决策树回归
# 1、作用
决策树中每个内部节点都是一个分裂问题:指定了对实例的某个属性的测试,它将到达该节点的样本按照某个特定的属性进行分割,并且该节点的每一个后继分支对应于该属性的一个可能值。回归树的叶节点所含样本中,其输出变量的平均值就是预测结果。
# 2、输入输出描述
输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定量变量。
输出:模型输出的决策树结构图及模型的预测效果。
# 3、案例示例
根据房子的户型、电梯、面积、房龄、装修程度、容积率和绿化率,使用决策树方法预估该房子的房价。
# 4、案例数据
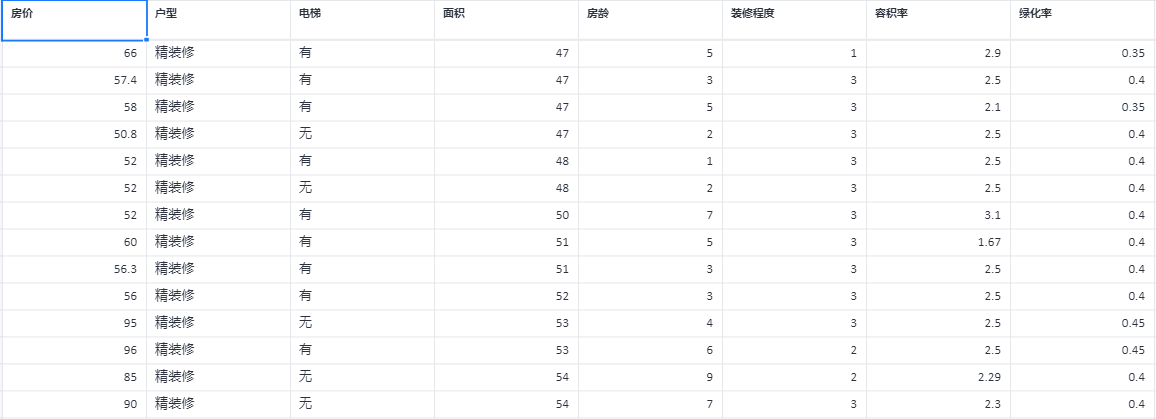
决策树回归案例数据
# 5、案例操作
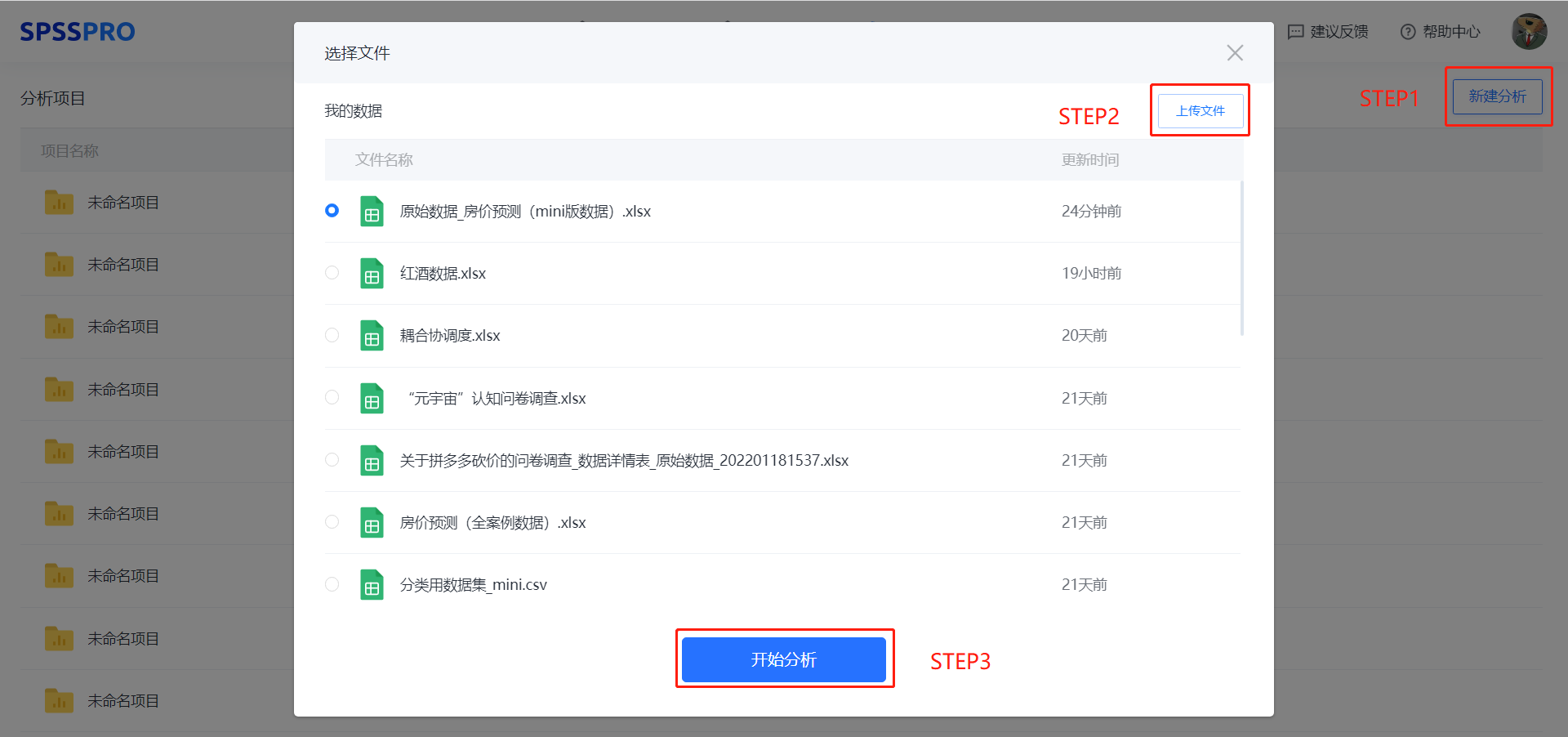
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;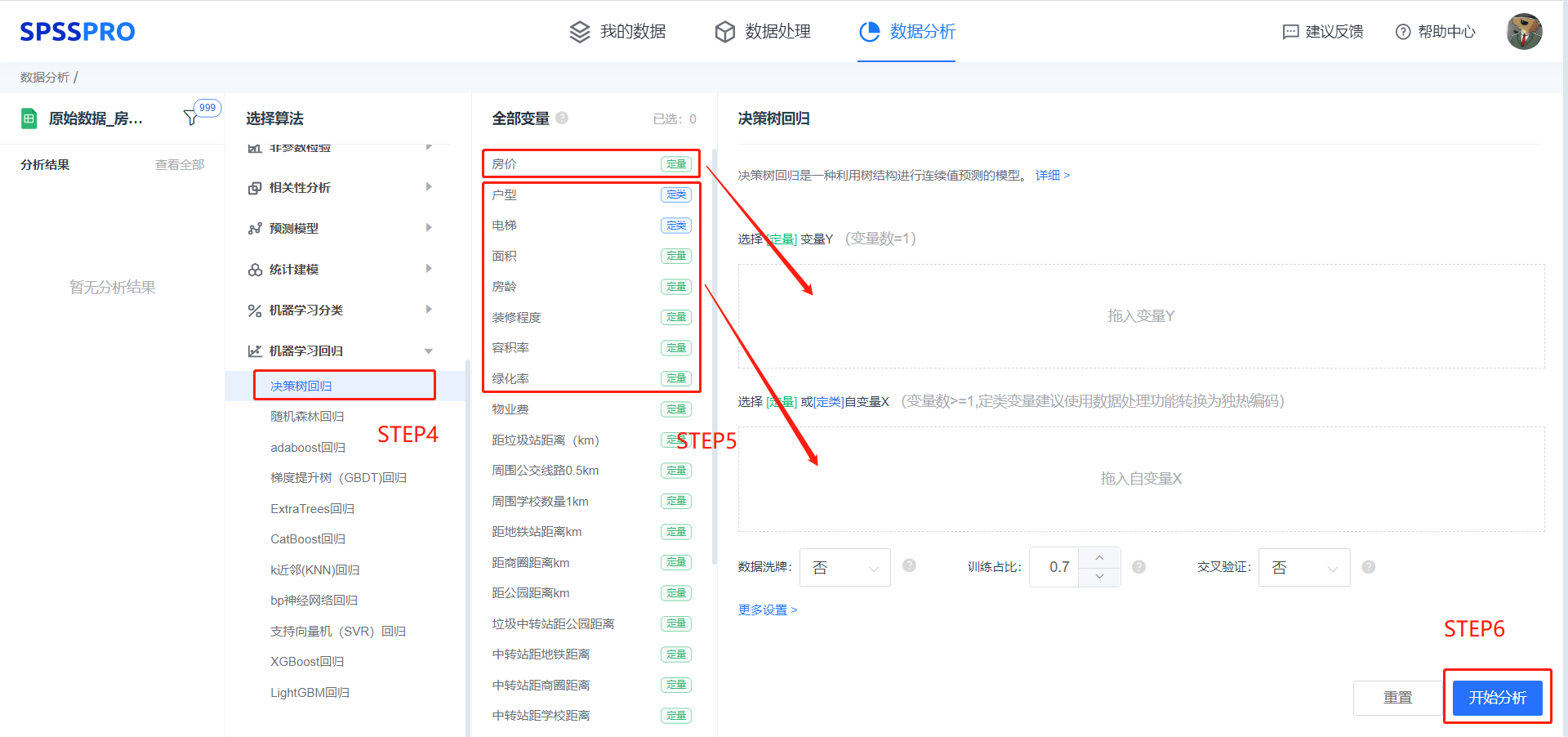
step4:选择【决策树回归】;
step5:查看对应的数据数据格式,按要求输入【决策树回归】数据;
step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:模型参数
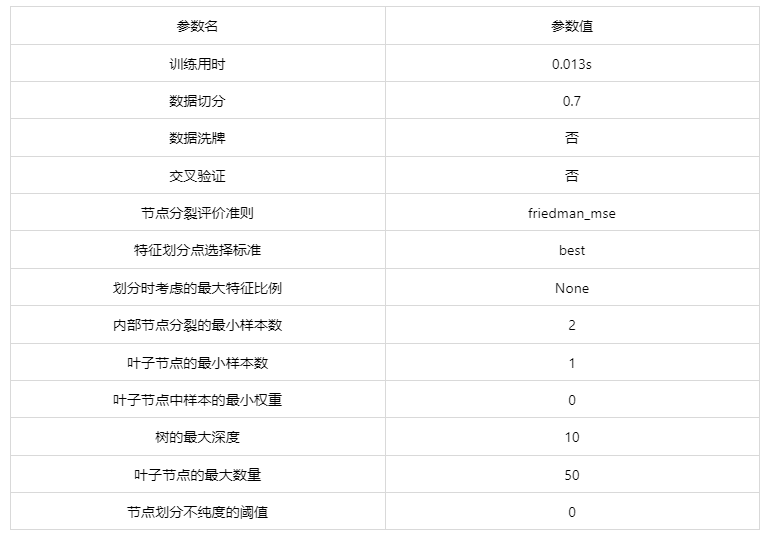
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
输出结果 2:决策树结构
图表说明:
上图展示了部分决策树结构(因为过大需要下载至本地查看),内部节点给出了被分枝特征的具体切分情况,即根据某个特征的某个切分值进行划分。(若节点数大于 30,点击下载按钮查看决策树结构)
● mse/friedman_mse/mae 等用以确定对哪一个特征进行切分。
● 样本数量是该节点拥有的样本数量。
● 节点样本均值是该节点全部样本的均值。
