支持向量机(SVM)分类
# 1、作用
支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。
# 2、输入输出描述
输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定类变量。
输出:模型的分类结果和模型分类的评价效果。
# 3、案例示例
有一批 Iris 花,已知这批 Iris 花可分为 3 个品种,现需要对其进行分类。根据花萼长度、花萼宽度、花瓣长度、花瓣宽度的数据。用已有的数据训练一个支持向量机用作分类器。
# 4、案例数据
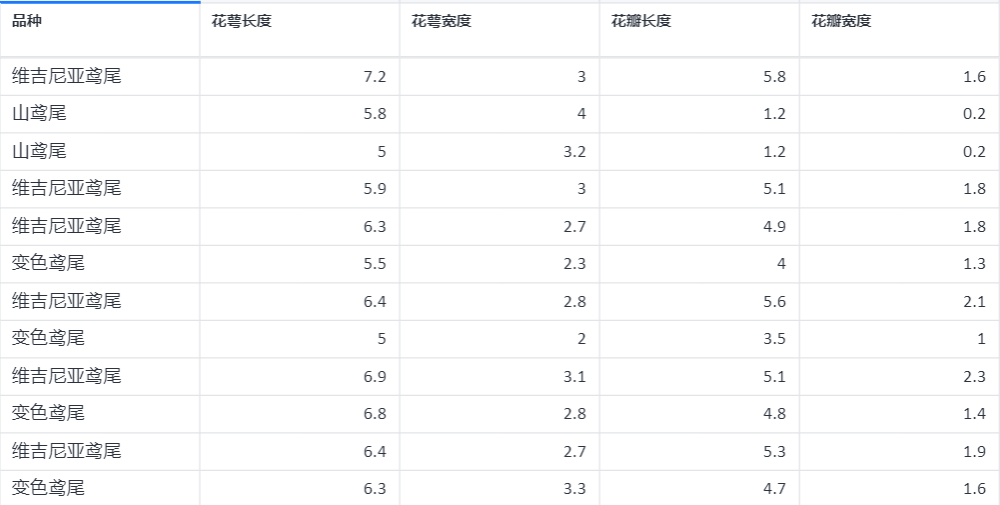
支持向量机分类案例数据
# 5、案例操作
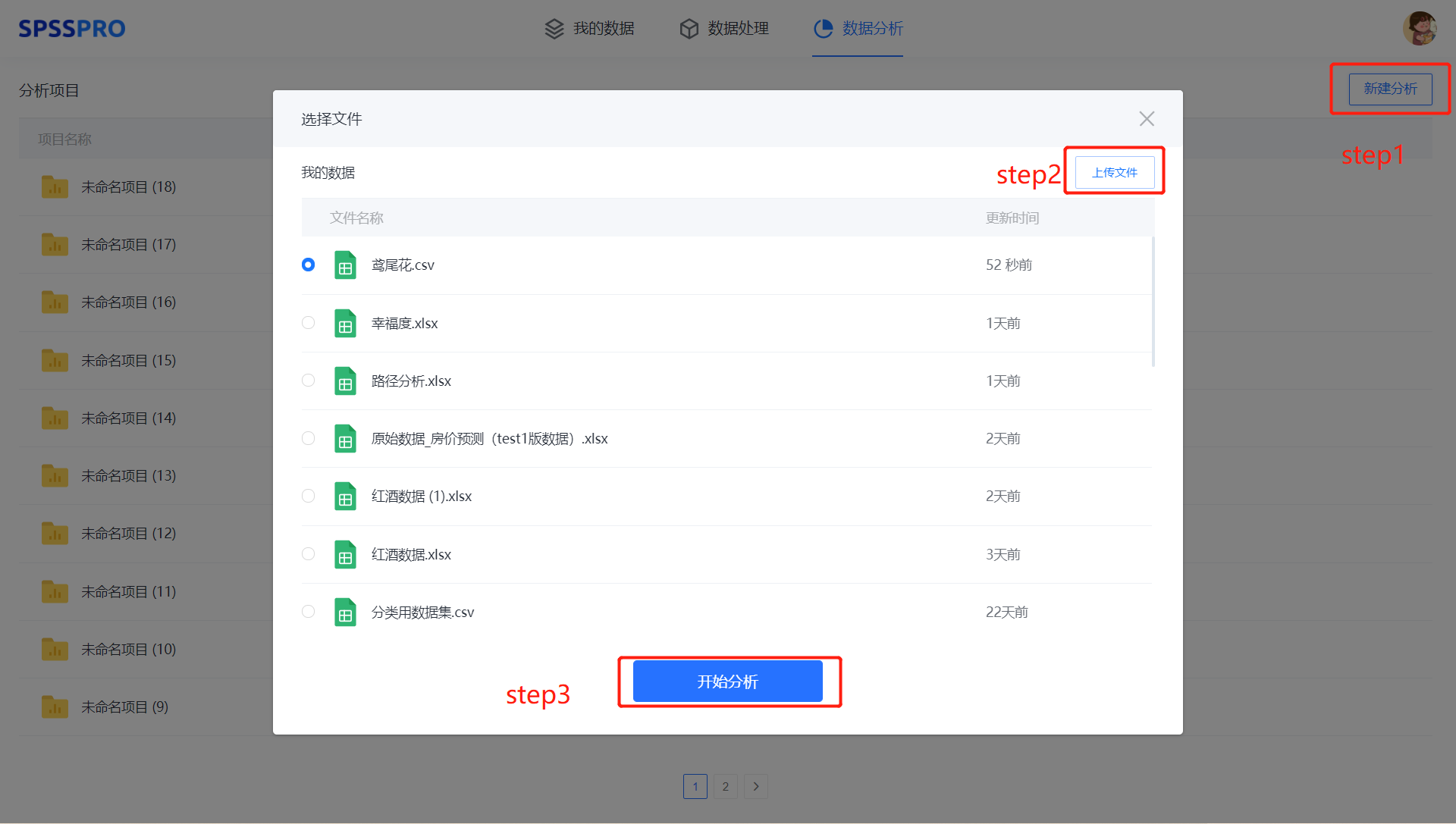
