CatBoost分类
# 1、作用
catboost 是一种基于对称决策树算法的 GBDT 框架,主要解决的痛点是高效合理地处理类别型特征和处理梯度偏差、预测偏移问题,提高算法的准确性和泛化能力。
# 2、输入输出描述
输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定类变量。
输出:模型的分类结果和模型分类的评价效果。
# 3、案例示例
根据红酒的颜色强度,脯氨酸,类黄酮等变量,生成一个能够区分琴酒,雪莉,贝尔摩德三种品种的红酒的 catboost。
# 4、案例数据

catboost 分类案例数据
# 5、案例操作
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
step4:选择【catboost 分类】;
step5:查看对应的数据数据格式,按要求输入【catboost 分类】数据;
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step7:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:模型参数 
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
输出结果 2:特征重要性
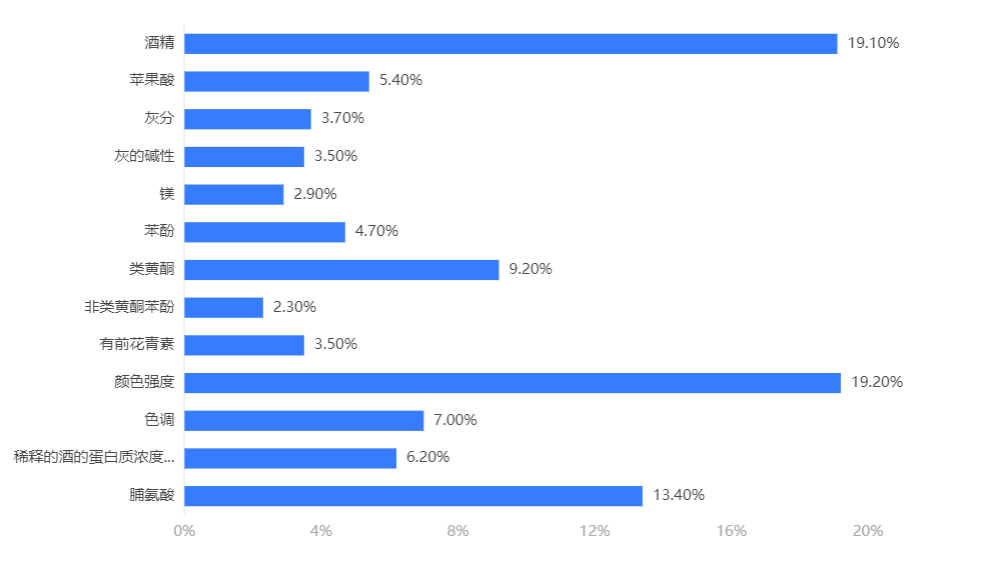
图表说明:上柱形图或表格展示了各特征(自变量)的重要性比例。(附:有时候可以利用特征重要性反推该变量在实际生活中的价值,因为该重要性往往决定分类结果。)
分析:catboost 模型中决定分类结果的重要因素是颜色强度、脯氨酸、酒精。
输出结果 3:混淆矩阵热力图
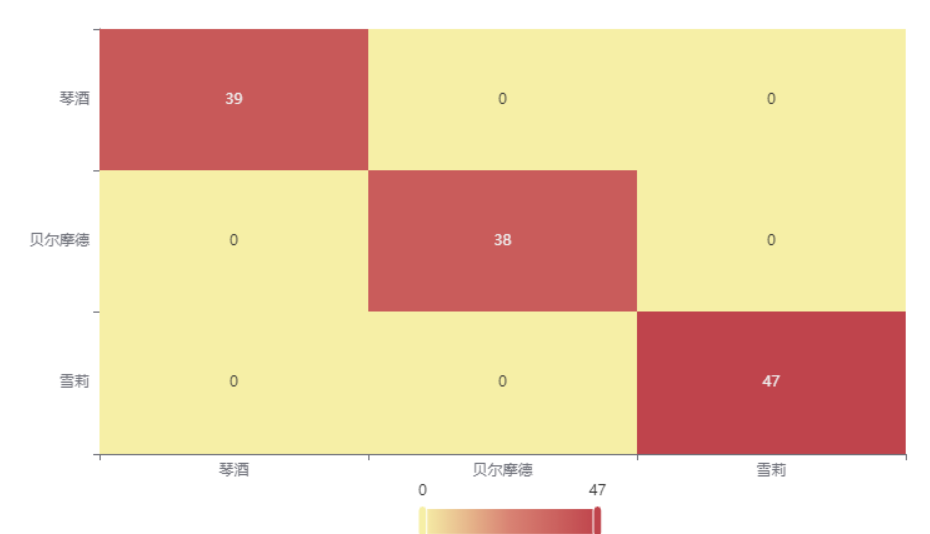
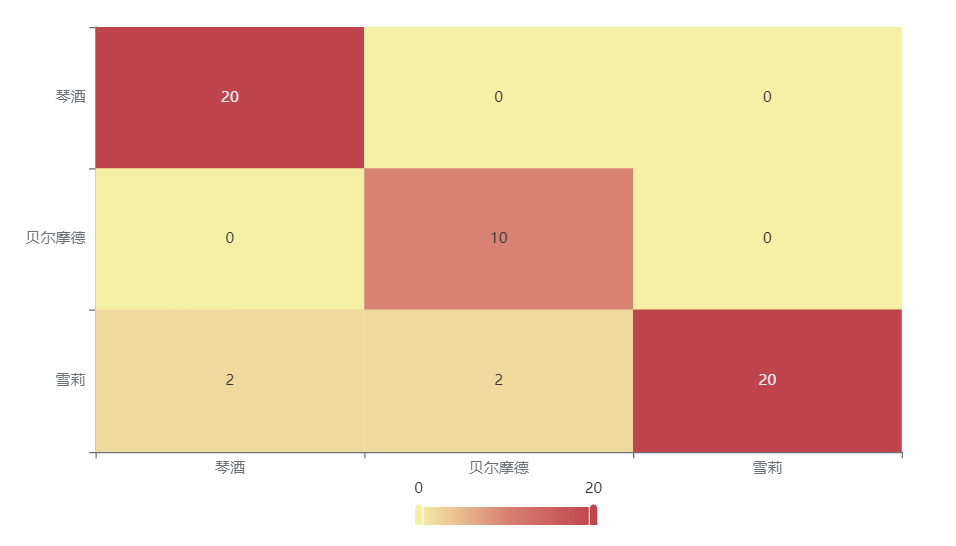
图表说明: 上表以热力图的形式展示了混淆矩阵,可以通过右上角切换在测试数据集和训练数据集中的情况。
分析:
上图是训练集的分类结果,所有样本分类正确,说明分类效果极好。
下图是测试集的分类结果,绝大部分样本分类正确,只有 4 个被分错的样本,说明训练集训练出来的模型结果是有效实用的。
输出结果 4:模型评估结果
图表说明: 上表中展示了训练集和测试集的分类评价指标,通过量化指标来衡量 catboost 对训练、测试数据的分类效果。
● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用 F1 指标。
分析:
训练集的各分类评价指标都大于 0.9,说明模型在训练集的分类效果极好,模型具有实用性。
