随机森林分类
# 1、作用
随机森林分类在生成众多决策树的过程中,是通过对建模数据集的样本观测和特征变量分别进行随机抽样,每次抽样结果均为一棵树,且每棵树都会生成符合自身属性的规则和分类结果,而森林最终集成所有决策树的规则和分类结果,实现随机森林算法的分类。
# 2、输入输出描述
输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定类变量。
输出: 模型的分类结果和模型的分类评价情况。
# 3、案例示例
根据红酒的颜色强度,脯氨酸,类黄酮等变量,生成一个能够区分琴酒,雪莉,贝尔摩德三种品种的红酒的随机森林。
# 4、案例数据

随机森林分类案例数据
# 5、案例操作
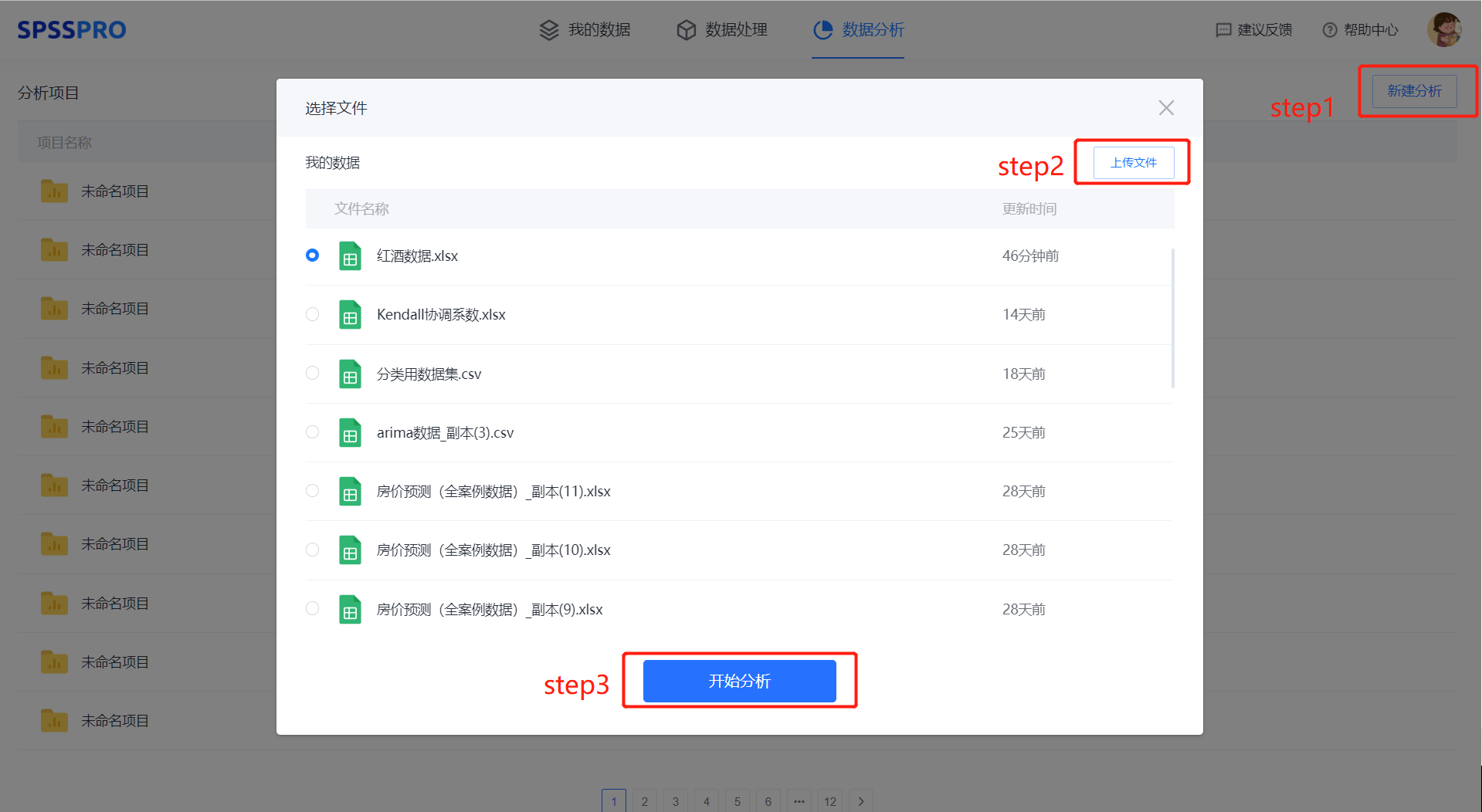
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;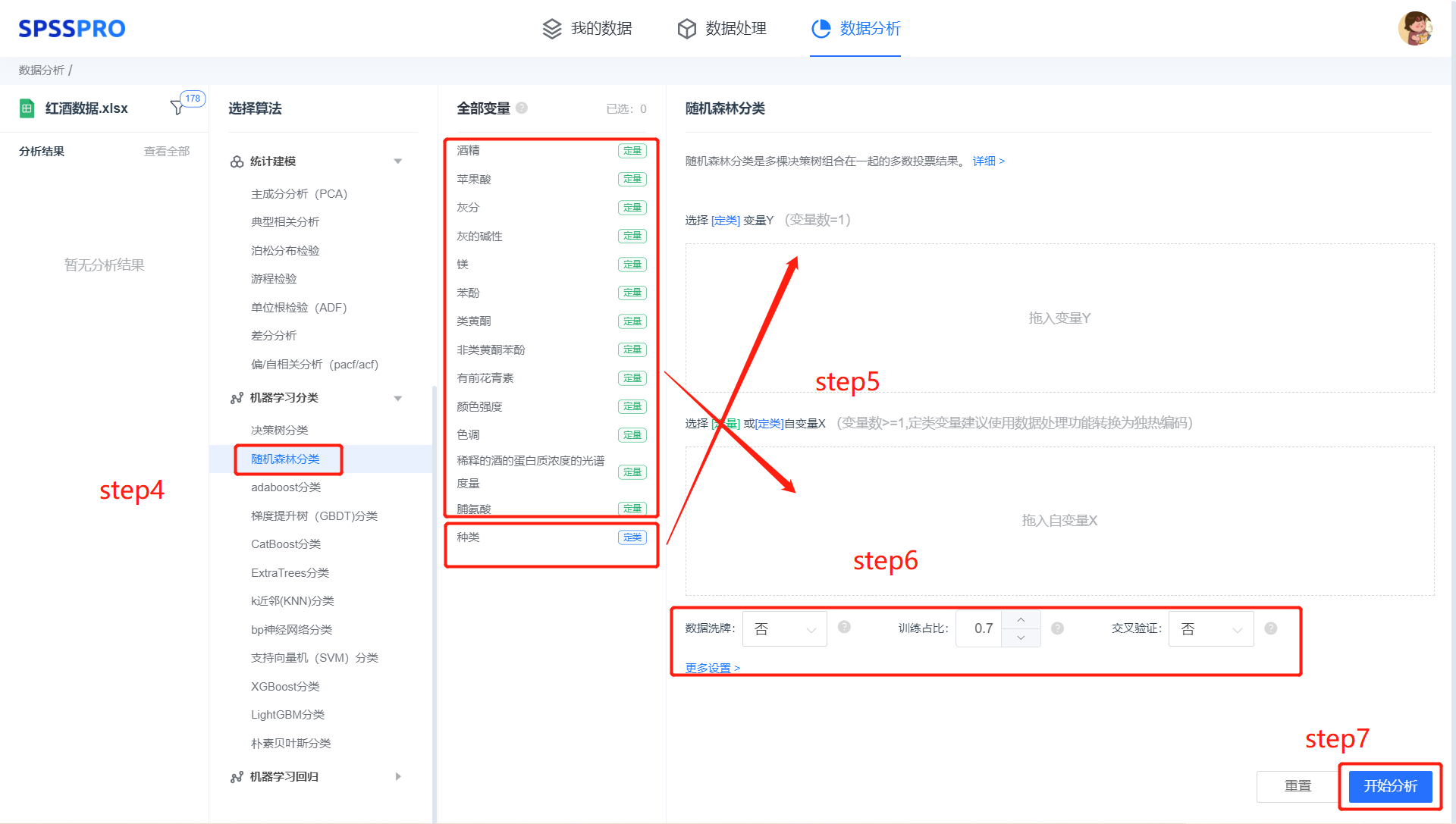
step4:选择【随机森林分类】;
step5:查看对应的数据数据格式,按要求输入【随机森林分类】数据;
