bp神经网络分类
# 1、作用
bp神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。bp神经网络的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的分类错误率最小。
# 2、输入输出描述
输入:自变量X为1个或1个以上的定类或定量变量,因变量Y为一个定类变量。
输出:模型的分类结果和模型分类的评价效果。
# 3、案例示例
根据红酒的颜色强度,脯氨酸,类黄酮等变量,生成一个能够区分琴酒,雪莉,贝尔摩德三种品种的红酒的bp神经网络。
# 4、案例数据

bp神经网络分类案例数据
# 5、案例操作
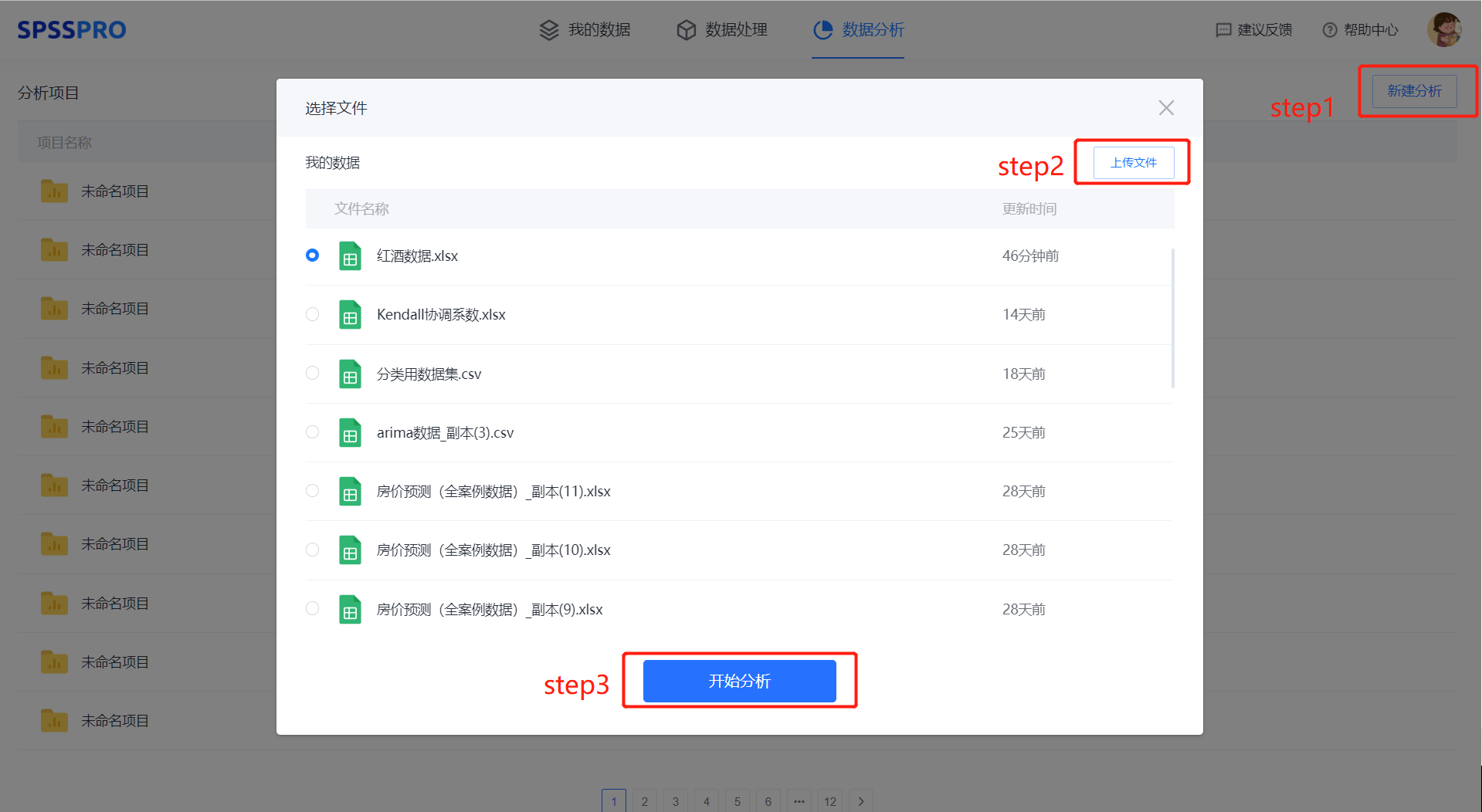
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;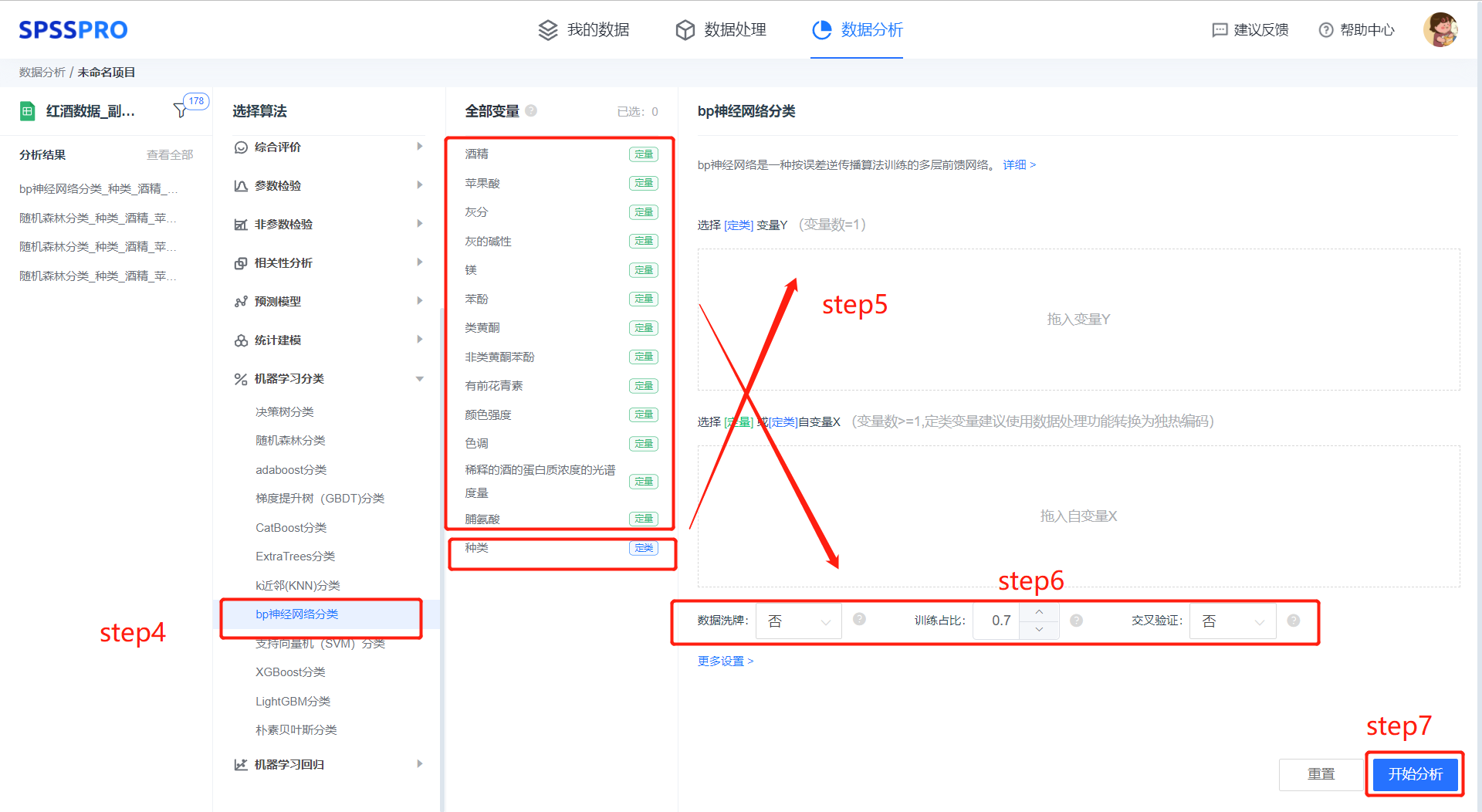
step4:选择【bp神经网络分类】;
step5:查看对应的数据数据格式,按要求输入【bp神经网络分类】数据;