PS:特别注意的是,若节点数大于 30,SPSSPRO 提供下载按钮查看决策树结构;若节点数大于 2000,由于树结构渲染模糊,SPSSPRO 不提供下载导出;
输出结果 3:特征重要性

图表说明:上柱形图或表格展示了各特征(自变量)的重要性比例。(附:有时候可以利用决策树的特征重要性反推该变量在实际生活中的价值,因为该重要性往往决定分类结果。)
分析:可见影响房价最重要的属性是房屋的面积和容积率。
输出结果 4:模型评估结果
图表说明: 上表中展示了交叉验证集、训练集和测试集的预测评价指标,通过量化指标来衡量决策树的预测效果。其中,通过交叉验证集的评价指标可以不断调整超参数,以得到可靠稳定的模型。
● MSE(均方误差): 预测值与实际值之差平方的期望值。取值越小,模型准确度越高。
● RMSE(均方根误差):为 MSE 的平方根,取值越小,模型准确度越高。
● MAE(平均绝对误差): 绝对误差的平均值,能反映预测值误差的实际情况。取值越小,模型准确度越高。
● MAPE(平均绝对百分比误差): 是 MAE 的变形,它是一个百分比值。取值越小,模型准确度越高。
● R²: 将预测值跟只使用均值的情况下相比,结果越靠近 1 模型准确度越高。
分析:MSE/RMSE/MAE/MAPE 不算太大,R 方在 0.797,模型拟合情况优秀。
输出结果 5:测试数据预测评估结果
图表说明: 上表格为预览结果,只显示部分数据,全部数据请点击下载按钮导出。
上表展示了决策树模型对测试数据的回归结果。
输出结果 6:测试数据预测评估结果 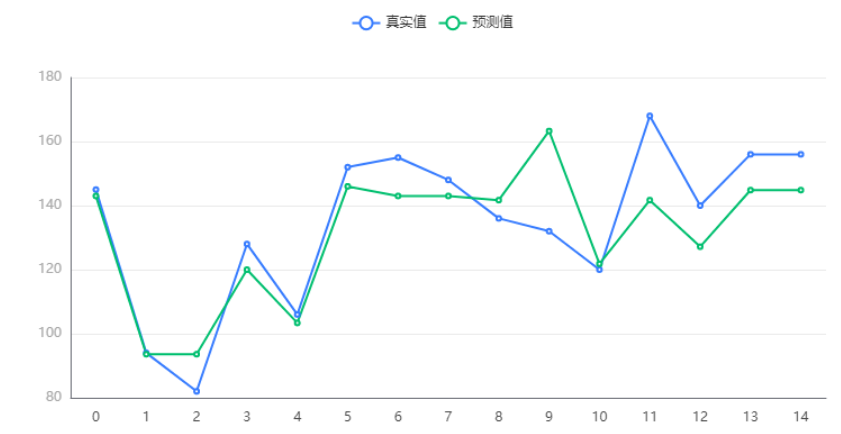
图表说明:上图中展示了决策树对测试数据的预测情况。
输出结果 7:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
● 当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
● 当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况 1:在上面模型评估后,模型预测结果较好,具有实用性,这时我们将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