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:模型参数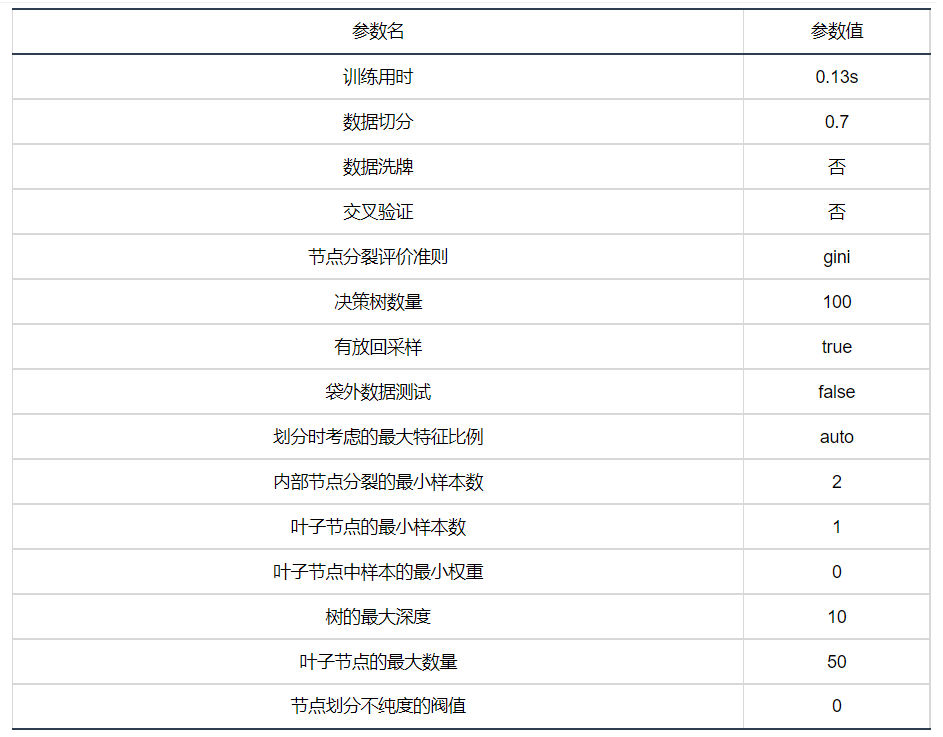
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
输出结果 2:特征重要性

图表说明:上柱形图或表格展示了各特征(自变量)的重要性比例。(附:有时候可以利用特征重要性反推该变量在实际生活中的价值,因为该重要性往往决定分类结果。)
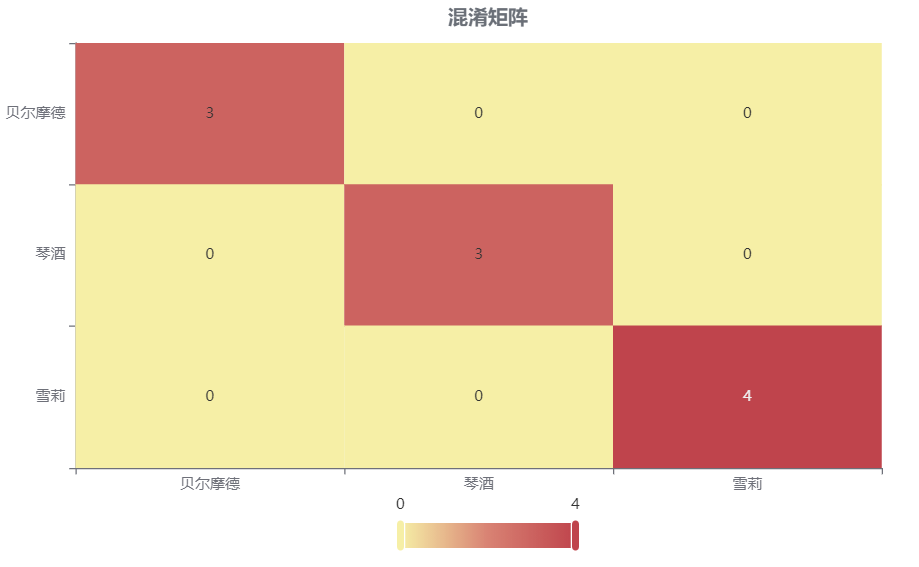
输出结果 3:混淆矩阵热力图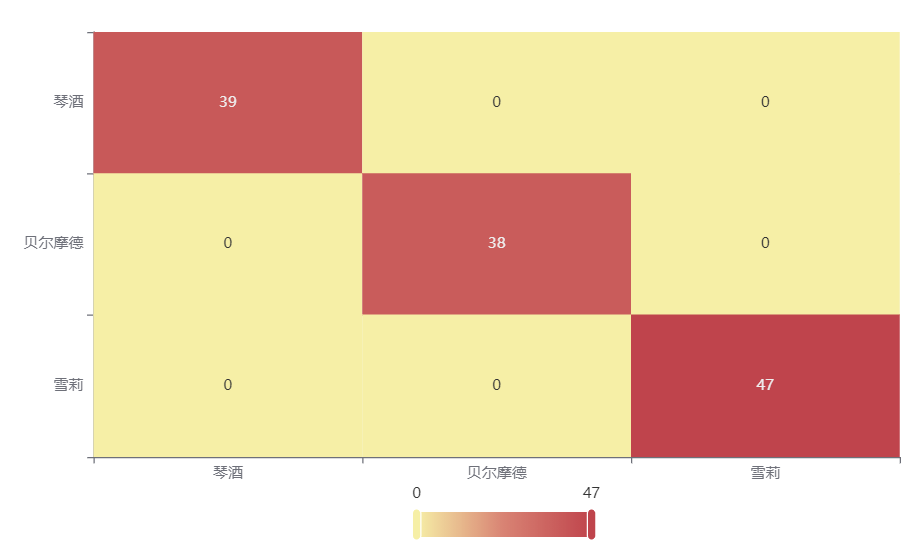

图表说明: 上表以热力图的形式展示了混淆矩阵,可以通过右上角切换在测试数据集和训练数据集中的情况。
分析:
上图是训练集的分类结果,全部样本分类正确,没有分错的样本,说明分类效果极好。
下图是测试集的分类结果,绝大部分样本分类正确,只有 2 个被分错的样本,说明训练集训练出来的模型结果是有效实用的。