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step7:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果1:模型参数 
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
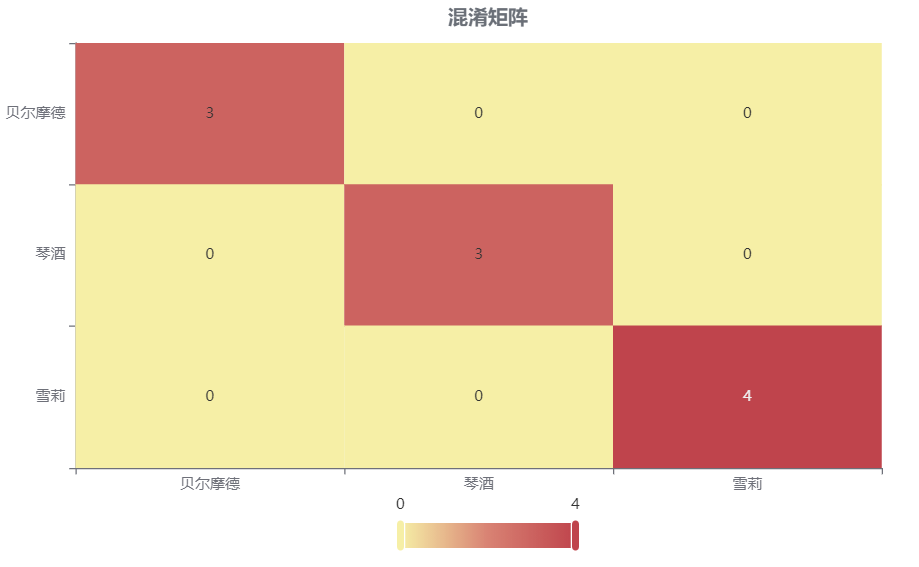
输出结果2:混淆矩阵热力图

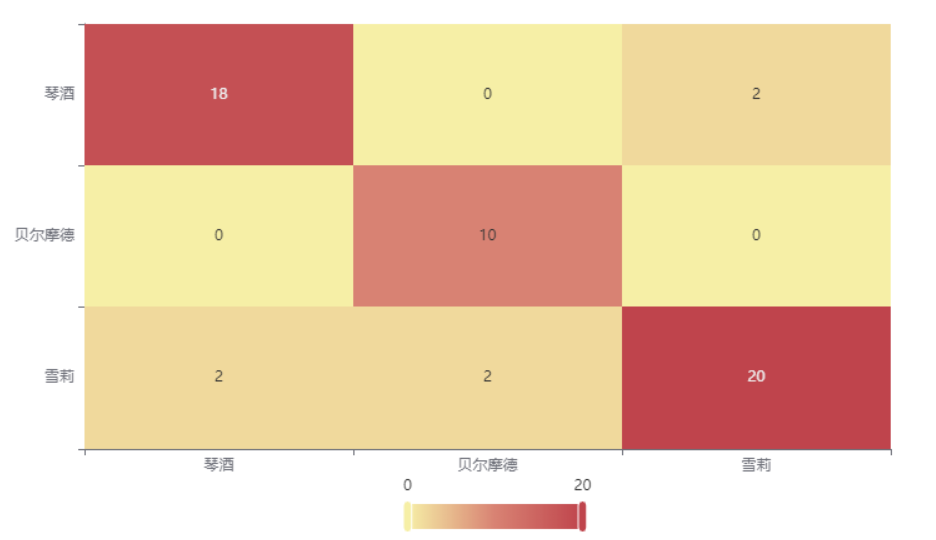
图表说明: 上表以热力图的形式展示了混淆矩阵,可以通过右上角切换在测试数据集和训练数据集中的情况。
分析:
上图是训练集的分类结果,绝大部分样本分类正确,只有1个被分错的样本,说明分类效果较好。
下图是测试集的分类结果,绝大部分样本分类正确,只有6个被分错的样本,说明训练集训练出来的模型结果是有效实用的,分类效果较好。
输出结果4:模型评估结果
图表说明: 上表中展示了训练集和测试集的分类评价指标,通过量化指标来衡量bp神经网络对训练、测试数据的分类效果。
● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用F1指标。
分析:
训练集的各分类评价指标都大于0.9,说明模型在训练集的分类效果较好,模型具有实用性。