测试集的各分类评价指标都大于 0.9,说明模型在测试集的分类效果极好,模型具有实用性。
输出结果 5:测试数据预测评估结果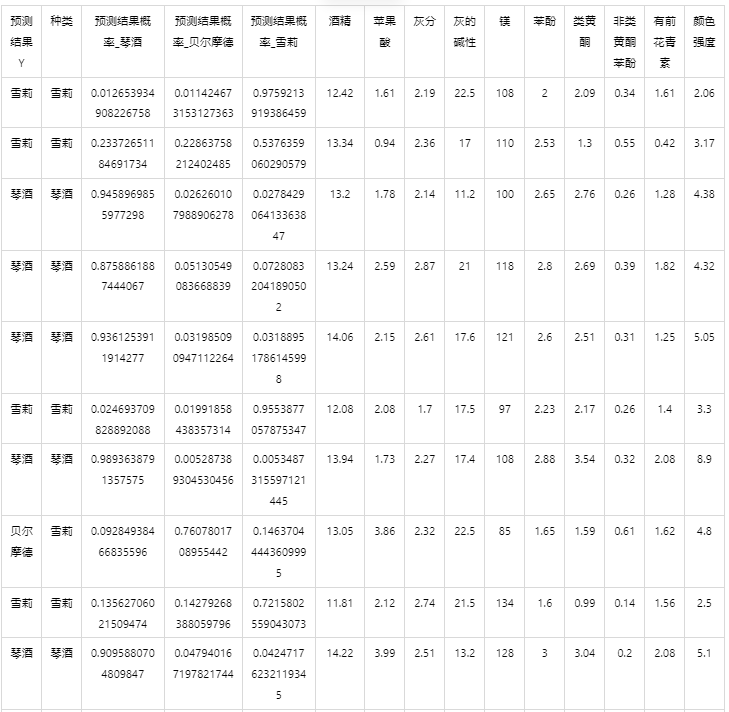
图表说明: 上表格为预览结果,只显示部分数据,全部数据请点击下载按钮导出。
上表展示了 catboost 模型对测试数据的分类结果,第一列是预测结果,第二列是因变量真实值,第三、四、五列分别是对所属每一个分类水平概率的预测结果,最终分类预测结果值是拥有最大预测概率的分类组别。
输出结果 6:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
● 当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
● 当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况 1:在上面模型评估后,模型分类结果较好,具有实用性,这时我们将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
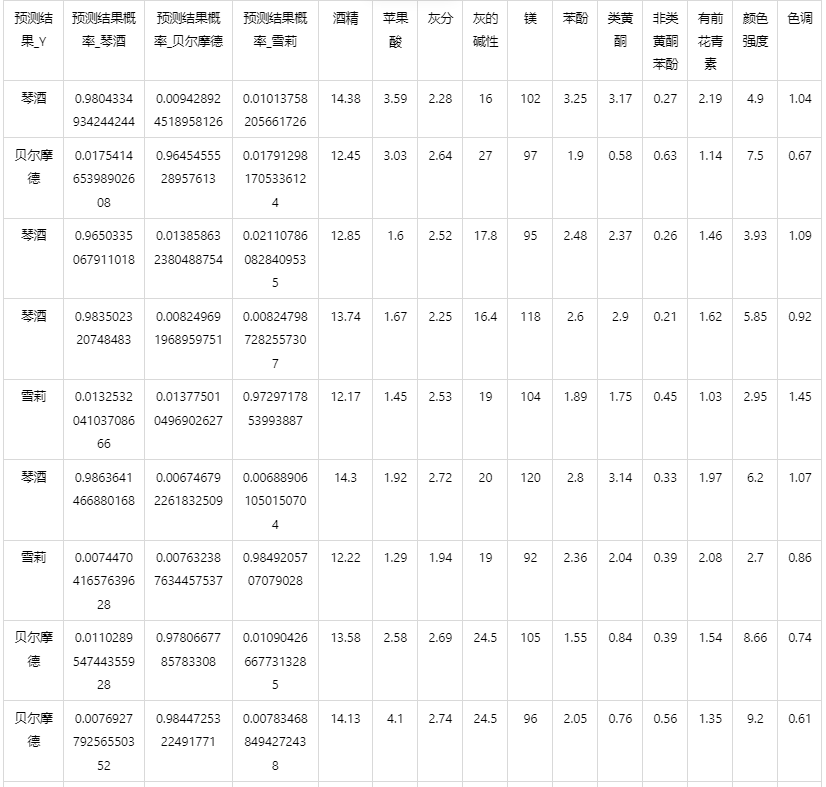
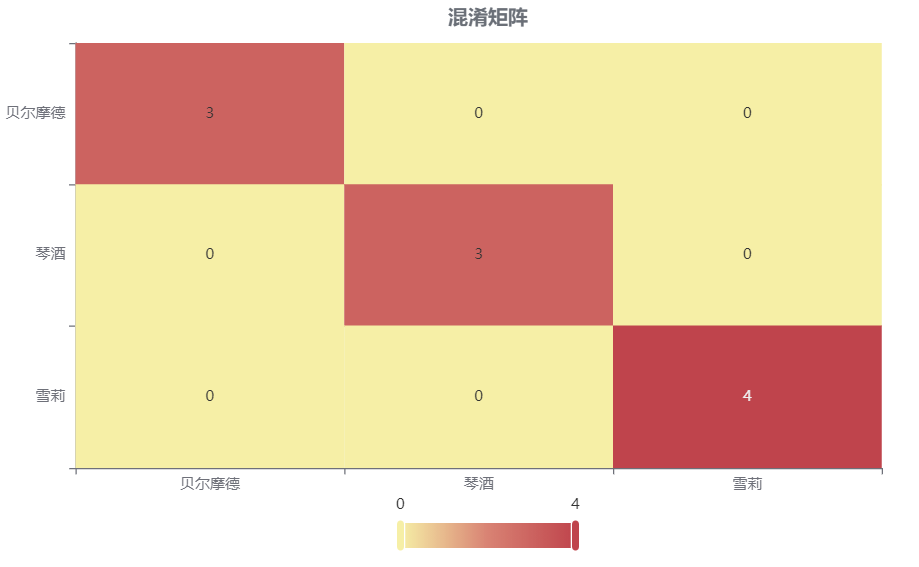
情况 2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到当前数据分类混淆矩阵和分类评价效果。


# 7、注意事项
- 由于 catboost 具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用 SPSSPRO 客户端进行。
- catboost 的参数修改需要使用 SPSSPRO 客户端进行。
# 8、模型理论
Catboost 总体算法框架与 GBDT 一致,但是在处理类别特征、Boosting 方式以及决策树生长评分方面作了比较大的改进。这三个改进令 Catboost 能够有效地处理字符串特征,并且相同数据规模下的模型拟合速度要快于 Xgboost 和 LGBM。
① 类别特征 Catboost 的基础仍是提升树,与传统的梯度提升树不同的是 Catboost 在处理类别特征时,没有简单 地采用基于贪婪目标统计的方法进行分裂节点的选择。而是创造性地在计算节点增益时考虑先验分布项,有效地排除了类别变量中低频率特征和噪声对生成决策树带来的影响。

式中,σj 为第 j 数据;xi,k 表示训练集中第 i 行数据的第 k 列离散特征;a 是一个先验权重;p 是先验分布项(对于回归问题而言,先验项一般取训练集中预测标签的均值; 对于二分类问题而言,先验项取值为正例也就是为 1 的项的先验概率);这里的[]为指示函数,满足内部条件则输出 1,否则输出 0。通过改进后的 TS 方法,Catboost 能够在信息损失最小化的情况下将类别特征转化为数值。