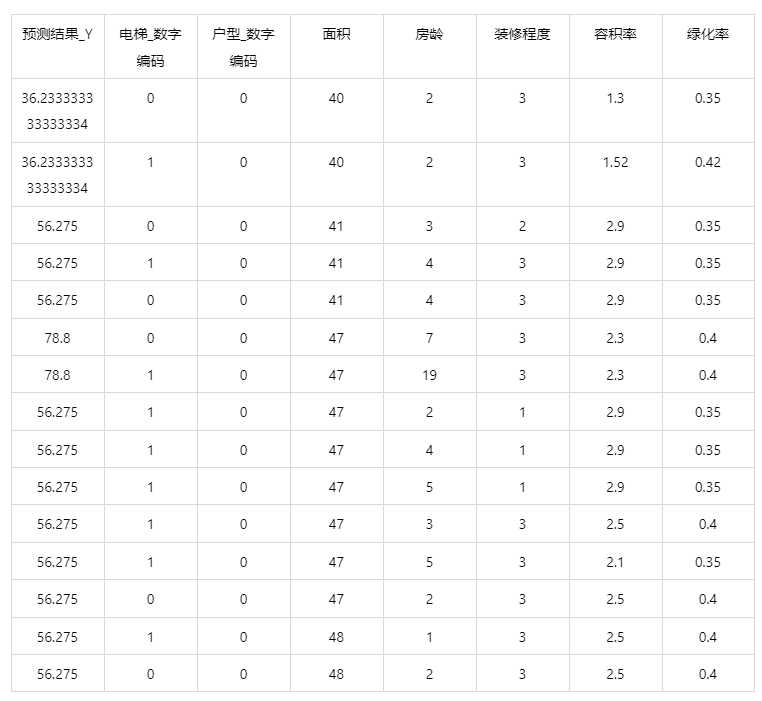
情况 2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到评价效果。
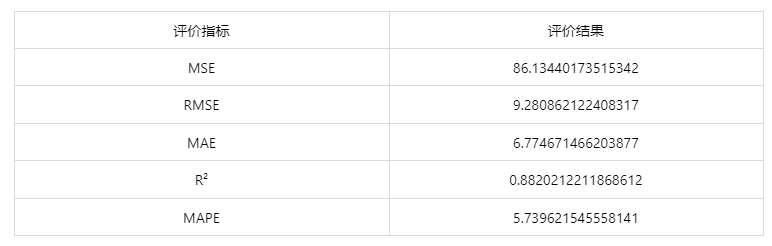
图表说明:上表中展示了真实值和预测值的评价指标,通过量化指标来衡量决策树回归对上传数据的预测效果。
● MSE(均方误差): 预测值与实际值之差平方的期望值。取值越小,模型准确度越高。
● RMSE(均方根误差):为 MSE 的平方根,取值越小,模型准确度越高。
● MAE(平均绝对误差): 绝对误差的平均值,能反映预测值误差的实际情况。取值越小,模型准确度越高。
● MAPE(平均绝对百分比误差): 是 MAE 的变形,它是一个百分比值。取值越小,模型准确度越高。
● R²: 将预测值跟只使用均值的情况下相比,结果越靠近 1 模型准确度越高。

# 7、注意事项
- 由于决策树具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用 SPSSPRO 客户端进行。
- 决策树无法像传统模型一样得到确定的方程,在每个决策节点上,所选择的分割特征决定了最终的分类结果,通常通过测试数据分类效果来对模型进行评价。
- 决策树的参数修改需要使用 SPSSPRO 客户端进行。
# 8、模型理论
决策树是一树状结构,它从根节点开始,对数据样本进行测试,根据不同的结果将数据样本划分成不同的数据样本子集,每个数据样本子集构成——子节点 。它是通过一系列规则对数据进行分类的过程。它提供一种在什么条件下会得到什么值的类似规则的方法。
决策树分为分类树和回归树两种,分类树对离散变量做决策树 ,回归树对连续变量做决策树。
