
# 2、输入输出描述
输入:自变量X为1个或1个以上的定类或定量变量,因变量Y为一个定类变量。
输出:模型的分类结果和模型分类的评价效果。
# 3、案例示例
根据高质量人类,精英人士与普通人3个类别的收入、年龄和学历训练一个KNN分类器,用于对一个新用户进行分类。
# 4、案例数据
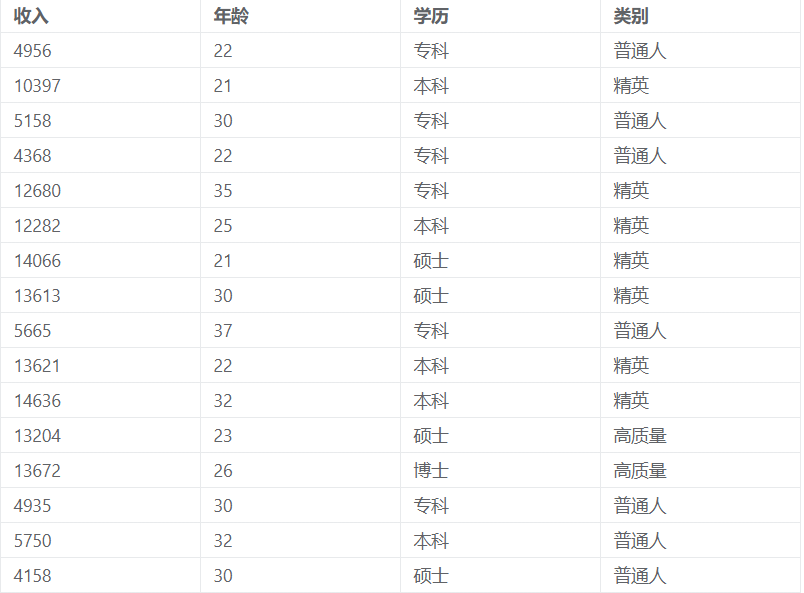
KNN分类案例数据
# 5、案例操作
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;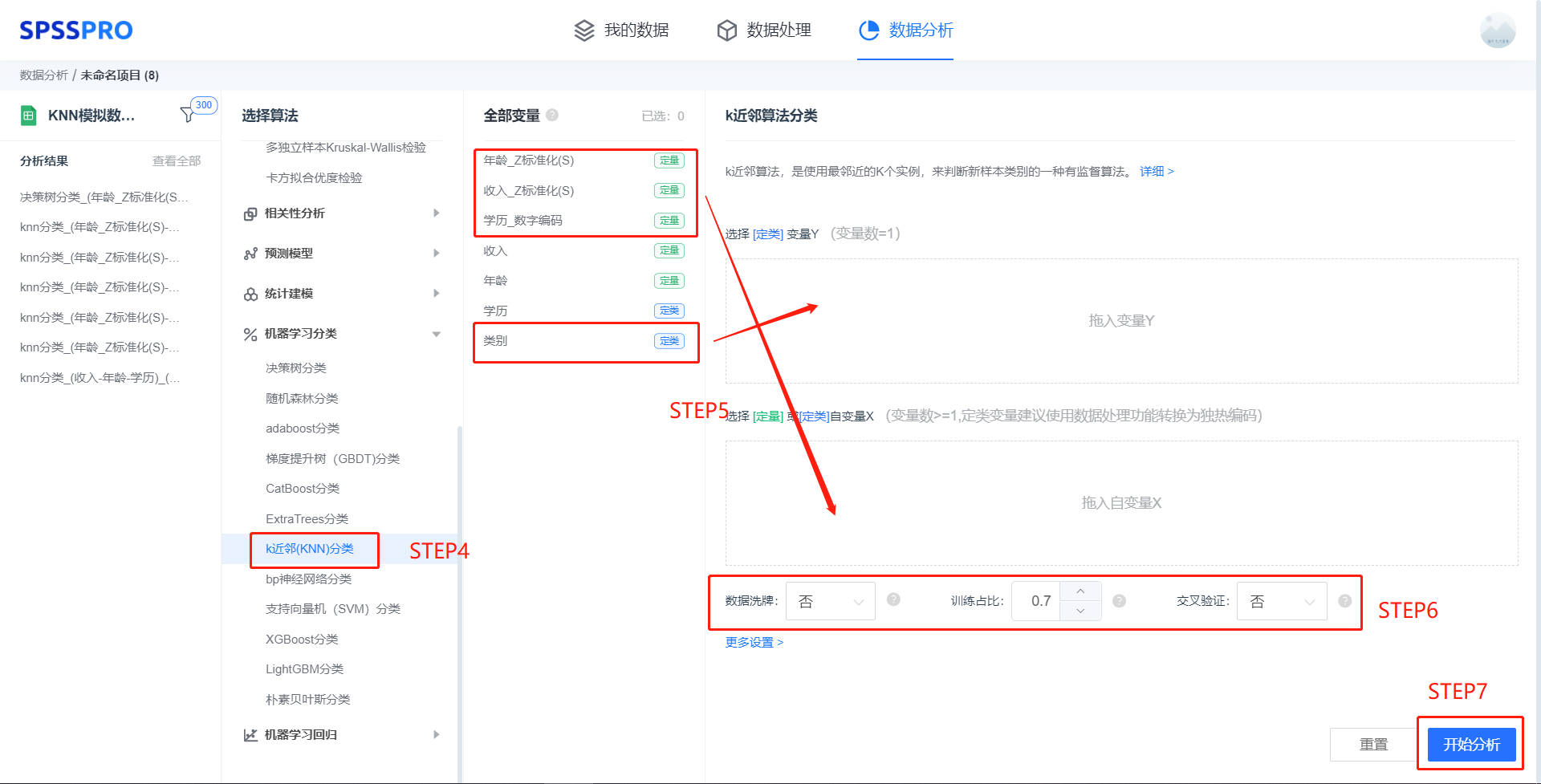
step4:选择【K近邻分类】;
step5:查看对应的数据数据格式,按要求输入【K近邻分类】数据(注:K近邻中定类变量建议进行编码,定量变量建议标准化);
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果1:模型参数
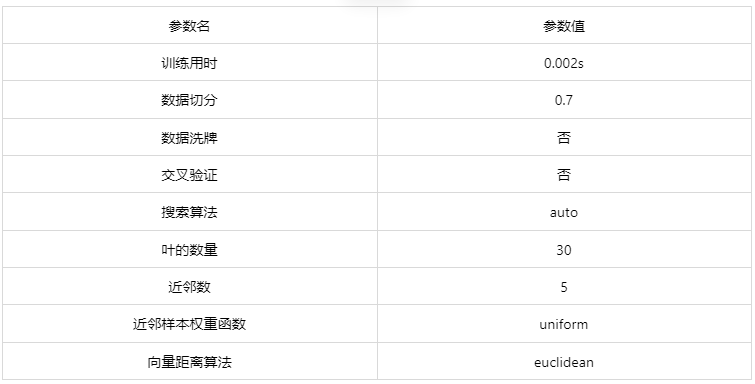
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
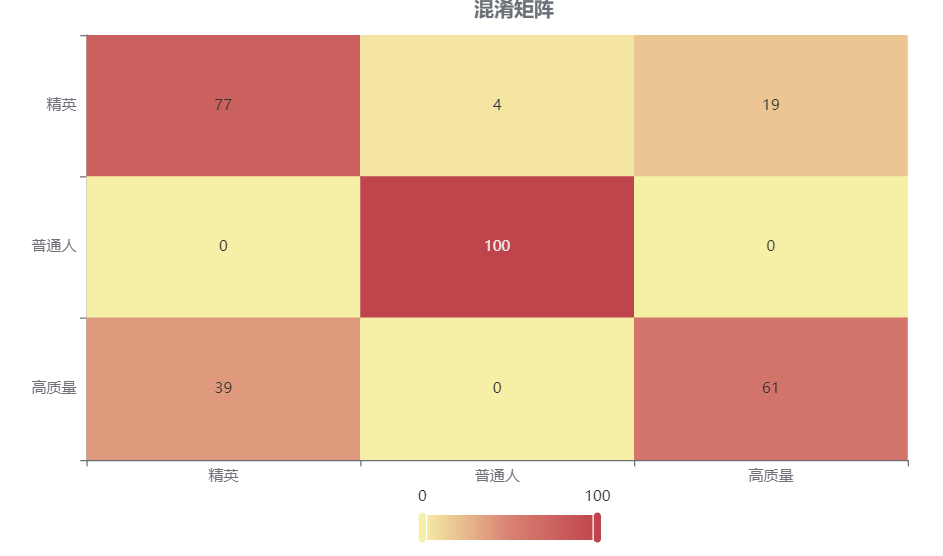
输出结果2:混淆矩阵热力图
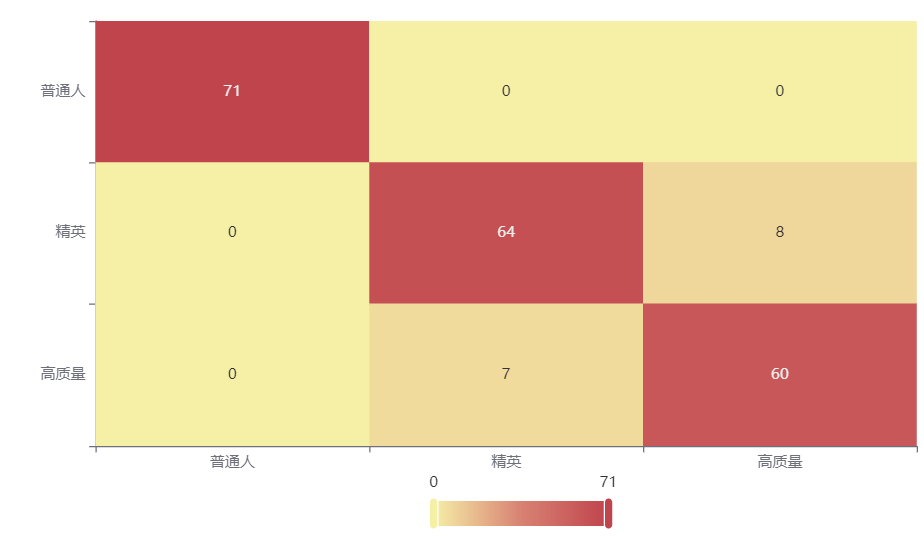