(2) 排序提升(Ordered boosting) 传统的 GBDT 模型采取的是无行列采样的方式,所有的基学习器及即 Cart 决策树是在一个完整的数据集上进行梯度提升的,每次迭代都使用上一轮树的负梯度进行训练。这样会导致预测偏差( bias)不断累积和过拟合(over fitting) 的现象。Xgboost 和微软开发的 LGBM 采用了行列采样和正则化的处理降低了过拟合的效应。Catboost 更进一步提出了 Ordered boosting 方法。算法伪代码如下:
其中,σ 是训练集随机排序的次数; I 为需要生成对称决策树的数量也就是学习器的个数。对于所有 n 个样本,初始化 Mi 为 0。然后通过对随机序列进行采样并在其基础上获得梯度,进行 σ 次排列的目的是增强算法的鲁棒性并且可以有效地避免过拟合的情况,这些排列与用于计算改进 TS 的排列相同。对于每个随机排列 σ,将对如上所示的 n 个不同的模型 Mi 进行训练。然后依次计算前 i-1 条数据损失函数(Loss)的梯度 gj,并将 i-1 个 gj 传入对称树建立一颗残差树。并将初始模型 Mi 从 Mi(X1)更新为 Mi(Xi)。此过程目的是去除 Xi 建立模型对 X1 的预测值,这样可以降低噪点对模型的干扰。对于 s 次排列中的每次排列而言,我们建立 n 个模型 Mi,整体复杂度约为 O(s×n2) 。为了加速算法运行,对于每个排列 Catboost 在更新 Mi 时不是存储和更新 O(n2)个 Mi(Xi),而是令 Mi'(Xj),i=1…,log2(n)),j < 2i+1) 。Mi'(Xj)是基于前 2i 个样本的相同 j 的近似值。最后,Mi'(Xj)的预测复杂度将不大于![]() 。
。
③ 快速评分 Catboost 使用完全对称树(oblivious decision trees,ODT)作为基学习器,它的结构如下图所示,与一 般决策树不同的是,完全对称树对于相同深度的内部节点,分裂时选择的特征以及特征阈值是完全一致的。所以完全对称树也可以变换成具有 2^d 条目的决策表格,d 表示决策树的层数。这种结构的决策树更加平衡并且特征处理速度远快于一般的决策树。此外,通过将浮点特征,统计信息(用户 id 等)、独热编码特征统一用二进制处理,模型的大大减少了调参需求。 下图为完全对称树结构:

④ 特征重要度排序 Catboost 不仅有较高的预测精度,而且同时能够能够甑别不同影响因子(即预测所使用特征)对预测结果的相对贡献度,某个特征在单棵决策树中的相对贡献度用以下公式衡量。