决策树作为一棵树,树的根节点是整个数据集合空间,每个分节点是对一个单一变量的测试,该测试将数据集合空间分割成两个或更多块。每个叶节点是属于单一类别的记录。构造决策树的过程为:首先寻找初始分裂。整个训练集作为产生决策树的集合,训练集每个记录必须是已经分好类的。决定哪个属性域(Field)作为目前最好的分类指标。 一般的做法是穷尽所有的属性域,对每个属性域分裂的好坏做出量化,计算出最好的一个分裂 。
不同的算法的计算属性域分裂的标准也不太相同 。其次, 重复第一步, 直至每个叶节点内的记录都属于同一类, 增长到一棵完整的树。构造决策树的目的是找出属性和类别间的关系 , 用它来预测将来未知类别的记录的类别。
决策树的生产过程本质是对训练样本集的不断分组过程。决策树上的各个分枝是在数据不断分组的过程中逐渐生长出来的。决策树生长的核心技术是测试属性选择问题。
最初的ID3 算法用一个叫做增益标准来选择需要检验的属性,它基于信息论中熵的概念。设 S 是 s 个数据样本的集合。假定类标号属性具有 m 个不同值,定义 m 个不同类 Ci(i=1,…,m)。设 si 是类 Ci 中的样本数。对一个给定的样本分类所需的期望信息由下式给出:
![]()
其中 pi=si/s 是任意样本属于 Ci 的概率。注意,对数函数以 2 为底,其原因是信息用二进制编码。
设属性 A 具有 v 个不同值{a1,a2,…,av}。可以用属性 A 将 S 划分为 v 个子集{S1,S2,…,Sv},其中 Sj 中的样本在属性 A 上具有相同的值 aj(j=1,2,…,v)。设 sij 是子集 Sj 中类 Ci 的样本数。由 A 划分成子集的熵或信息期望由下式给出:
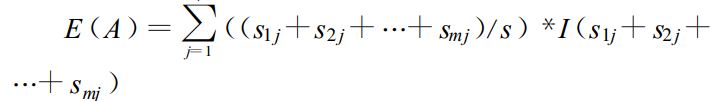
熵值越小,子集划分的纯度越高。对于给定的子集 Sj,其信息期望为:
![]()
其中 pij=sij/sj 是 Sj 中样本属于 Ci 的概率。
在属性 A 上分枝将获得的信息增益是:
![]()
C4.5 算法在决策树各级结点上选择属性时,用增益比率(gain ratio)作为属性的选择标准。
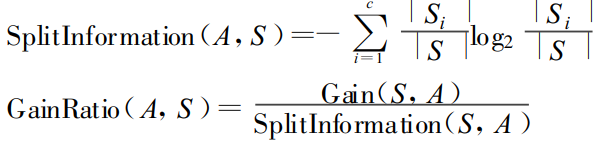
