逻辑回归(梯度下降法)
# 1、作用
逻辑回归,是一种名为“回归”的线性分类器,其本质是由线性回归变化而来的,一种广泛使用于分类问题中的广义回归算法。
# 2、输入输出描述
输入:自变量X为1个或1个以上的定类或定量变量,因变量Y为一个定类变量。
输出: 模型的分类结果和模型分类的评价效果。
# 3、案例示例
根据红酒的颜色强度,苯酚,类黄酮等变量,生成一个能够区分琴酒,雪莉,贝尔摩德三种品种的红酒的逻辑回归模型。
# 4、案例数据
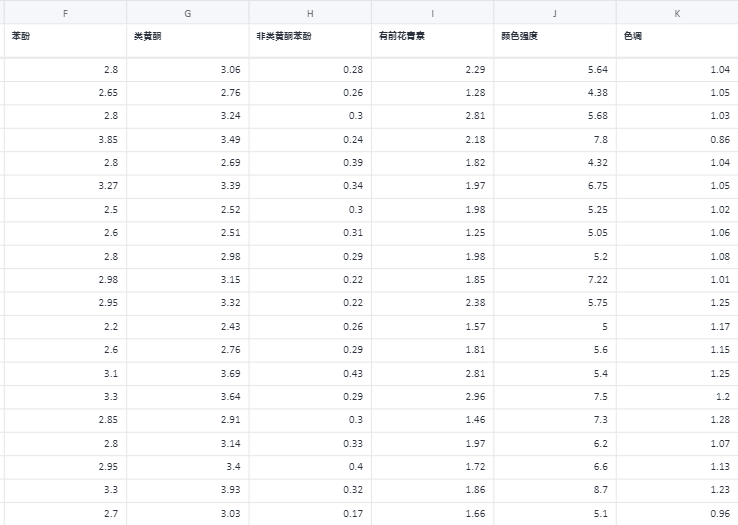
逻辑回归(梯度下降法)案例数据
# 5、案例操作
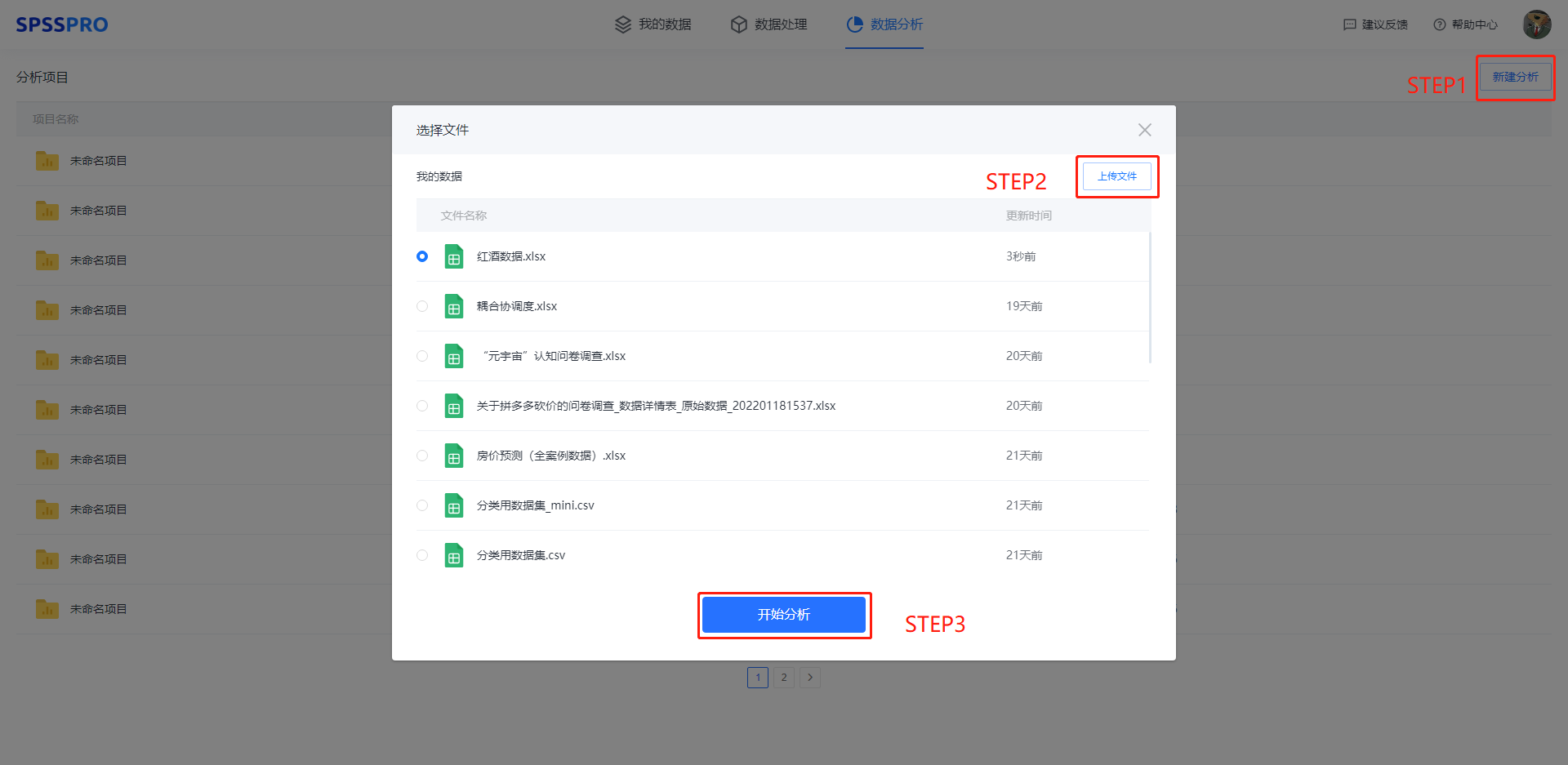
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;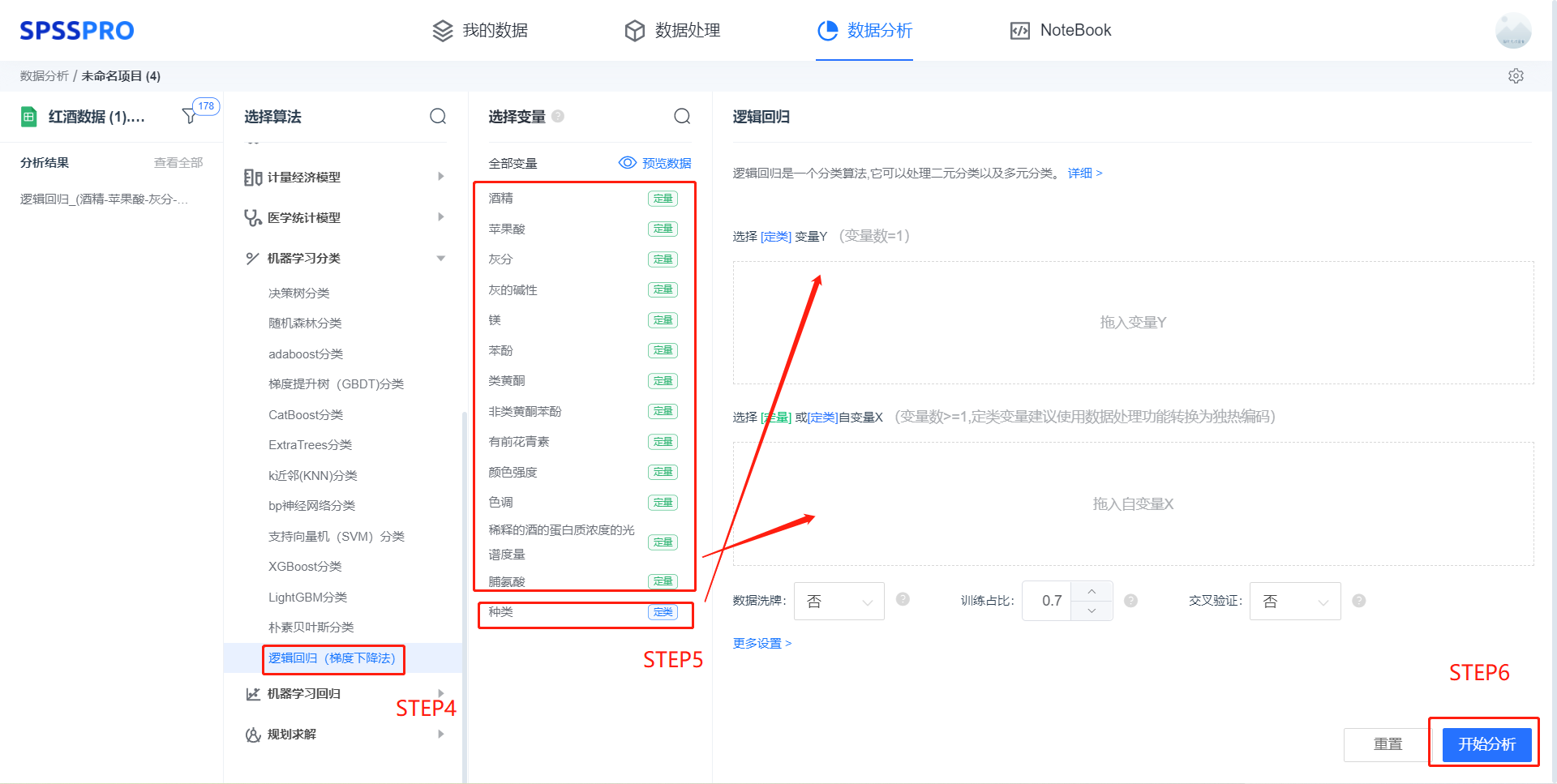
step4:选择【逻辑回归(梯度下降法)】;
step5:查看对应的数据数据格式,按要求输入【逻辑回归(梯度下降法)】数据;
step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果1:模型参数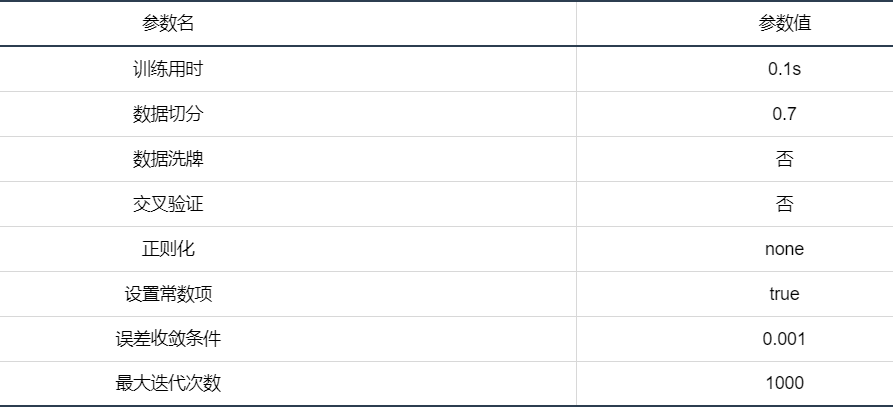
图表说明:
上表展示了模型各项参数配置以及模型训练时长。