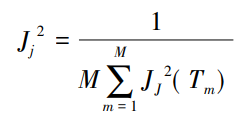
式中,M 为迭代次数(树的数量);Jj2 代表特征 j 的全局重要度。

式中,L 为树的叶子节点数量;L-1 为树的非叶子节点数量;vt 是和节点 t 相关联的特征;it^2 是节点 t 分裂之后平方损失的减少值,it^2 减少的越多说明此次分裂的收益越大,意味着此特征对于所属节点的特征重要度越高。
# 9、手推步骤
| 酒精 | 苹果酸 | 类黄酮 | 颜色强度 | 色调 | 稀释的酒的蛋白质浓度的光谱度量 | 脯氨酸 | 种类 |
|---|---|---|---|---|---|---|---|
| 14.38 | 3.59 | 3.17 | 4.9 | 1.04 | 3.44 | 1065 | 琴酒 |
| 12.45 | 3.03 | 0.58 | 7.5 | 0.67 | 1.73 | 880 | 贝尔摩德 |
| 12.85 | 1.6 | 2.37 | 3.93 | 1.09 | 3.63 | 1015 | 琴酒 |
| 12.17 | 1.45 | 1.75 | 2.95 | 1.45 | 2.23 | 355 | 雪莉 |
| 14.3 | 1.92 | 3.14 | 6.2 | 1.07 | 2.65 | 1280 | 琴酒 |
| 12.22 | 1.29 | 2.04 | 2.7 | 0.86 | 3.02 | 312 | 雪莉 |
| 13.58 | 2.58 | 0.84 | 8.66 | 0.74 | 1.8 | 750 | 贝尔摩德 |
| 14.13 | 4.1 | 0.76 | 9.2 | 0.61 | 1.6 | 560 | 贝尔摩德 |
现有一组红酒数据,根据红酒的颜色强度,脯氨酸,类黄酮等变量,生成一个能够区分琴酒,雪莉,贝尔摩德三种品种的红酒的catboost计算过程如下:
step1:计算先验概率和初始预测值
用拉普拉斯平滑计算先验概率:
m表示总样本数,k表示类别数目。
初始预测值:
所有样本初始预测值:[-0.243, -0.243, -0.426]
假设排列:σ = [3, 6, 1, 4, 7, 2, 5, 8]
(对应原编号:3, 6, 1, 4, 7, 2, 5, 8)
设置学习率 η = 0.1
标签:琴酒(0)、贝尔摩德(1)、雪莉(2)
step2:第一轮迭代
i=1:处理排列中第1个样本(原编号3)
● 前 i-1=0 个样本,无法计算梯度
● 保持初始预测
i=2:处理排列中第2个样本(原编号6)
使用前1个样本(样本3)计算梯度:
样本3的真实标签:0(琴酒)
计算当前预测概率:
梯度计算:
用样本3的特征和梯度 [-0.624, 0.376, 0.247] 训练第一棵树。
当 i=3:处理样本1
前2个样本:3, 6
样本6的真实标签:2(雪莉)
样本6的当前预测概率:[0.376, 0.376, 0.247]
梯度 = [0.376-0, 0.376-0, 0.247-1] = [0.376, 0.376, -0.753]
训练数据:
| 样本 | 酒精 | 类黄酮 | 脯氨酸 | 梯度0 | 梯度1 | 梯度2 |
|---|---|---|---|---|---|---|
| 3 | 12.85 | 2.37 | 1015 | -0.624 | 0.376 | 0.247 |
| 6 | 12.22 | 2.04 | 312 | 0.376 | 0.376 | -0.753 |
寻找最佳分裂点:
特征"酒精"分裂点=13.0:
左节点(酒精≤13.0):样本3(12.85), 样本6(12.22)
右节点(酒精>13.0):空
左节点梯度均值 = [(-0.624+0.376)/2, (0.376+0.376)/2, (0.247-0.753)/2]
= [-0.124, 0.376, -0.253]
分裂前总梯度均值 = [-0.124, 0.376, -0.253]
分裂前方差 = (-0.124)² + (0.376)² + (-0.253)² = 0.0154 + 0.1414 + 0.0640 = 0.2208
左节点方差 = 0.2208
增益 = 0.2208 - 0.2208 = 0
通过计算其余分裂点的增益≤ 0,此时不分裂。
step3:更新模型(第一轮后)
样本3(酒精=12.85≤13.0):
F₀⁽¹⁾ = -0.243 + 0.0124 = -0.2306
F₁⁽¹⁾ = -0.243 + (-0.0376) = -0.2806
F₂⁽¹⁾ = -0.426 + 0.0253 = -0.4007
样本6(酒精=12.22≤13.0):
F₀⁽¹⁾ = -0.243 + 0.0124 = -0.2306
F₁⁽¹⁾ = -0.243 + (-0.0376) = -0.2806
F₂⁽¹⁾ = -0.426 + 0.0253 = -0.4007
样本1(酒精=14.38>13.0):
F₀⁽¹⁾ = -0.243 + 0 = -0.243
F₁⁽¹⁾ = -0.243 + 0 = -0.243
F₂⁽¹⁾ = -0.426 + 0 = -0.426
step4:第二轮迭代
i=4:处理样本4
前3个样本:3, 6, 1
重新计算前3个样本的梯度:
样本3(标签0):
当前预测值:[-0.231, -0.281, -0.401]
计算概率:
分母 = 0.587 + 0.524 + 0.397 = 1.508