SLIQ,SPRINT,PUBLIC 算法中,使用 gini 指标(gini index)代替信息量(Information)作为属性选择的标准。 gini 指标比信息量性能更好,且计算方便。对数据集包含 n 个类的数据集 S,gini(S)定义为:
![]()
式中,pj 是 S 中第 j 类数据的频率。gini 越小,Information Gain 越大。
# 9、手推步骤
| 花萼长度 | 花萼宽度 | 花瓣长度 | 花瓣宽度 |
|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 |
| 4.9 | 3.0 | 1.4 | 0.2 |
| 4.7 | 3.2 | 1.3 | 0.2 |
| 5.0 | 3.3 | 1.4 | 0.2 |
| 7.0 | 3.2 | 4.7 | 1.4 |
| 6.4 | 3.2 | 4.5 | 1.5 |
| 6.9 | 3.1 | 4.9 | 1.5 |
| 5.7 | 2.8 | 4.1 | 1.3 |
| 6.3 | 3.3 | 6.0 | 2.5 |
| 5.8 | 2.7 | 5.1 | 1.9 |
| 7.1 | 3.0 | 5.9 | 2.1 |
| 5.9 | 3.0 | 5.1 | 1.8 |
现有12组鸢尾花数据,用决策树回归算法根据花萼长度、花萼宽度和花瓣长度预测花瓣宽度的过程如下:
step1:计算整个数据集的均方误差
均方误差公式
目标值:
均值:
为简化计算过程,这里设置树深=3。
step2:确定最佳分裂点
决策树中需要将所有相邻值间的数作为可能分裂点,进行一一计算,这里为了减少计算量只计算个别分裂点的加权MSE。
特征1:花萼长度
分裂点
左节点:y = [0.2,0.2,0.2,0.2],均值=0.2,
右节点:y = [1.3,1.9,1.8,2.5,1.5,1.5,1.4,2.1],均值=1.75,
加权
分裂点
左节点:y=[0.2,0.2],均值=0.2,
右节点:y=[0.2,0.2,1.3,1.9,1.8,2.5,1.5,1.5,1.4,2.1],均值=1.44,
加权
特征2:花萼宽度
分裂点
左节点:y=[1.9,1.3],均值=1.6,