测试集的各分类评价指标都大于0.9,说明模型在测试集的分类效果较好,模型具有实用性。
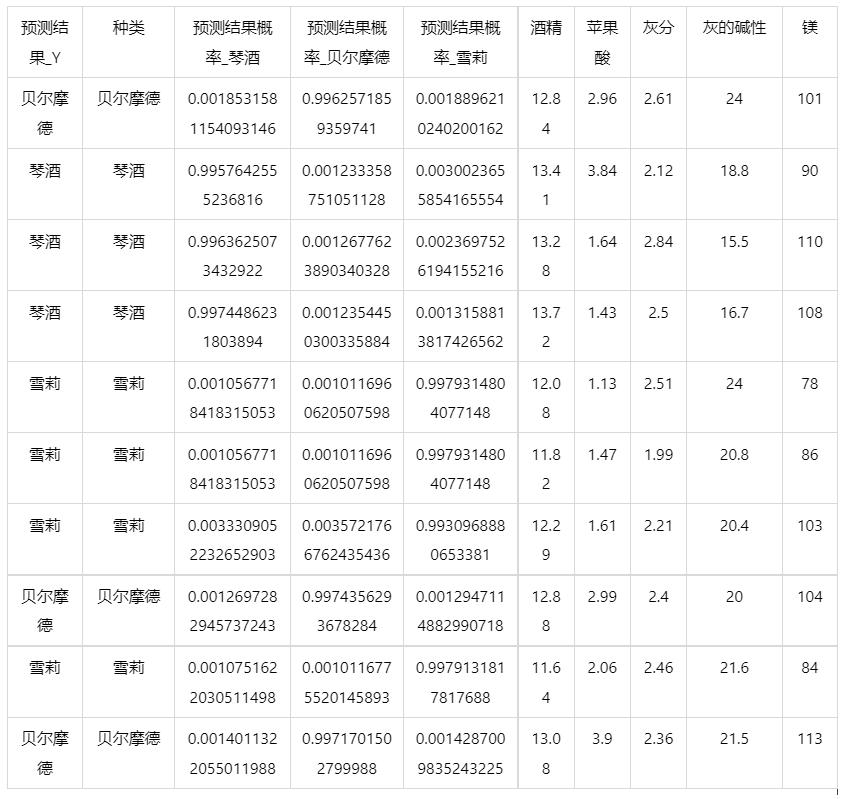
输出结果5:测试数据预测评估结果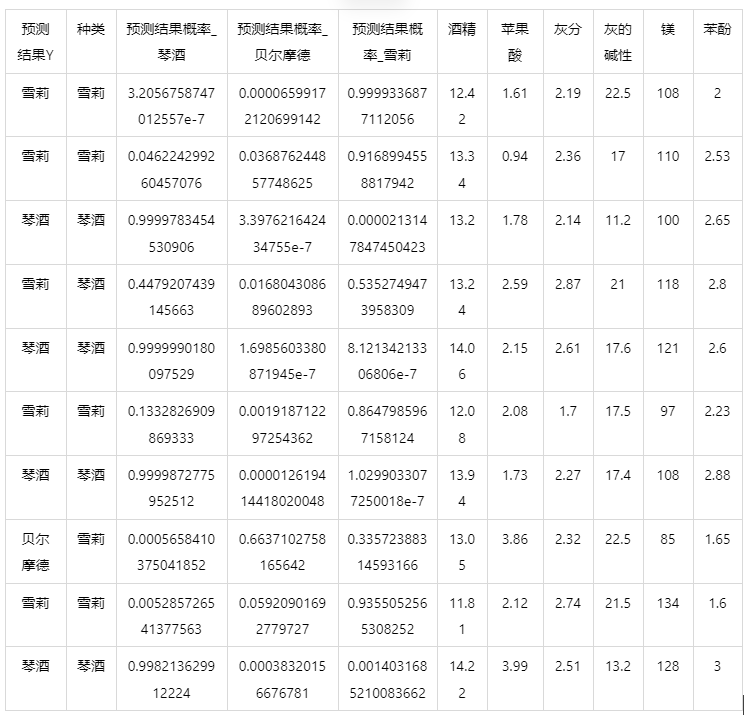
图表说明: 上表格为预览结果,只显示部分数据,全部数据请点击下载按钮导出。
上表展示了bp神经网络模型对测试数据的分类结果,第一列是预测结果,第二列是因变量真实值,第三、四、五列分别是对所属每一个分类水平概率的预测结果,最终分类预测结果值是拥有最大预测概率的分类组别。其余列是各自变量的值。
输出结果6:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
●当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
●当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况1:在上面模型评估后,模型分类结果较好,具有实用性,这时我们将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
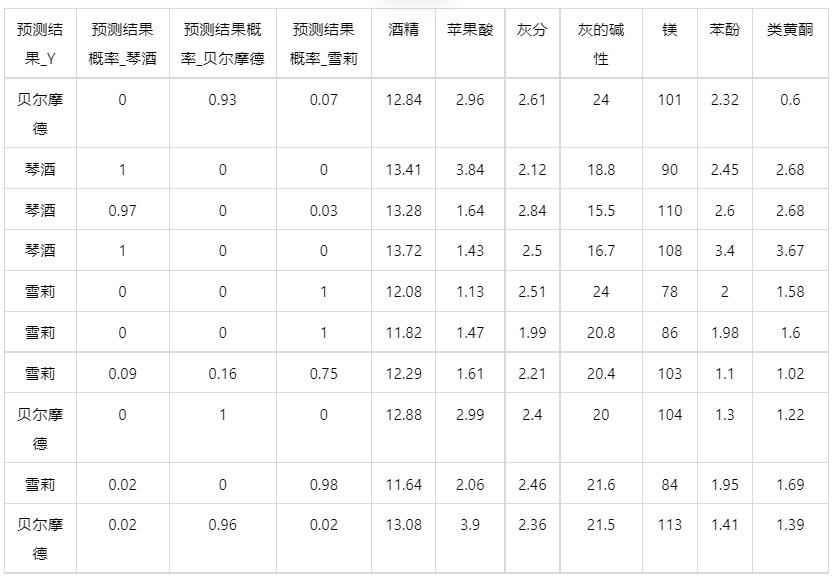
