adaboost分类
# 1、作用
adaboost 使得样本被错误分类导致权值增大,反之权值相应减小,这表示被错分的训练样本集包括一个更高的权重。这就会使在下轮时训练样本集更注重于难以识别的样本,针对被错分样本的进一步学习来得到下一个弱分类器,直到样本被正确分类。
# 2、输入输出描述
输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定类变量。
输出: 模型的分类结果和模型分类的评价效果。
# 3、案例示例
根据红酒的颜色强度,脯氨酸,类黄酮等变量,生成一个能够区分琴酒,雪莉,贝尔摩德三种品种的红酒的 adaboost。
# 4、案例数据

ADABOOST 分类案例数据
# 5、案例操作
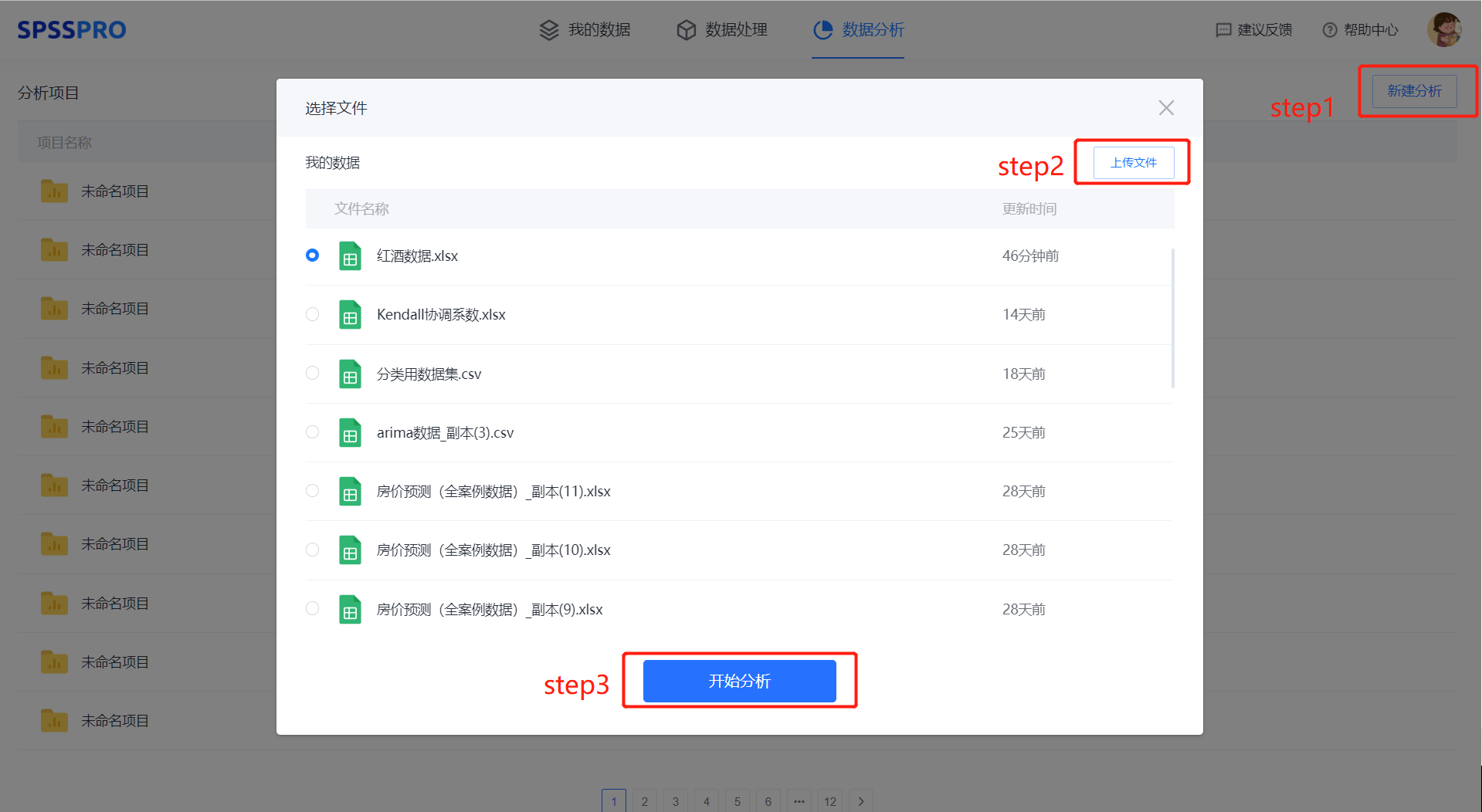
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;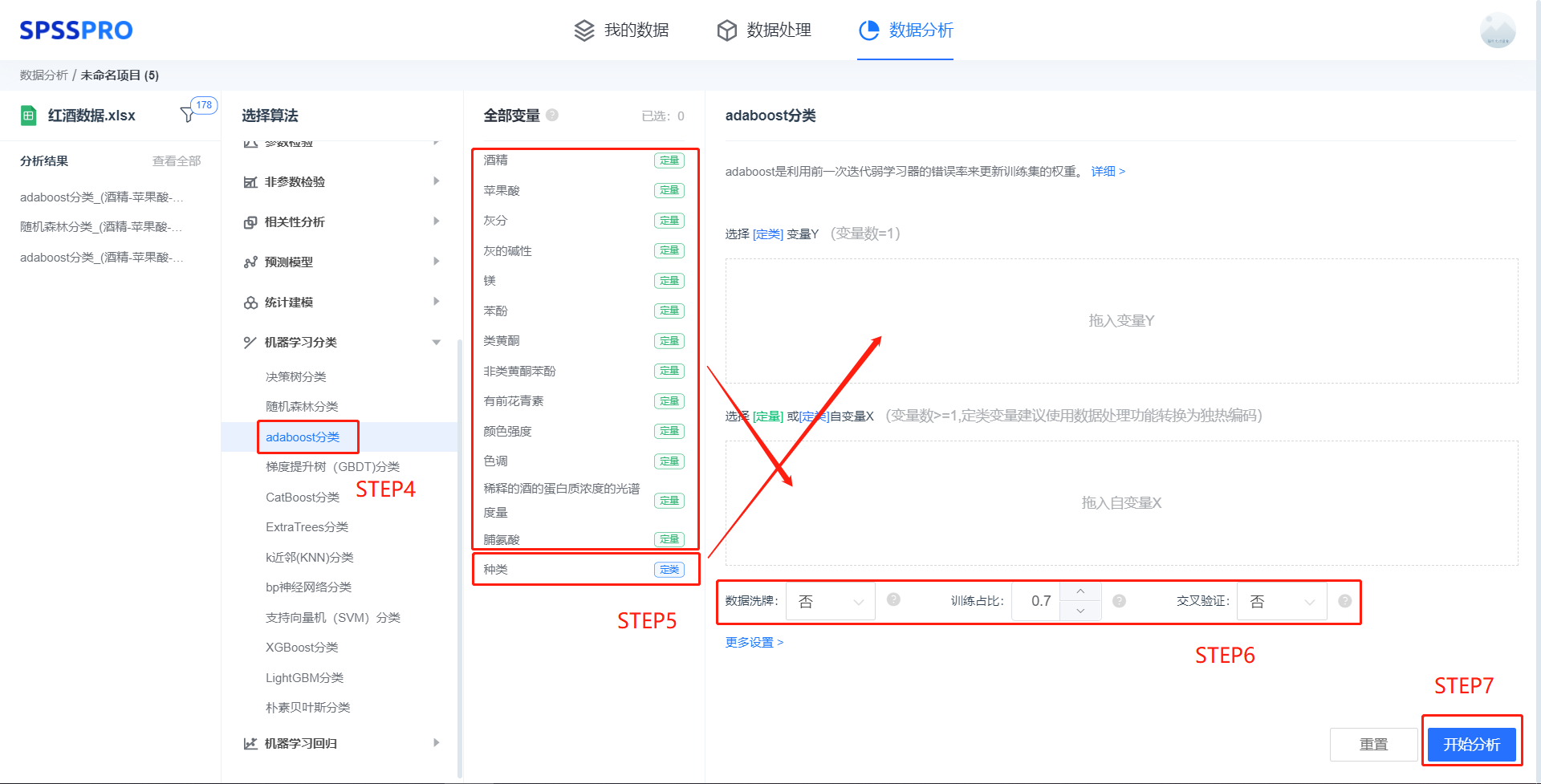
step4:选择【adaboost 分类】;
step5:查看对应的数据数据格式,按要求输入【adaboost 分类】数据;
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:模型参数 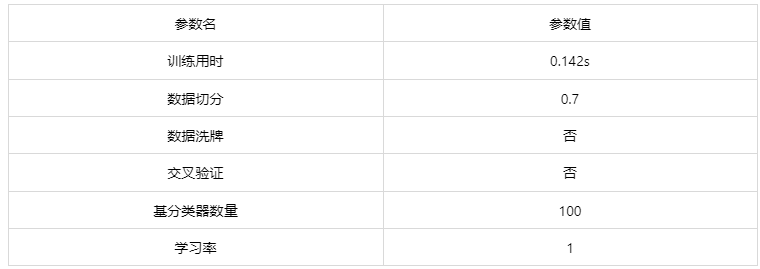
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
输出结果 2:特征重要性

图表说明:上柱形图或表格展示了各特征(自变量)的重要性比例。(附:有时候可以利用特征重要性反推该变量在实际生活中的价值,因为该重要性往往决定分类结果。)
分析:adaboost 模型中决定分类结果的重要因素是颜色强度和色调。