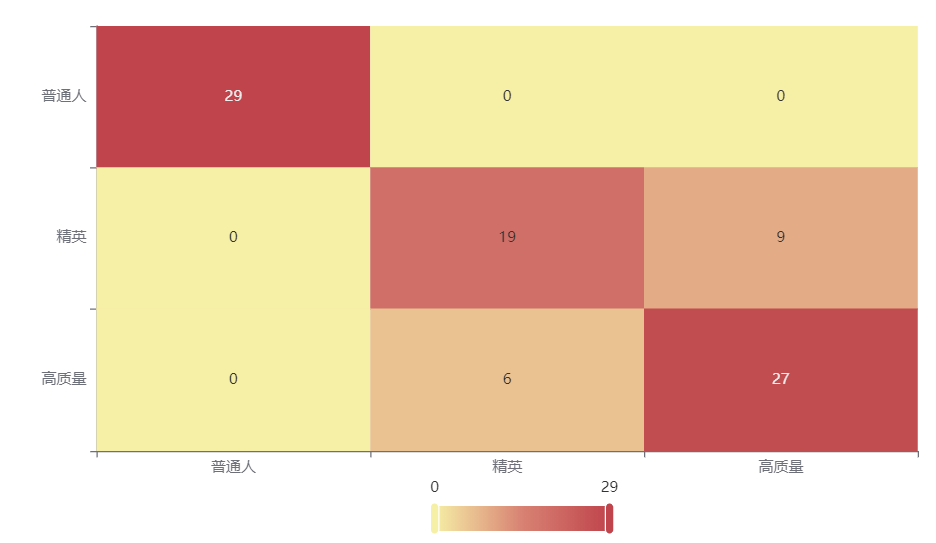
图表说明: 上表以热力图的形式展示了混淆矩阵,可以通过右上角切换在测试数据集和训练数据集中的情况。
分析:
上图是训练集的分类结果,只有15个样本被误分类,说明分类效果优秀。
下图是测试集的分类结果,有15个样本被误分类,说明训练集训练出来的模型结果是有效实用的。
输出结果4:模型评估结果
图表说明: 上表中展示了训练集和测试集的分类评价指标,通过量化指标来衡量K近邻对训练、测试数据的分类效果。
● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用F1指标。
分析:
训练集的各分类评价指标都大于0.95,说明模型在训练集的分类效果极好,模型具有实用性。
测试集的各分类评价指标都大于0.95,说明模型在测试集的分类效果极好,模型具有实用性。
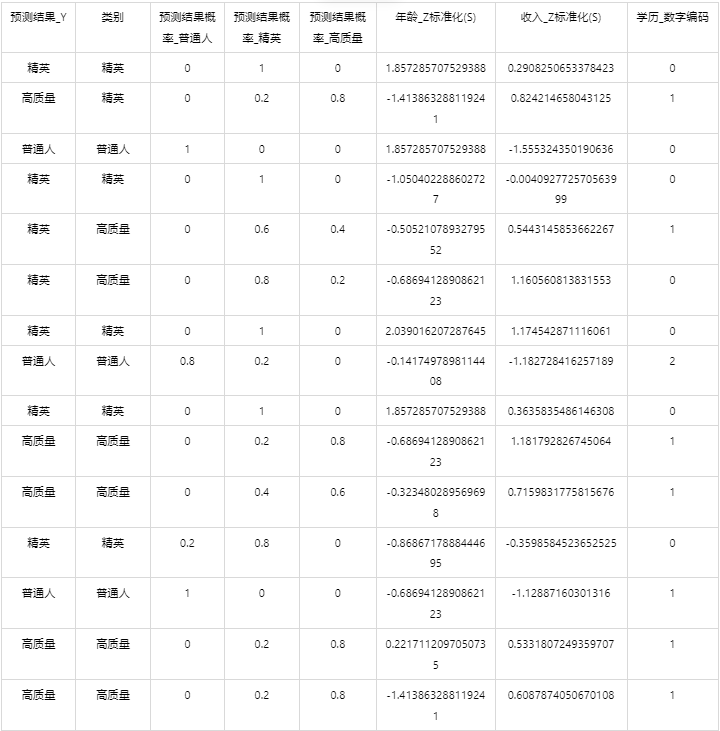
输出结果5:测试数据预测评估结果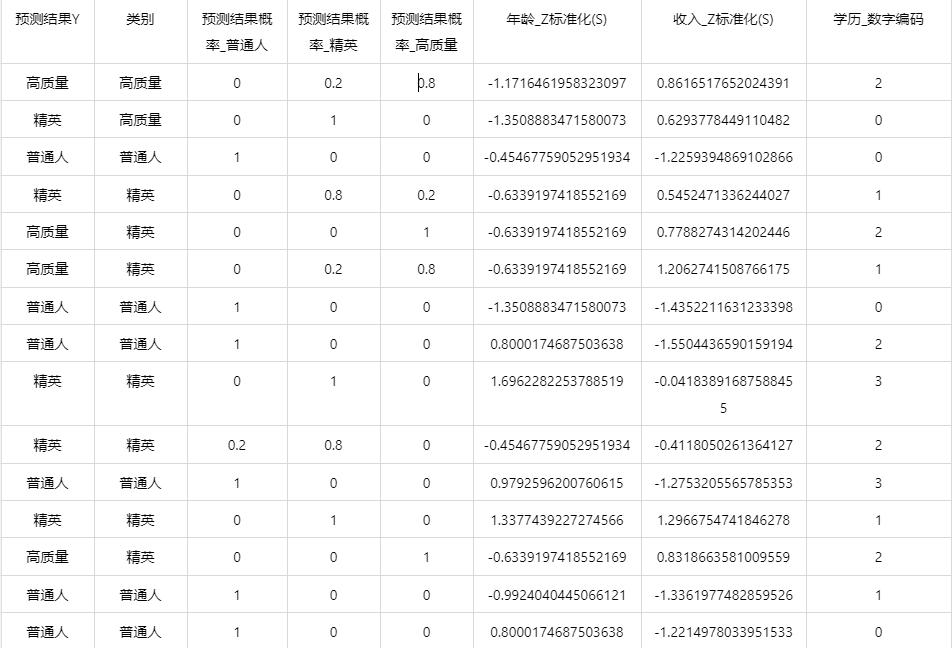
图表说明: 上表格为预览结果,只显示部分数据,全部数据请点击下载按钮导出。
上表展示了K近邻模型对测试数据的分类结果,第一列是预测结果,第二列是因变量真实值,第三、四、五列分别是对所属每一个分类水平概率的预测结果,最终分类预测结果值是拥有最大预测概率的分类组别。
输出结果6:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