情况2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到当前数据分类混淆矩阵和分类评价效果。

# 7、注意事项
- 由于bp神经网络具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用SPSSPRO客户端进行。
- bp神经网络的参数修改需要使用SPSSPRO客户端进行。
# 8、模型理论
BP神经网络是一种多层的前馈神经网络,其主要的特点是:信号是前向传播的,而误差是反向传播的。具体来说,对于如下的只含一个隐层的神经网络模型:
BP神经网络的过程主要分为两个阶段,第一阶段是信号的前向传播,从输入层经过隐含层,最后到达输出层;第二阶段是误差的反向传播,从输出层到隐含层,最后到输入层,依次调节隐含层到输出层的权重和偏置,输入层到隐含层的权重和偏置。
以一个三层BP神经网络举例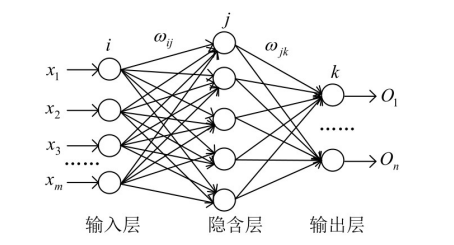
隐含层的输出量设为Fj,输出 层的输m量设为Ok, 系统 的激励函数设为G, 学习速率设为β, 则其三个层之间有如下数学关系: 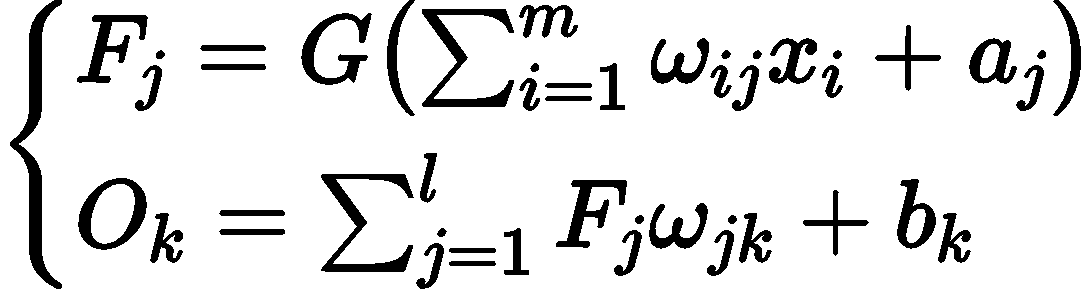