P₀ = 0.587/1.508 ≈ 0.389, P₁ = 0.524/1.508 ≈ 0.347, P₂ = 0.397/1.508 ≈ 0.263
梯度:[-0.611, 0.347, 0.263]
样本6(标签2):
当前预测值:[-0.231, -0.281, -0.401]
概率:[0.389, 0.347, 0.263]
梯度:[0.389, 0.347, -0.737]
样本1(标签0):
当前预测值:[-0.243, -0.243, -0.426]
分母 = 0.571 + 0.571 + 0.375 = 1.517
P₀ = 0.571/1.517 ≈ 0.376, P₁ = 0.571/1.517 ≈ 0.376, P₂ = 0.375/1.517 ≈ 0.247
梯度:[-0.624, 0.376, 0.247]
训练数据:
| 样本 | 酒精 | 梯度0 | 梯度1 | 梯度2 |
|---|---|---|---|---|
| 3 | 12.85 | -0.611 | 0.347 | 0.263 |
| 6 | 12.22 | 0.389 | 0.347 | -0.737 |
| 1 | 14.38 | -0.624 | 0.376 | 0.247 |
寻找最佳分裂点:
特征"酒精"分裂点=13.5:
左节点(酒精≤13.5):样本3(12.85), 样本6(12.22)
右节点(酒精>13.5):样本1(14.38)
左节点梯度均值 = [(-0.611+0.389)/2, (0.347+0.347)/2, (0.263-0.737)/2]
= [-0.111, 0.347, -0.237]
右节点梯度均值 = [-0.624, 0.376, 0.247]
分裂前总梯度均值 = [(-0.611+0.389-0.624)/3, (0.347+0.347+0.376)/3, (0.263-0.737+0.247)/3]
= [-0.282, 0.357, -0.076]
分裂前方差 = (-0.282)² + (0.357)² + (-0.076)² = 0.0795 + 0.1274 + 0.0058 = 0.2127
左节点方差 = (-0.111)² + (0.347)² + (-0.237)² = 0.0123 + 0.1204 + 0.0562 = 0.1889
右节点方差 = (-0.624)² + (0.376)² + (0.247)² = 0.3894 + 0.1414 + 0.0610 = 0.5918
增益 = 0.2127 - (0.1889 + 0.5918)/2 = 0.2127 - 0.39035 = -0.1777
通过计算其余分裂点的增益≤ 0,此时不分裂,继续更新模型。