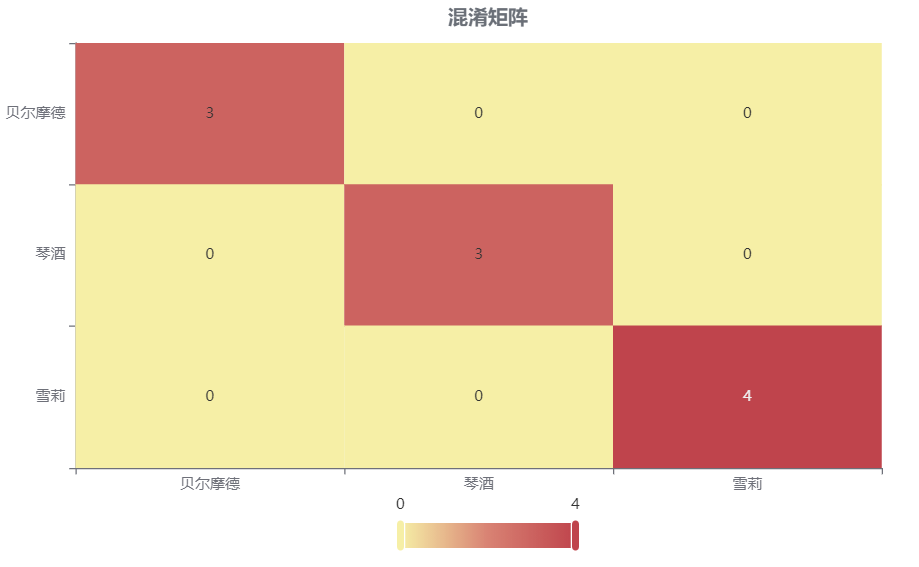
输出结果 3:混淆矩阵热力图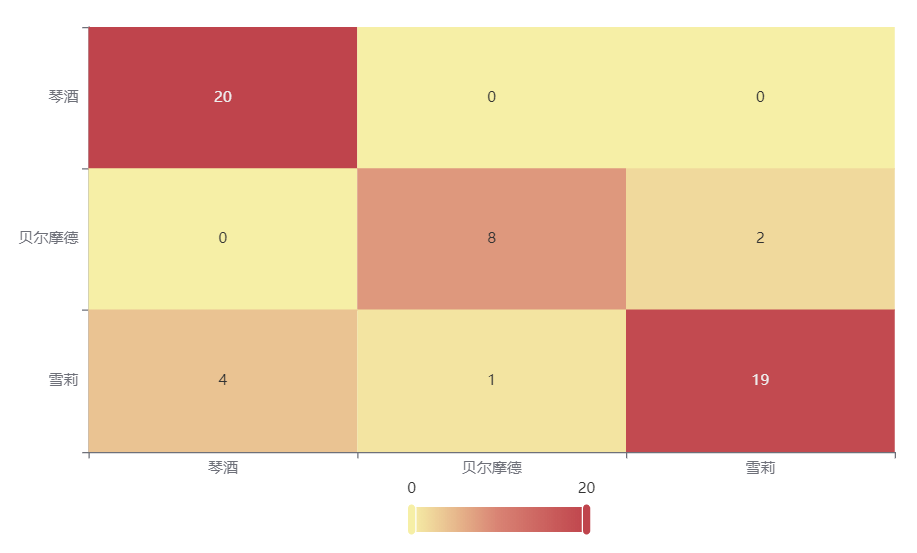

图表说明: 上表以热力图的形式展示了混淆矩阵,可以通过右上角切换在测试数据集和训练数据集中的情况。
分析:
上图是训练集的分类结果,绝大部分样本分类正确,说明分类效果很好。
下图是测试集的分类结果,绝大部分样本分类正确,只有 4 个被分错的样本,说明训练集训练出来的模型结果是有效实用的。
输出结果 4:模型评估结果
图表说明: 上表中展示了训练集和测试集的分类评价指标,通过量化指标来衡量 adaboost 对训练、测试数据的分类效果。
● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用 F1 指标。
分析:
训练集的各分类评价指标都大于 0.9,说明模型在训练集的分类效果极好,模型具有实用性。
测试集的各分类评价指标都大于 0.85,说明模型在测试集的分类效果极好,模型具有实用性。
输出结果 5:测试数据预测评估结果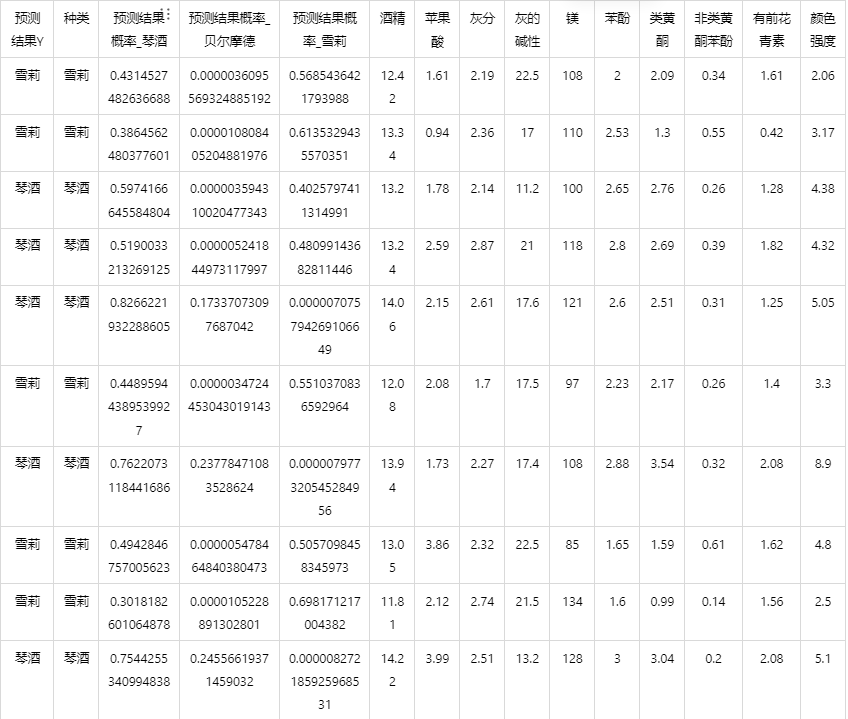
图表说明: 上表格为预览结果,只显示部分数据,全部数据请点击下载按钮导出。
上表展示了 adaboost 模型对测试数据的分类结果,第一列是预测结果,第二列是因变量真实值,第三、四、五列分别是对所属每一个分类水平概率的预测结果,最终分类预测结果值是拥有最大预测概率的分类组别。
输出结果 6:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
● 当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