系统期望的输出量设为Tk,则系统的误差E可由 实际输出值和期望目标值的方差表示,具体关系表达式如下: 
并令![]() ,利用梯度下降原理, 则系统权值和偏置的更新公式如下:
,利用梯度下降原理, 则系统权值和偏置的更新公式如下:
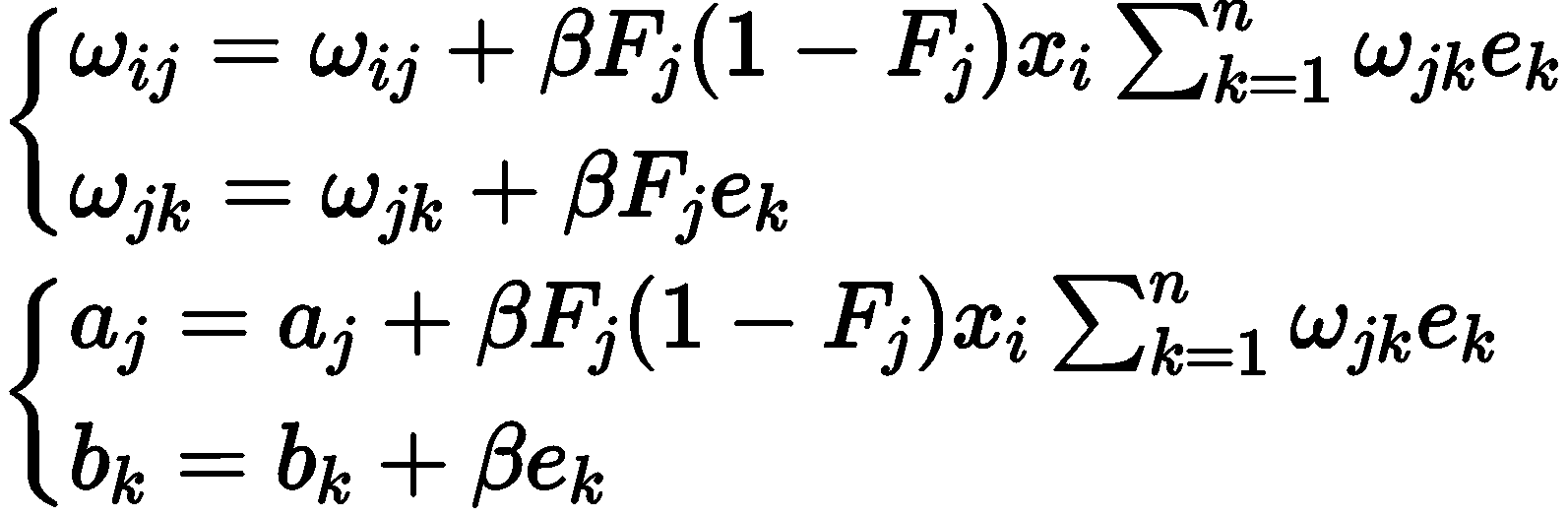
# 9、手推步骤
| 身高(cm) | 体重(kg) | 性别 |
|---|---|---|
| 175 | 63 | 男 |
| 170 | 55 | 男 |
| 165 | 50 | 女 |
| 178 | 63 | 男 |
| 174 | 55 | 女 |
| 169 | 49 | 女 |
现有一个数据集包含人的身高体重和性别。
假设要预测一个新样本的性别,身高 = 170 cm,体重 = 58 kg。BP神经网络分类算法求解过程如下:
step1:数据预处理
为了消除数据间的量纲差异,将数据进行归一化处理。
身高范围(165~178),体重范围(49~63)
归一化后的数据:
| 身高(norm) | 体重(norm) | 目标(T1,T2) |
|---|---|---|
| 0.7692 | 1.0 | (1, 0) |
| 0.3846 | 0.4286 | (1, 0) |
| 0.0 | 0.0714 | (0, 1) |
| 1.0 | 1.0 | (1, 0) |
| 0.6923 | 0.4286 | (0, 1) |
| 0.3077 | 0.0 | (0, 1) |
预测样本归一化后:(0.3846,0.6429)
step2:设置初始参数
输入层2节点(m),隐藏层2节点(l),输出层2节点(n)。
设置初始权重:
输入→隐藏层W
隐藏层→输出层V
激活函数
输出层线性,设置学习率
step3:训练样本1
样本1:X=[0.7692,1.0],T=[1,0]
前向传播:
隐藏层输入:
隐藏层输出:
输出层(softmax):
输出层误差:
反向传播:
更新V:
更新b:
更新W:
j=1时:
j=2时:
更新W:
更新a:
step4:训练其余样本
重复步骤3训练其余5个样本,得到最终权重:
step5:预测样本
预测测试样本X=[0.3846,0.6429]:
隐藏层:
输出层:
因为
#
10、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] 周志华.机器学习.北京:清华大学出版社,2016:pp.121-139, 298-300
[3]李航.统计学习方法.北京:清华大学出版社,2012:第七章,pp.95-135