输出结果 4:模型评估结果
| 准确率 | 召回率 | 精确率 | F1 | |
|---|---|---|---|---|
| 训练集 | 1 | 1 | 1 | 1 |
| 测试集 | 0.963 | 0.963 | 0.969 | 0.964 |
图表说明: 上表中展示了训练集和测试集的分类评价指标,通过量化指标来衡量随机森林对训练、测试数据的分类效果。
● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用 F1 指标。
●oob_score:对于分类问题,oob_score 是袋外数据的准确率。若在建立树过程中选择有放回抽样时,大约 1/3 的记录没有被抽取。没有被抽取的自然形成一个对照数据集,可用于模型的验证。所以随机森林不需要另外预留部分数据做交叉验证,其本身的算法类似交叉验证,而且袋外误差是对预测误差的无偏估计。
分析:
训练集的各分类评价指标都等于 1,说明模型在训练集的分类完全正确,没有分类错误的样本。
测试集的各分类评价指标都大于 0.9,说明模型在测试集的分类效果极好,模型具有实用性。
输出结果 5:测试数据预测评估结果
图表说明: 上表格为预览结果,只显示部分数据,全部数据请点击下载按钮导出。
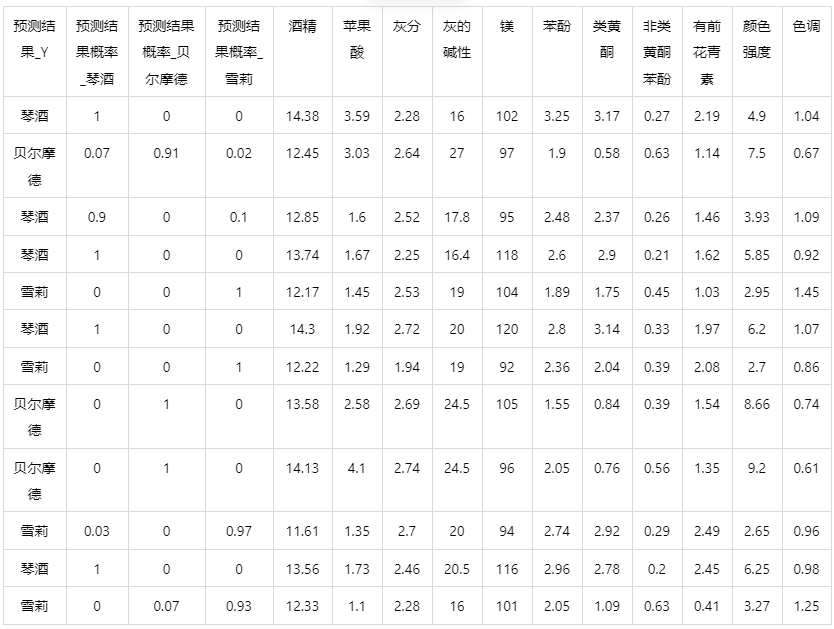
上表展示了随机森林模型对测试数据的分类结果,第一列是预测结果,第二列是因变量真实值,第三、四、五列分别是对所属每一个分类水平概率的预测结果,最终分类预测结果值是拥有最大预测概率的分类组别,比如第二个样本,预测它是琴酒的概率有 0.2,是贝尔摩德的概率有 0.08,是雪莉的概率有 0.72,概率值最大的是 0.72,所以最终预测它为雪莉。
输出结果 6:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
● 当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
● 当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况 1:在上面模型评估后,模型分类结果较好,具有实用性,这时我们将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