● 当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况 1:在上面模型评估后,模型分类结果较好,具有实用性,这时我们将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
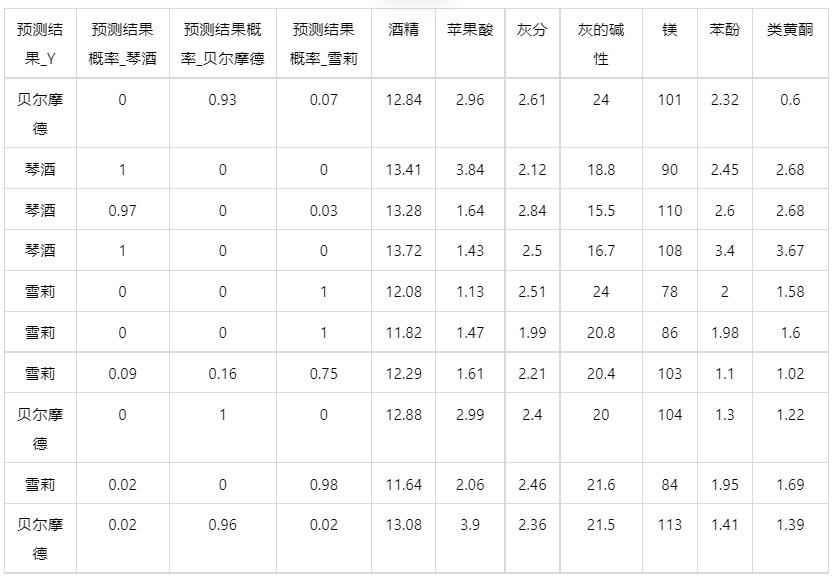
情况 2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到当前数据分类混淆矩阵和分类评价效果。

# 7、注意事项
- 由于 ADABOOST 具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用 SPSSPRO 客户端进行。
- ADABOOST 的参数修改需要使用 SPSSPRO 客户端进行。
# 8、模型理论
AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,是一种机器学习方法,由 Yoav Freund 和 Robert Schapire 提出。AdaBoost 方法的自适应在于:前一个分类器分错的样本会被用来训练下一个分类器。AdaBoost 方法对于噪声数据和异常数据很敏感。但在一些问题中,AdaBoost 方法相对于大多数其它学习算法而言,不会很容易出现过拟合现象。AdaBoost 方法中使用的分类器可能很弱(比如出现很大错误率),但只要它的分类效果比随机好一点(比如两类问题分类错误率略小于 0.5),就能够改善最终得到的模型。而错误率高于随机分类器的弱分类器也是有用的,因为在最终得到的多个分类器的线性组合中,可以给它们赋予负系数,同样也能提升分类效果。