●当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
●当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况1:在上面模型评估后,模型分类结果较好,具有实用性,这时我们将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
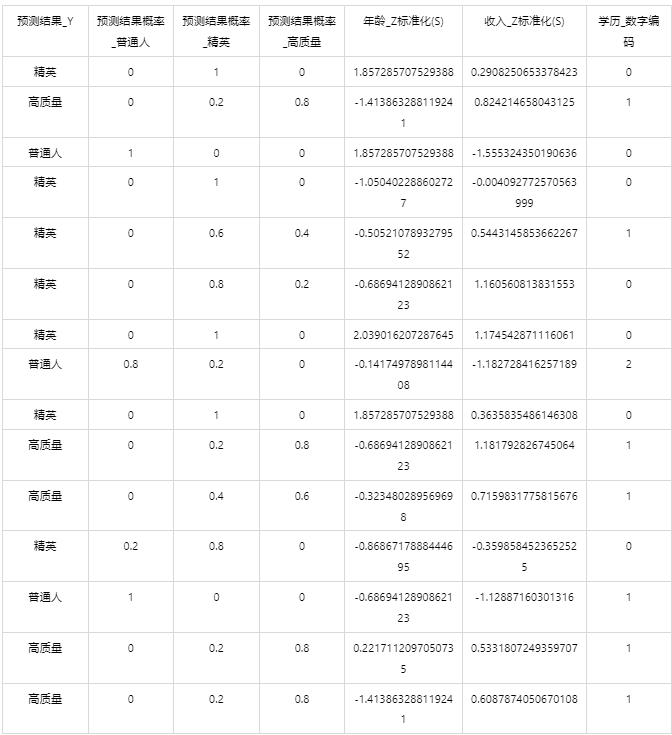
情况2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到当前数据分类混淆矩阵和分类评价效果。

# 7、注意事项
- 若在训练划分时对数据进行洗牌打乱数据顺序,会导致K近邻具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用SPSSPRO客户端进行。
- K近邻的参数修改需要使用SPSSPRO客户端进行。
# 8、模型理论
# 1、介绍
KNN(K Nearest Neighbor)即K最邻近,是有监督学习中较为通俗易懂的分类算法。KNN的核心思想很简单,即近朱者赤、近墨者黑,通过K个最近的实例投票决定新实例的类别,它不同于贝叶斯、决策树等算法,KNN不需要训练,在类边界比较整齐的情况下分类的准确率很高。