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;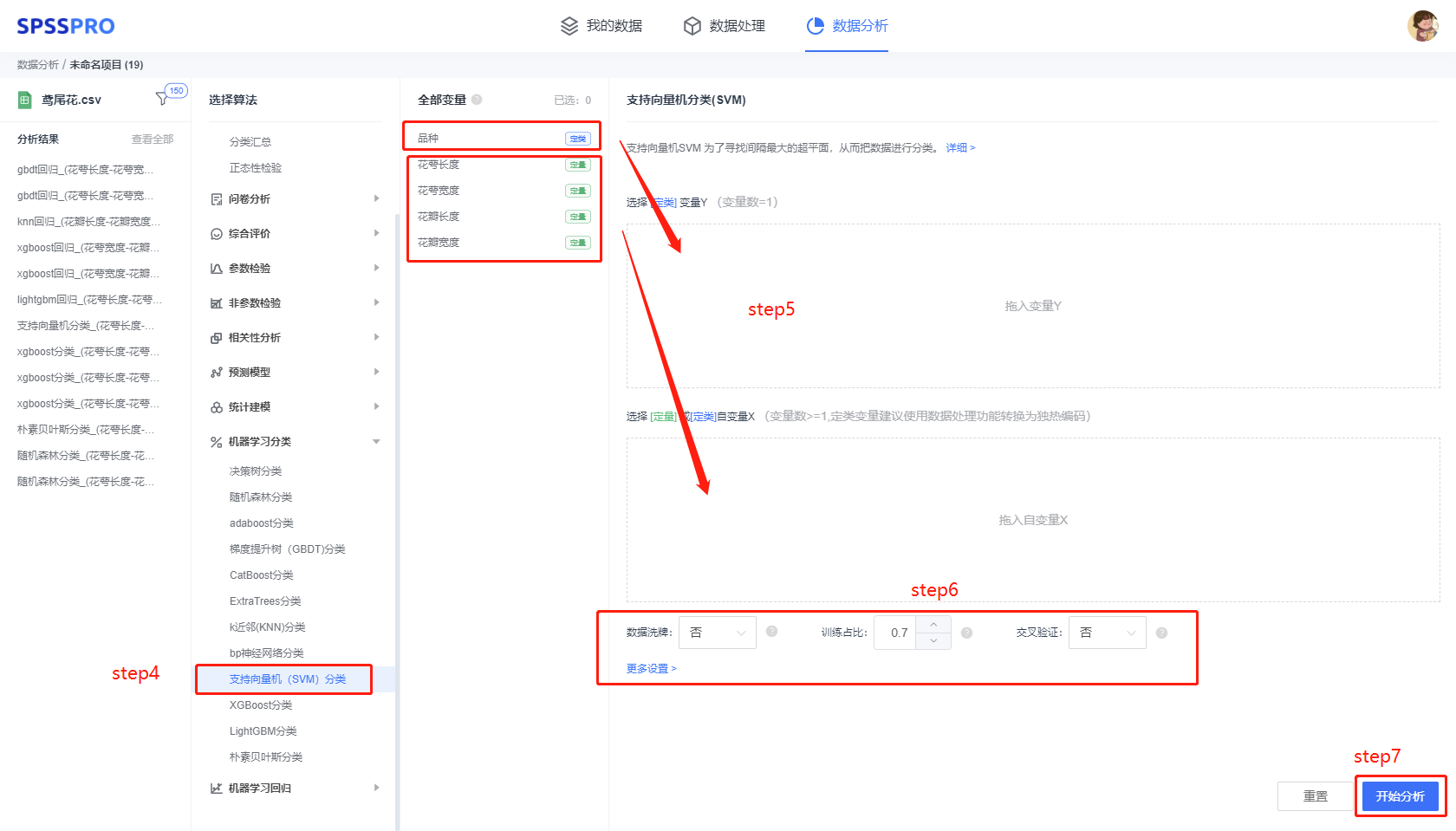
step4:选择【支持向量机分类】;
step5:查看对应的数据数据格式,按要求输入【支持向量机分类】数据;
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step7:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:模型参数 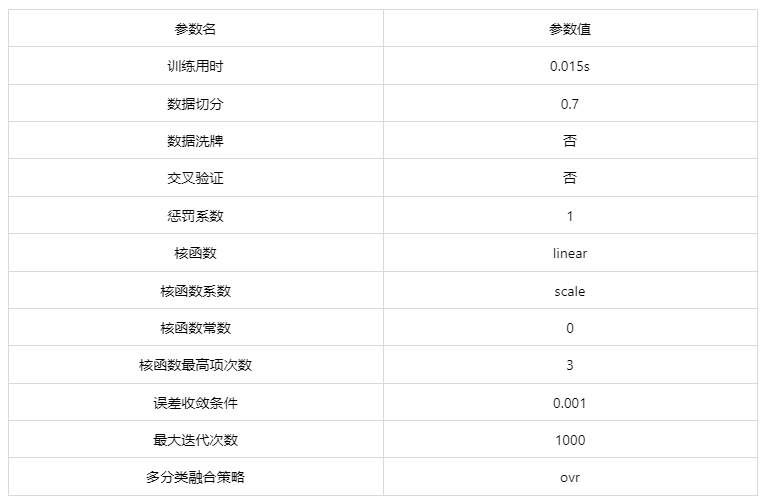
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
输出结果 2:混淆矩阵热力图
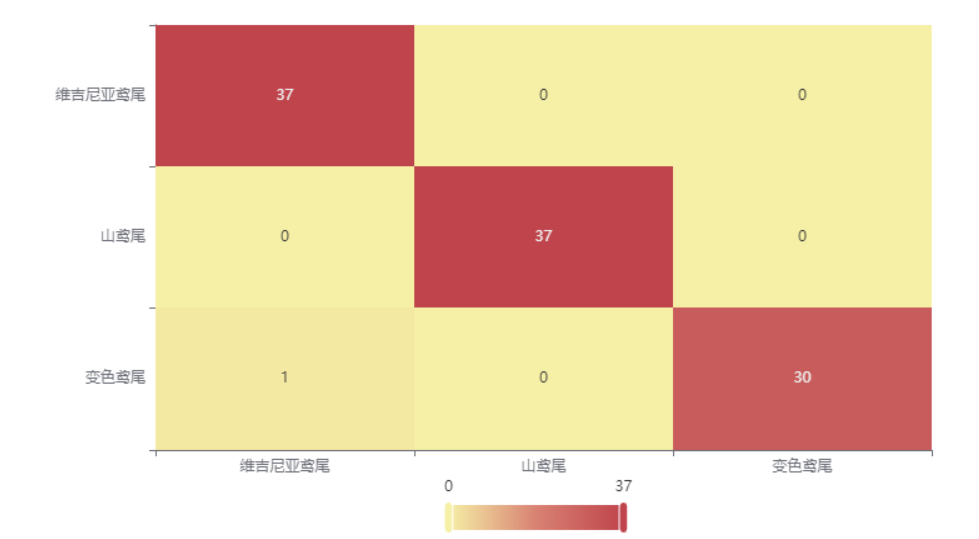