AdaBoost 方法是一种迭代算法,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率。每一个训练样本都被赋予一个权重,表明它被某个分类器选入训练集的概率。如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它被选中的概率就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。通过这样的方式,AdaBoost 方法能“聚焦于”那些较难分(更富信息)的样本上。
在具体实现上,最初令每个样本的权重都相等,对于第 k 次迭代操作,我们就根据这些权重来选取样本点,进而训练分类器 Ck。然后就根据这个分类器,来提高被它分错的的样本的权重,并降低被正确分类的样本权重。然后,权重更新过的样本集被用于训练下一个分类器 Ck。整个训练过程如此迭代地进行下去。
算法实现:
用 xi 和 yi 表示原始样本集 D 的样本点和它们的类标。用 Wk(i)表示第 k 次迭代时全体样本的权重分布。这样就有如下所示的 AdaBoost 算法:
- 初始化:输入参数为训练集 D={x1,y1,...,xn,yn},最大循环次数 kmax,采样权重 Wk(i)=1/n,i=1,...,n;
- 迭代计数器 k 赋值为 0;
- 计数器 k 自增 1;
- 使用 Wk(i)采样权重对弱学习器 Ck 进行训练;
- 对弱学习器 Ck 的训练结果进行评估并记录进误差矩阵 Ek 中;
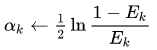
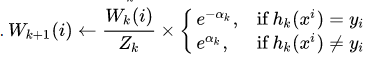
- 当 k=kmax 时停止训练
- 返回结果 Ck 和 αk,k=1,...,kmax(带权值分类器的总体)
- 结束