前几轮迭代由于样本数量过少,分裂点的增益都≤ 0。下面给出增益大于零时的更新模型方法:
假设存在分裂点增益>0,且特征"酒精"分裂点=13.5的增益最大。
选择特征"酒精"分裂点=13.5
左节点输出 = -[-0.111, 0.347, -0.237] × 0.1 = [0.0111, -0.0347, 0.0237]
右节点输出 = -[-0.624, 0.376, 0.247] × 0.1 = [0.0624, -0.0376, -0.0247]
step5:更新模型(第二轮后)
样本3(酒精=12.85≤13.5):
F₀⁽²⁾ = -0.2306 + 0.0111 = -0.2195
F₁⁽²⁾ = -0.2806 + (-0.0347) = -0.3153
F₂⁽²⁾ = -0.4007 + 0.0237 = -0.3770
样本6(酒精=12.22≤13.5):
F₀⁽²⁾ = -0.2306 + 0.0111 = -0.2195
F₁⁽²⁾ = -0.2806 + (-0.0347) = -0.3153
F₂⁽²⁾ = -0.4007 + 0.0237 = -0.3770
样本1(酒精=14.38>13.5):
F₀⁽²⁾ = -0.243 + 0.0624 = -0.1806
F₁⁽²⁾ = -0.243 + (-0.0376) = -0.2806
F₂⁽²⁾ = -0.426 + (-0.0247) = -0.4507
样本4(酒精=12.17≤13.5):
F₀⁽²⁾ = -0.243 + 0.0111 = -0.2319
F₁⁽²⁾ = -0.243 + (-0.0347) = -0.2777
F₂⁽²⁾ = -0.426 + 0.0237 = -0.4023
step6:继续进行迭代
经过多轮迭代后得到每个样本的最终概率,通过最终概率判断样本所属类别。
例如样本3(琴酒)的最终预测值可能变为:
F₀ ≈ 0.8, F₁ ≈ -1.2, F₂ ≈ -1.0
计算概率:
分母 = 6.310 + 0.063 + 0.1 = 6.473
P₀ = 6.310/6.473 ≈ 0.975, P₁ = 0.063/6.473 ≈ 0.01, P₂ = 0.1/6.473 ≈ 0.015
预测为类别0(琴酒),正确。
# 10、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]Dorogush, Anna Veronika , V. Ershov , and A. Gulin . "CatBoost: gradient boosting with categorical features support." (2018).