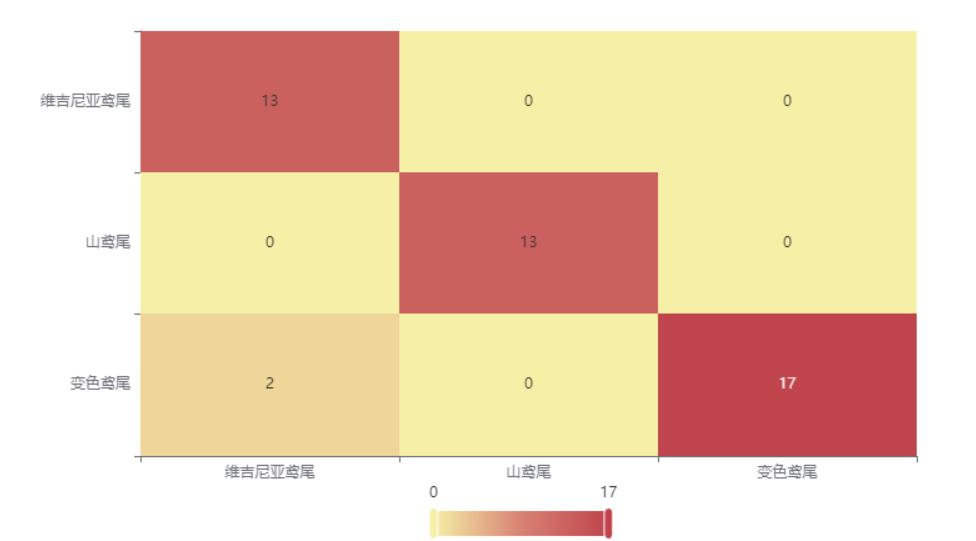
图表说明: 上表以热力图的形式展示了混淆矩阵,可以通过右上角切换在测试数据集和训练数据集中的情况。
分析:
上图是训练集的分类结果,绝大部分样本分类正确,只有 1 个被分错的样本,说明分类效果较好。
下图是测试集的分类结果,绝大部分样本分类正确,只有 2 个被分错的样本,说明训练集训练出来的模型结果是有效实用的,分类效果较好。
输出结果 3:模型评估结果
图表说明: 上表中展示了训练集和测试集的分类评价指标,通过量化指标来衡量支持向量机对训练、测试数据的分类效果。
● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用 F1 指标。
分析:
训练集的各分类评价指标都大于 0.9,说明模型在训练集的分类效果较好,模型具有实用性。
测试集的各分类评价指标都大于 0.9,说明模型在测试集的分类效果较好,模型具有实用性。