# 2、原理
KNN的原理就是当预测一个新的实例的时候,根据它距离最近的K个点是什么类别来判断它属于哪个类别。KNN算法需要人为决定K的取值,即找几个最近的实例,K值不同,分类结果的结果也会不同。
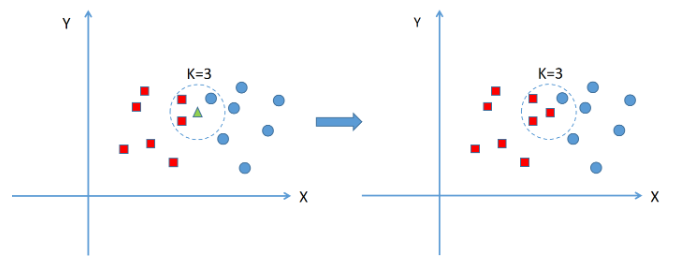
上图中绿色的点是一个新的实例,假设K=3,这里假设距离为欧氏距离,KNN算法以绿点为中心画圆,确定一个最小的半径,使这个圆包含K=3个点(虚线圆圈内),实例最多的类别就是新实例的类别,可以看到圈内的三个点中,红色方形类别有2个,蓝色圆形类别有1个,因此新的绿色实例就归类到红色方形类。
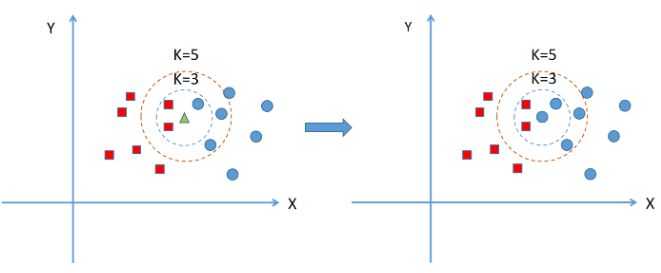
当K=5时,范围内蓝色圆形类别有3个,红色方形类别有2个,因此绿点的新实例被归类成蓝色圆形。
# 3、距离计算
在KNN算法中,常用的距离有三种,分别为欧氏距离、曼哈顿距离和闵可夫斯基距离。假设数据是n维的,空间中任意两个点
● 这里
● 当
● 当
# 4、K值选择
K值的选择非常重要,K太小,分类结果易受噪声点影响,误差会增大;K太大,近邻中又可能包含太多的其它类别的点(对距离加权,可以降低K值设定的影响);K=N(样本数),此时无论输入实例是什么,都只是简单的预测它属于训练集中最多的类,模型过于简单,忽略了大量有用信息。 在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法来选择最优的K值。K一般低于训练样本数的平方根。