输出结果2:混淆矩阵热力图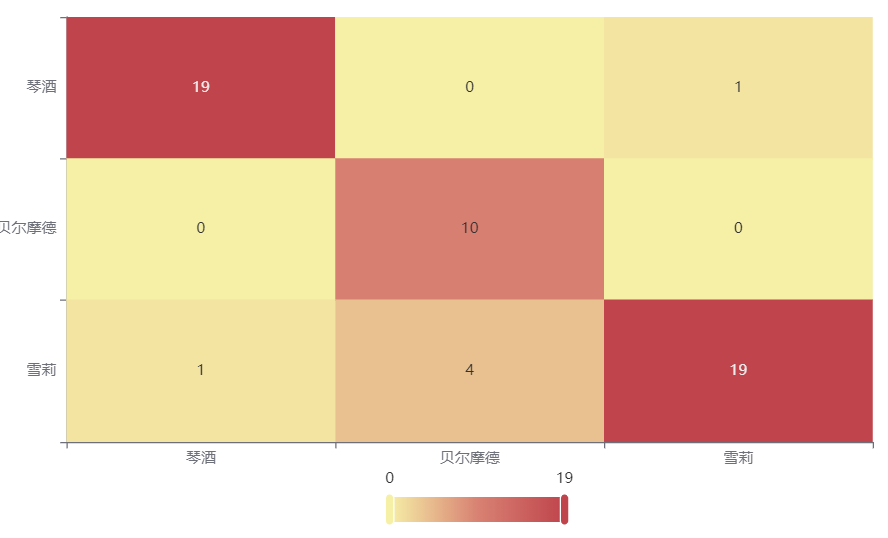
图表说明:
上表以热力图的形式展示了混淆矩阵,可以通过右上角切换在测试数据集和训练数据集中的情况。
分析:
误分类情况低,绝大多数分类正确。
输出结果3:特征重要性

图表说明:
上表中展示了交叉验证集、训练集和测试集的预测评价指标,通过量化指标来衡量逻辑回归的预测效果。其中,通过交叉验证集的评价指标可以不断调整超参数,以得到可靠稳定的模型。
● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用F1指标。
分析:
分类结果优秀,在训练集完全正确,在测试集准确率达到0.89。
输出结果4:模型预测与应用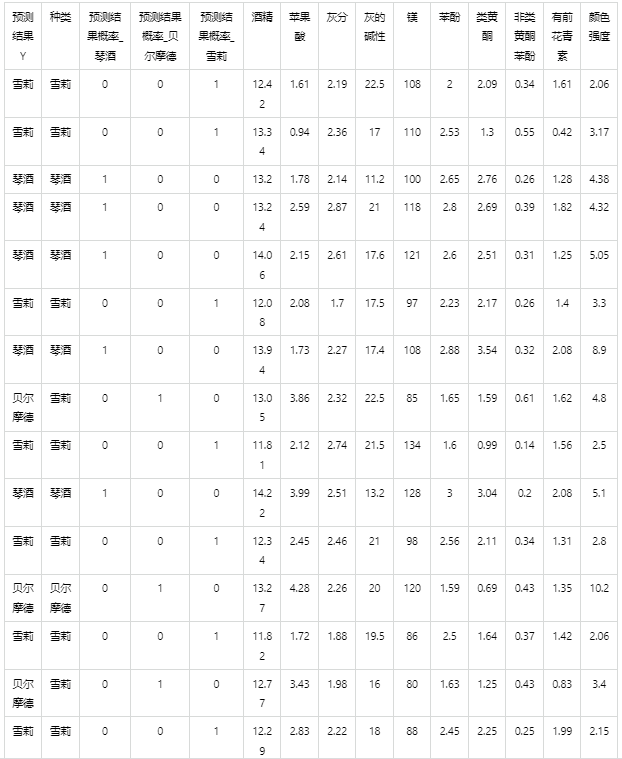
输出结果5:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
●当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
●当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况1:在上面模型评估后,模型分类结果较好,具有实用性,这时我们将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
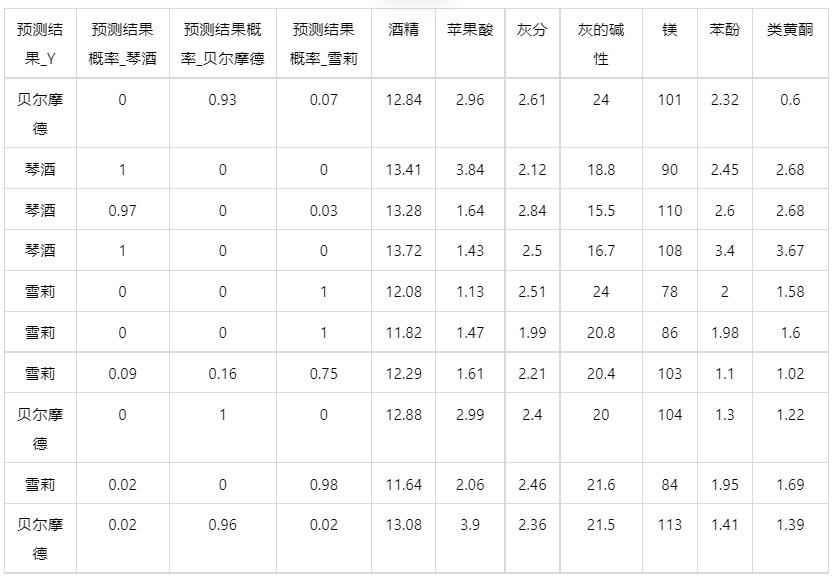