输出结果 4:测试数据预测评估结果
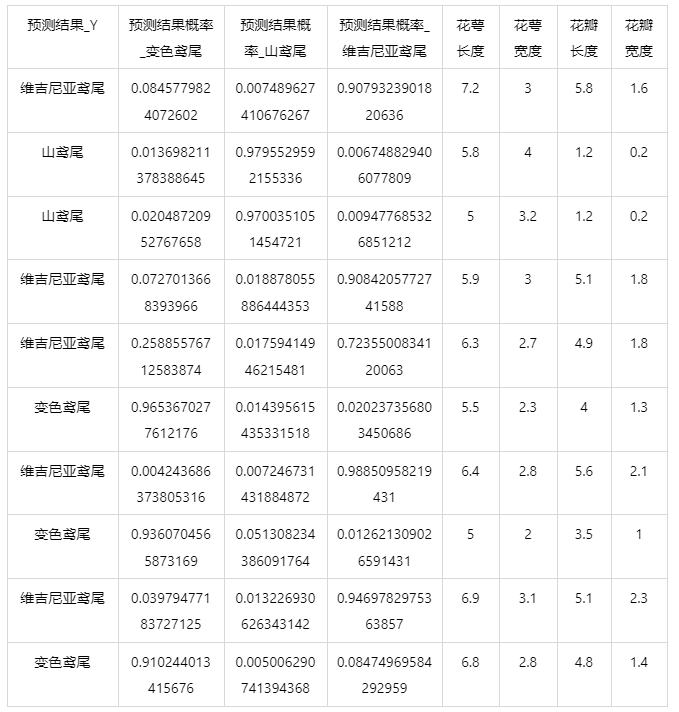
图表说明: 上表格为预览结果,只显示部分数据,全部数据请点击下载按钮导出。
上表展示了支持向量机模型对测试数据的分类结果,第一列是预测结果,第二列是因变量真实值,第三、四、五列分别是对所属每一个分类水平概率的预测结果,最终分类预测结果值是拥有最大预测概率的分类组别。其余列是各自变量的值。
输出结果 6:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
● 当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
● 当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况 1:在上面模型评估后,模型分类结果较好,具有实用性,这时我们将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