右节点:y=[0.2,2.1,1.8,1.5,0.2,1.4,1.5,0.2,2.5,0.2],均值=1.16,
加权
分裂点
左节点:y=[1.9,1.3,0.2,2.1,1.8],均值=1.46,
右节点:y=[1.5,0.2,1.4,1.5,0.2,2.5,0.2],均值=1.07,
加权
特征3:花瓣长度
分裂点
左节点:y = [0.2,0.2,0.2,0.2],均值=0.2,
右节点:y = [1.3,1.9,1.8,2.5,1.5,1.5,1.4,2.1],均值=1.75,
加权
分裂点
左节点:y=[0.2,0.2,0.2,0.2,1.3],均值=0.42,
右节点:y=[1.5,1.4,1.5,1.9,1.8,2.1,2.5],均值=1.81,
加权
选择加权MSE最小的特征值作为分裂点,这里选择
step3:第一次分裂
左子节点:花瓣长度
右子节点:花瓣长度
step4:右子节点继续分裂
重复step2的步骤,右子节点包含y = [1.3,1.9,1.8,2.5,1.5,1.5,1.4,2.1]。为了简化计算,这里同样不对每一个可能分裂点都进行计算。
分裂点
左节点:y=[1.3,1.9,1.8],均值=1.667,
右节点:y = [2.5,1.5,1.5,1.4,2.1],均值=1.8,
加权
分裂点
左节点:y=[1.3,1.9,1.8,2.1],均值=1.775,
右节点:y = [2.5,1.5,1.5,1.4],均值=1.725,
加权
分裂点
左节点:y = [1.3,1.5,1.5,1.4],均值=1.425,
右节点:y = [1.9,1.8,2.5,2.1],均值=2.075,
加权
选择加权MSE最小的特征值作为分裂点,这里选择
右左子结点:花瓣长度
右右子节点:花瓣长度
当前树深为3,分裂结束。
step5:预测
根据决策树回归预测样本(花萼长度=5.7,花萼宽度=3.1,花瓣长度4.8)的花瓣宽度。
由
# 10、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]杨学兵,张俊.决策树算法及其核心技术[J].计算机技术与发展,2007(01):43-45.