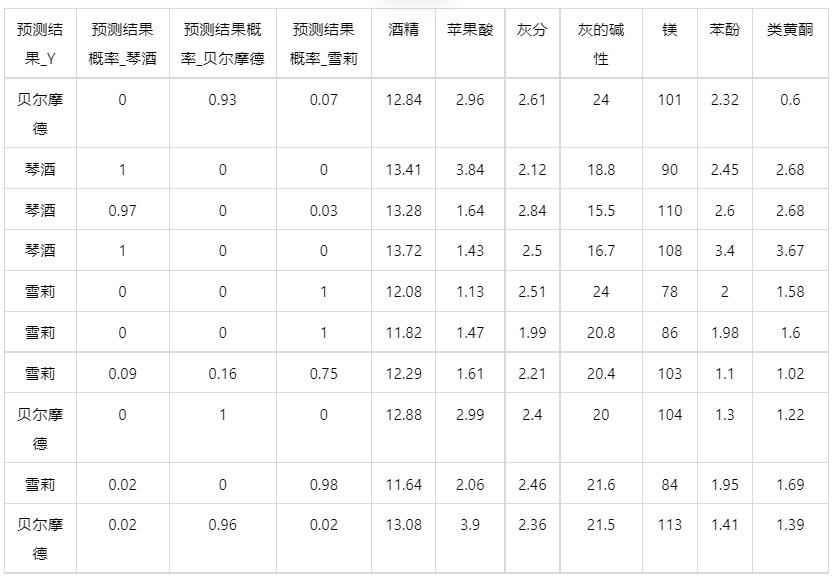
情况 2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到当前数据分类混淆矩阵和分类评价效果。

# 7、注意事项
- 由于随机森林具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用 SPSSPRO 客户端进行。
- 随机森林的参数修改需要使用 SPSSPRO 客户端进行。
# 8、模型理论
随机森林是以决策树为基学习器通过集成方式构建 而成的有监督机器学习方法 ,进一步在决策树的训练过程引入了随机性,使其具备优良的抗过拟合 以及抗噪能力. RF 分别从样本选取和特征选择 2 个角度体现其随机性。
1) 随机选取样本:RF 中每一棵决策树的样本 集均是从原始数据集中采用 Bootstrap 策略有放回 地抽取、重组形成与原始数据集等大的子集合. 这就意味着同一个子集里面的样本可以是重复出现 的,不同子集中的样本也可以是重复出现的.