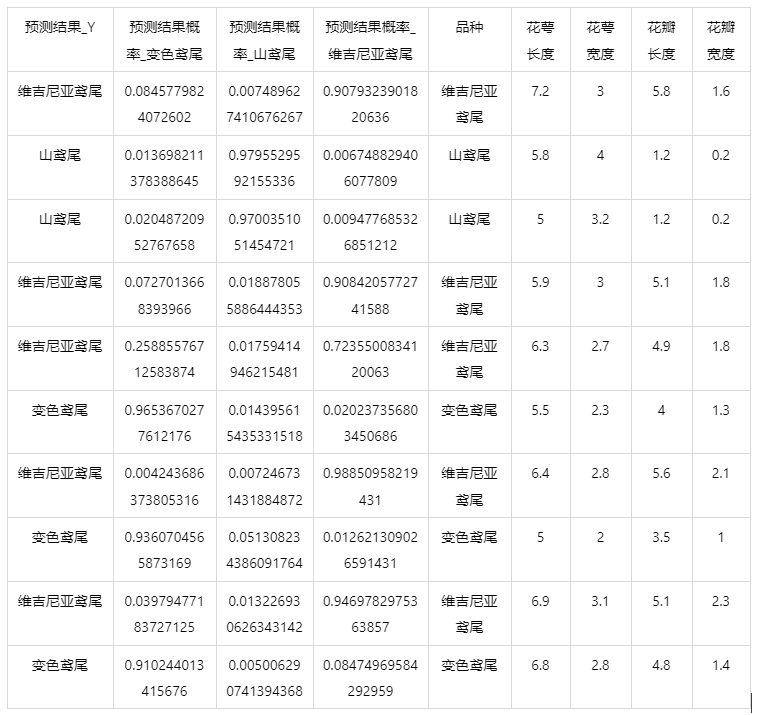
情况 2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到当前数据分类混淆矩阵和分类评价效果。


# 7、注意事项
- 由于支持向量机具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用 SPSSPRO 客户端进行。
- 支持向量机的参数修改需要使用 SPSSPRO 客户端进行。
# 8、模型理论
SVM 想要的就是找到各类样本点到超平面的距离最远,也就是找到最大间隔超平面。
任意超平面可以用下面这个线性方程来描述:![]()
建立最优化问题如下 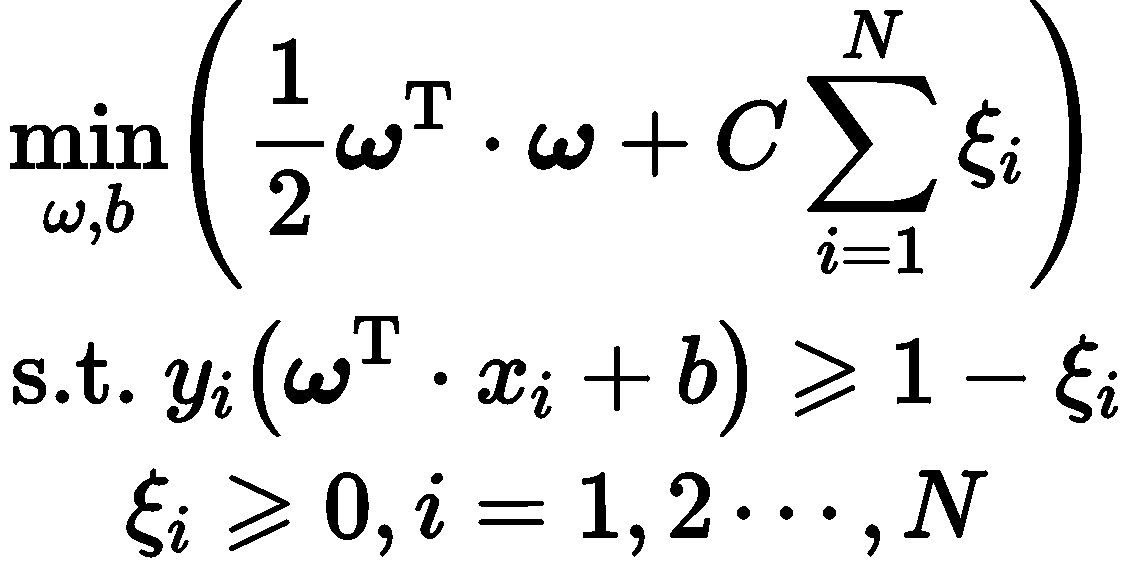