注意第 5 行中,当前权重分布必须考虑到分类器 Ck 的误差率。在第 7 行中,Zk 只是一个归一化系数,使得 Wk(i)能够代表一个真正的分布,而 hk(xi)是分量分类器 Ck 给出的对任一样本点 xi 的标记(+1 或-1),hk(xi) = yi 时,样本被正确分类。第 8 行中的迭代停止条件可以被换为判断当前误差率是否小于一个阈值。
最后的总体分类的判决可以使用各个分量分类器加权平均来得到:
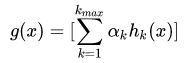
这样,最后对分类结果的判定规则是:
![]()
# 9、手推步骤
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
现有一组数据集,y分为1和-1两类,Adaboost算法过程如下:
step1:初始化数据权重
这里一共10个样本,对应均分以下每个样本的权重为
对应的初始权重可以写成集合:
学习器可以任意选择。
step2:计算学习器1更新后的权重
学习器1:
原始数据集在x=2.5处一刀切,即x=0,1,2对应y=1,x=3,4,5,6,7,8,9对应y=-1。
对于学习器1,误判的个数有三个,分别是x=7,8,9对应的类。
则学习器1的误分类率:
学习器1对应的转换系数
得到新权重:
这里的规范化因子
step3:生成第一轮的决策函数
第一轮的决策函数现在可以写成:
第一轮的分类器为:
step4:第二轮学习器
学习器2:
原始数据集在x=8.5处一刀切,即x=0,1,2,3,4,5,6,7,8对应y=1,x=9对应y=-1。
此时对于学习器2,误判的个数有三个,分别是x=3,4,5对应的类。
新的误分类率需要加上示性函数:
学习器2对应的转换系数
经过两轮学习器后生成的决策函数:
对应的分类器:
此时通过两个学习器的叠加得到每个
例如,
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| y预测值 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | -1 |
x=3,4,5对应的分类错误,继续修改权重。
step5:更新第三轮权重
计算得到
step6:第三轮学习器
学习器3:
原始数据集在x=5.5处一刀切,即x=0,1,2,3,4,5对应y=-1,x=6,7,8,9对应y=1。
此时对于学习器3,误判的个数有4个,分别是x=0,1,2,9对应的类。
误分类率:
学习器3对应的转换系数
经过三轮学习器后生成的决策函数:
对应的分类器:
此时通过三个学习器的叠加得到每个
例如,
三轮学习器后y预测值的结果如下:
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| y预测值 | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
此时预测值与真实值完全一致。
#
10、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]Freund, Yoav; Schapire, Robert E. A Decision-Theoretic Generalization of on-Line Learning and an Application to Boosting. 1995. CiteSeerX: 10.1.1.56.9855.
[3]O. Duda, Peter E. Hart, David G. Stork, Pattern Classification, 2nd Edition, Wiley, 2000, ISBN 978-0-471-05669-0