# 5、算法过程
- 计算测试数据与各个训练数据之间的距离;
- 按照距离的递增关系进行排序;
- 选取距离最小的K个点;
- 确定前K个点所在类别的出现频率;
- 返回前K个点中出现频率最高的类别作为测试数据的预测分类。
# 6、KNN算法的优缺点
优点:
- 简单易用,相比其他算法,KNN更简洁明了;
- 模型训练时间快;
- 预测效果好;
- 对异常值不敏感。 缺点:
- 对内存要求较高,因为该算法存储了所有训练数据;
- 预测阶段较慢;
- 对不相关的功能和数据规模敏感。
# 9、手推步骤
| 身高(cm) | 体重(kg) | 性别 |
|---|---|---|
| 185 | 75 | 男 |
| 175 | 63 | 男 |
| 170 | 55 | 男 |
| 165 | 50 | 女 |
| 160 | 46 | 女 |
| 178 | 63 | 男 |
| 174 | 55 | 女 |
| 169 | 49 | 女 |
| 153 | 45 | 女 |
现有一组数据包含人的身高、体重和性别。
假设要预测一个新样本的性别,身高 = 172 cm,体重 = 58 kg。KNN分类算法求解过程如下:
step1:确定K值
为了避免平票情况,k值通常取奇数。这里选择k=5。
step2:计算欧氏距离
这里选择欧氏距离求解。
新样本 P=(172,58)。
1.(185,75)
2.(175,63)
3.(170,55)
4.(165,50)
5.(160,46)
6.(178,63)
7.(174,55)
8.(169,49)
9.(153,45)
step3:取k=5最近邻
距离从小到大排序:
1.
2.
3.
4.
5.
step4:根据最近邻投票
5个最近邻的性别分别是男、女、男、男、女。
男(3),女(2)
则预测新样本的性别为男。
# 10、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]Hall P, Park BU, Samworth RJ. Choice of neighbor order in nearest-neighbor classification. Annals of Statistics. 2008, 36 (5): 2135–2152. doi:10.1214/07-AOS537.
[3]Everitt, B. S., Landau, S., Leese, M. and Stahl, D.(2011)Miscellaneous Clustering Methods, in Cluster Analysis, 5th Edition, John Wiley & Sons, Ltd, Chichester, UK.
[4]Wiki.K-近邻算法[EB/OL].https://zh.wikipedia.org/wiki/K-%E8%BF%91%E9%82%BB%E7%AE%97%E6%B3%95 (opens new window)