2) 随机选取特征:不同于单个决策树在分割过 程中考虑所有特征后,选择一个最优特征来分割节 点. RF 通过在基学习器中随机考察一定的特征变 量,之后在这些特征中选择最优特征[16] . 特征变量 考察方式的随机性使得 RF 模型的泛化能力和学习 能力优于个体学习器 。
随机森林的算法步骤如下:
A)从原始样本集中抽取训练集。每轮从原始样本集中使用 Bootstraping 的方法抽取 n 个训练样本(有放回的抽样)。共进行 k 轮抽取,得到 k 个训练集。(k 个训练集之间是相互独立的)
B)每次使用一个训练集得到一个模型,k 个训练集共得到 k 个模型。
C)对分类问题:将上步得到的 k 个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。
# 9、手推步骤
现有一个微型数据集,根据天气状况决定是否进行户外跑步。
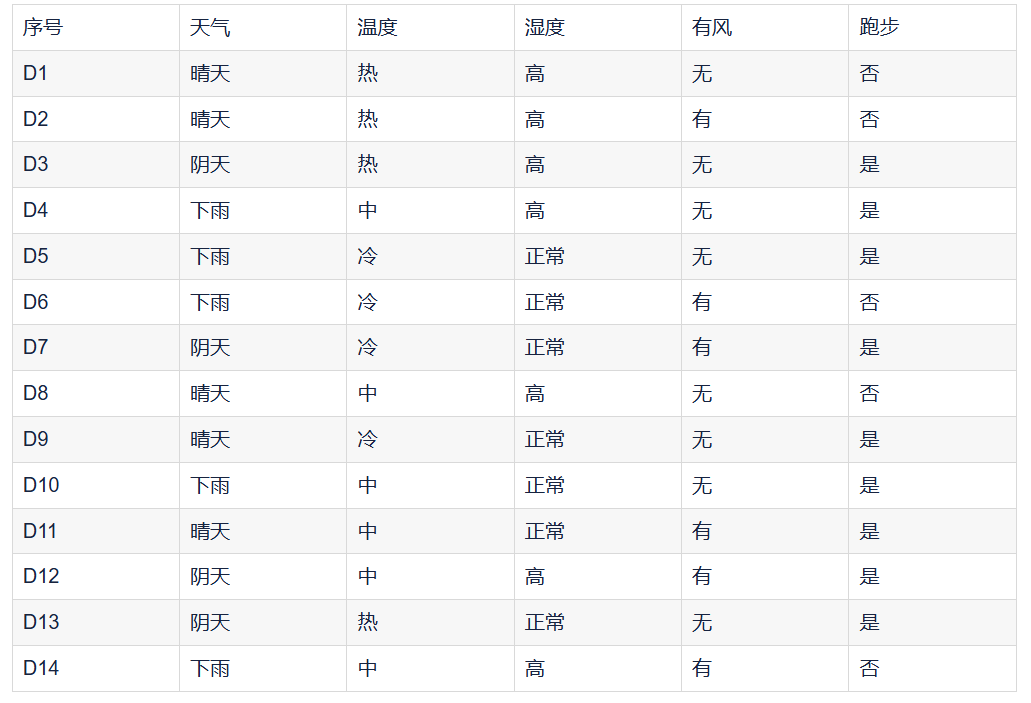
根据数据集可得特征包含:天气(晴天、阴天、下雨)、温度(冷、中、热)、湿度(高、正常)、有风(有、无);目标:跑步(是、否)
step1:随机抽取数据
从原始数据集中有放回的随机抽取14次,进行三轮抽取,获得三个训练集。
训练集1:{D1, D3, D4, D5, D6, D6, D7, D8, D9, D10, D11, D12, D13, D14}
训练集2:{D2, D2, D3, D4, D5, D7, D8, D9, D10, D11, D12, D13, D14, D14}
训练集3:{D1, D2, D3, D3, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14}
step2:构建tree1,计算根节点基尼系数
使用CART算法和基尼系数作为分裂标准。
是否跑步(是):D3,D4,D5,D7,D9,D10,D11,D12,D13,共9个
是否跑步(否):D1,D6,D6,D8,D14,共5个
根节点的基尼系数:
step3:计算按天气特征分裂的基尼系数
A1:天气=晴天(D1,D8,D9,D11)
权重=4/14
跑步(是):D9,D11,共2个
跑步(否):D1,D8,共2个
A2:天气=阴天(D3,D7,D12,D13)
权重=4/14
跑步(是):全部,共4个
跑步(否):0
A3:天气=下雨(D4,D5,D6,D6,D10,D14)
权重=6/14
跑步(是):D4,D5,D10,共3个
跑步(否):D6,D6,D14,共3个
天气特征的加权基尼系数:
天气特征带来的基尼系数减小(信息增益):
step4:计算按湿度特征分裂的基尼系数
按同样方法计算得到
step5:选择根节点的最佳分裂特征
因此根节点选择天气作为分裂特征,根节点的分裂结果:
天气=晴天 -> 新建一个子节点 (包含D1,D8, D9, D11)
天气=阴天->这是一个纯节点(全部是跑步),直接变为叶节点,预测结果为跑步(是)。
天气=下雨 -> 新建一个子节点 (包含D4,D5,D6,D6,D10,D14)
step6:继续构建tree1的其他节点
上述分裂后,晴天和下雨还要继续进行分裂,流程与根节点完全相同。
对于晴天节点,随机选择2个特征(比如 温度 和有风),计算这两个特征分裂后的加权基尼系数,选择增益最大的特征进行分裂,重复此过程,直到满足停止条件 (如节点纯度达到100%、节点样本数小于预设值、达到最大深度等)。
假设我们继续这个过程,最终得到一棵完整的 tree1:
天气=阴天 ->跑步(叶节点)
天气=晴天->
如果 湿度=高 ->不跑步 (叶节点,如D1,D8)
如果 湿度=正常 ->跑步 (叶节点,如D11)
天气=下雨 ->
如果 有风=是 ->不跑步 (叶节点,如D6,D14)
如果 有风=否 ->跑步 (叶节点,如D4,D5, D10)
step7:构建完整的森林(tree2和tree3)
完全重复第2步到第6步的过程:
使用tree2的数据集 (D2,D2,D3,D4,D5,D7,D8,D9,D10,D11,D12,D13,D14,D14),在每个节点随机选择特征子集,使用基尼系数选择最佳分裂点,生成一棵可能完全不同的决策树 tree2。
同理,生成 tree3。
最终,我们得到3棵不同的决策树,组成一个“森林”。
step8:使用森林进行预测
新的样本:天气=晴天,温度=冷,湿度=高,有风=否,要预测是否应该去跑步,让森林里的每棵树都进行投票:
tree1 预测:
天气=晴朗 -> 走到 晴朗 分支
湿度=高 -> 走到 不跑步 叶节点。
tree1 投票: 不跑步
tree2 预测:
(假设tree2的结构中) 天气=晴朗 -> ... -> 投票: 跑步
tree3 预测:
(假设tree3的结构中) 天气=晴朗 -> ... -> 投票: 不跑步
最终投票结果:不跑步 (2票) vs 跑步 (1票)
随机森林的最终预测结果是:不跑步。
# 10、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] 周志华. 机器学习[M]. 第一版. 北京:清华大学出版社, 2016 年 1 月.