式中:ω 为法向量;b 为常数项;C 为惩罚因子;ξi 为松弛变量.
找出最优法向量 ω 和常数项 b 的解就可以得 到最优分类面,为了将上式转化为二次规划问题, 引入相应 Lagrange 函数,则分类问题变为 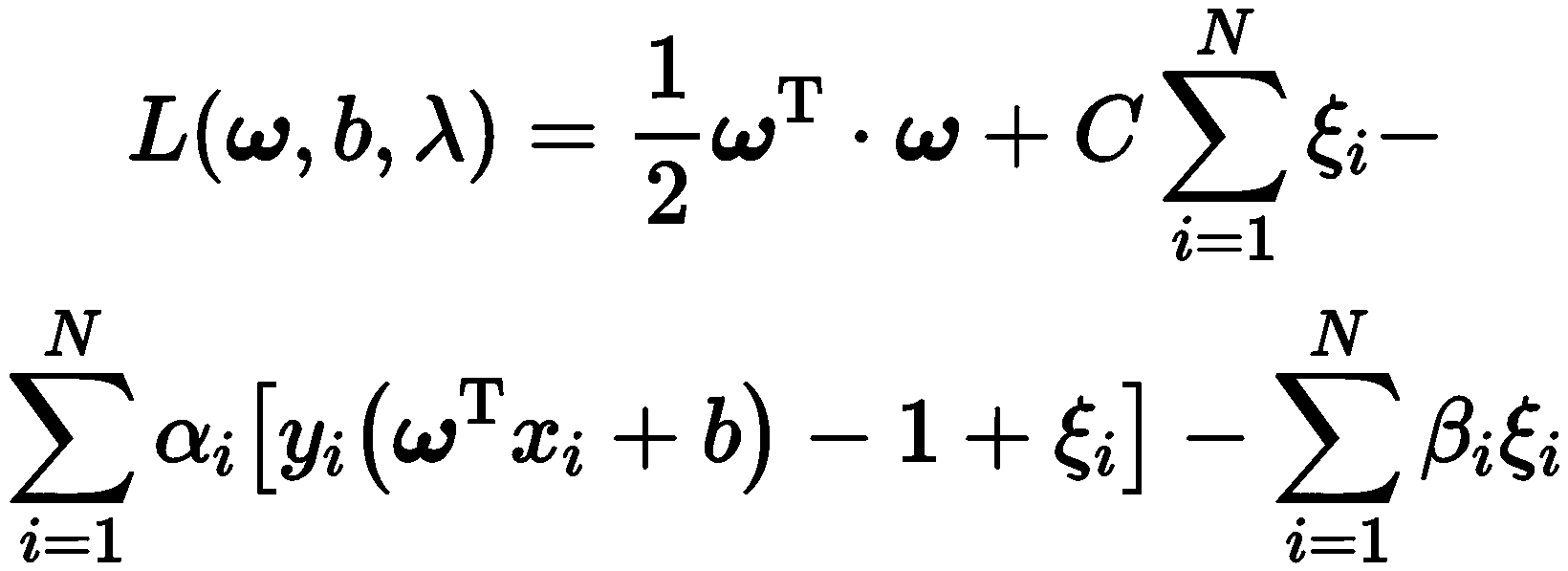
式中:αi,βi 为 Lagrange 乘子,αi≥0,βi≥0.
根据对偶原理,上式可变为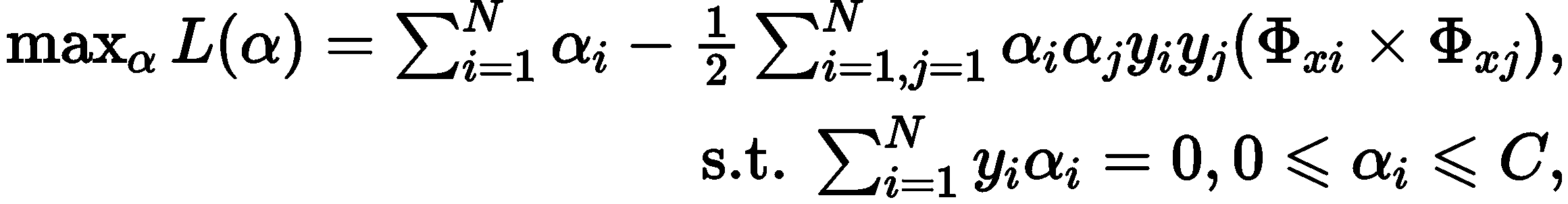
![]() 为核函数。
为核函数。
对于线性不可分问题,支持向量机需引进核函 数把数据从低维空间向高维空间投射,达到线性可 分的目的.常用的核函数有线性核函数、多项式核函数、径向基核函数以及感知器核函数,不同核函数得到的支持向量机形式也不同.
# 9、手推步骤
现有四个数据点,正例点 (3, 3) (4, 3) (10, 10) 负例点 (1, 1) ,用支持向量机求解超平面过程如下:
step1:写出原始问题
step2:引入拉格朗日函数
对每个约束引入拉格朗日乘子
step3:KKT条件
(1)稳定性条件
(2)原始可行性
(3)对偶可行性
step4:写出对偶问题
将
利用
对偶问题:
step5:代入数据
对偶目标函数:
约束:
代入得
对
即
解方程得
观察数据分布:点 (10,10) 远离其他点,不太可能是支持向量,假设
方程组变为
求解得到
假设
所以正例支持向量是
用正例支持向量求解b:
所以最终超平面方程为
# 10、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] 周志华.机器学习.北京:清华大学出版社,2016:pp.121-139, 298-300
[3]李航.统计学习方法.北京:清华大学出版社,2012:第七章,pp.95-135