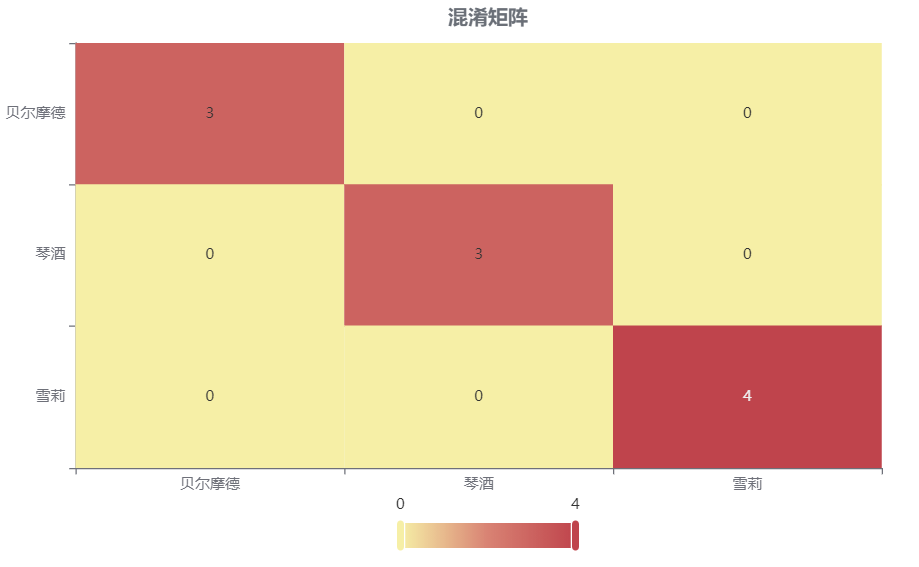
情况2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到当前数据分类混淆矩阵和分类评价效果。

# 7、注意事项
- 由于梯度下降法具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用SPSSPRO客户端进行。
- 逻辑回归(梯度下降法)的参数修改需要使用SPSSPRO客户端进行。
# 8、模型理论
逻辑回归的基本定义是通过拟合一条直线将不同类别的样本区分开来。其核心思想是使用sigmoid函数把线性回归的结果从
假设我们有一线性回归公式:
在这里我们假设先验服从伯努利分布(Bernoulli distribution),即只有两种可能结果的随机试验的概率分布,所以:
所以我们得到伯努利分布的概率质量函数为:
则:
逻辑回归模型假设事件的对数几率(log odds)是输入变量x的线性函数,需要注意的是,这里的参数
令
所以
将其简化为:
而这就是sigmoid函数的形式。 我们把它写成一般形式:
其函数图像为:
从图中可以看出,当
因此,逻辑回归的公式为:
我们可以用最大似然估计法(Maximum Likelihood Estimation, MLE)来估算函数中的参数
结合上述式子,令
则,
假设我们有m个样本,则使用MLE构建函数为:
为了方便计算,我们使用对数似然,将乘法转变为加法运算:
因此,我们可以用梯度上升法求解上式对数似然函数,求出使得目前结果的可能性最大的参数
使用梯度下降法求解的核心思想是,先求导找出梯度下降方向,再求解找出要下降多少,即步长。因此,我们先对
步长为:
注意,
至此,我们完成了逻辑回归的整个过程。
针对于多分类逻辑回归,SPSSPRO 默认用了将某一类和剩余的类(OVR)比较作为二分类问题,N 个类别进行 N-1 次分类,得到 N-1 个二分类模型,求出每种二分类对应的概率,概率最高的一类作为新样本的预测结果。
# 9、手推步骤
| 身高(cm) | 体重(kg) | 性别 |
|---|---|---|
| 185 | 75 | 男 |
| 175 | 63 | 男 |
| 170 | 55 | 男 |
| 165 | 50 | 女 |
| 160 | 46 | 女 |
| 178 | 63 | 男 |
| 174 | 55 | 女 |
| 169 | 49 | 女 |
| 153 | 45 | 女 |
现有一组数据包含人的身高、体重和性别。
假设要预测一个新样本的性别,身高 = 172 cm,体重 = 58 kg。逻辑回归(梯度下降法)算法求解过程如下:
step1:符号及公式说明
特征向量:
权重向量:
逻辑回归模型:
其中,
损失函数:
梯度:
其中
step2:数据标准化
由于身高和体重数值较大且量纲不同,这里进行数据标准化:
| 原始身高 | 原始体重 | 标准身高 | 标准体重 | y |
|---|---|---|---|---|
| 185 | 75 | 1.565 | 1.975 | 1 |
| 175 | 63 | 0.530 | 0.749 | 1 |
| 170 | 55 | 0.011 | -0.068 | 1 |
| 165 | 50 | -0.507 | -0.579 | 0 |
| 160 | 46 | -1.025 | -0.987 | 0 |
| 178 | 63 | 0.840 | 0.749 | 1 |
| 174 | 55 | 0.426 | -0.068 | 0 |
| 169 | 49 | -0.092 | -0.681 | 0 |
| 153 | 45 | -1.749 | -1.089 | 0 |
step3:设置初始值
取初始
学习率
模型终止条件为梯度的模长小于某个阈值或者达到迭代次数,这里为了简化计算,设置迭代次数=3。
step4:第一次迭代
对每个样本进行计算,由于初始
所以每个样本的初始预测值都是0.5。
计算梯度分量:
梯度:
更新模型:
step5:继续迭代
根据新权重重复step4进行第二次和第三次迭代,得到最终权重:
step6:预测新样本
新样本:身高 172 cm,体重 58 kg。
标准化:
因为
# 10、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.