bp神经网络回归
# 1、作用
bp 神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。bp 神经网络的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
# 2、输入输出描述
输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定量变量。
输出:模型输出的结果值及模型预测效果。
# 3、案例示例
研究“幸福感”的影响因素,有四个变量可能对幸福感有影响,他们分别是:经济收入、受教育程度、身体健康、情感支持。建立支持 bp 神经网络模型来预测幸福度。
# 4、案例数据
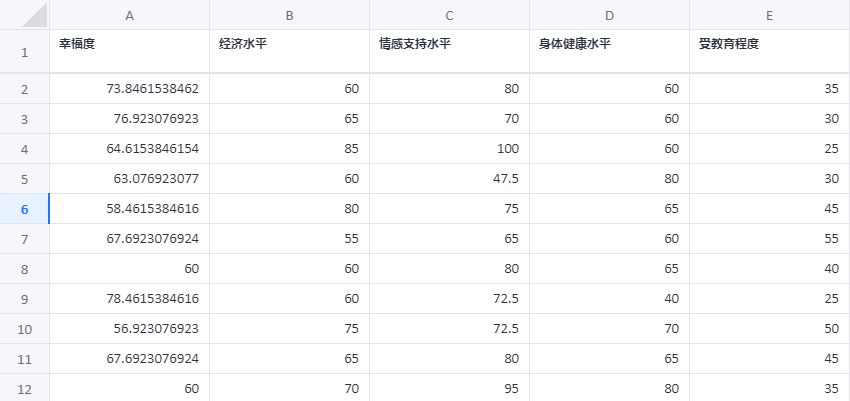
bp 神经网络回归案例数据
# 5、案例操作
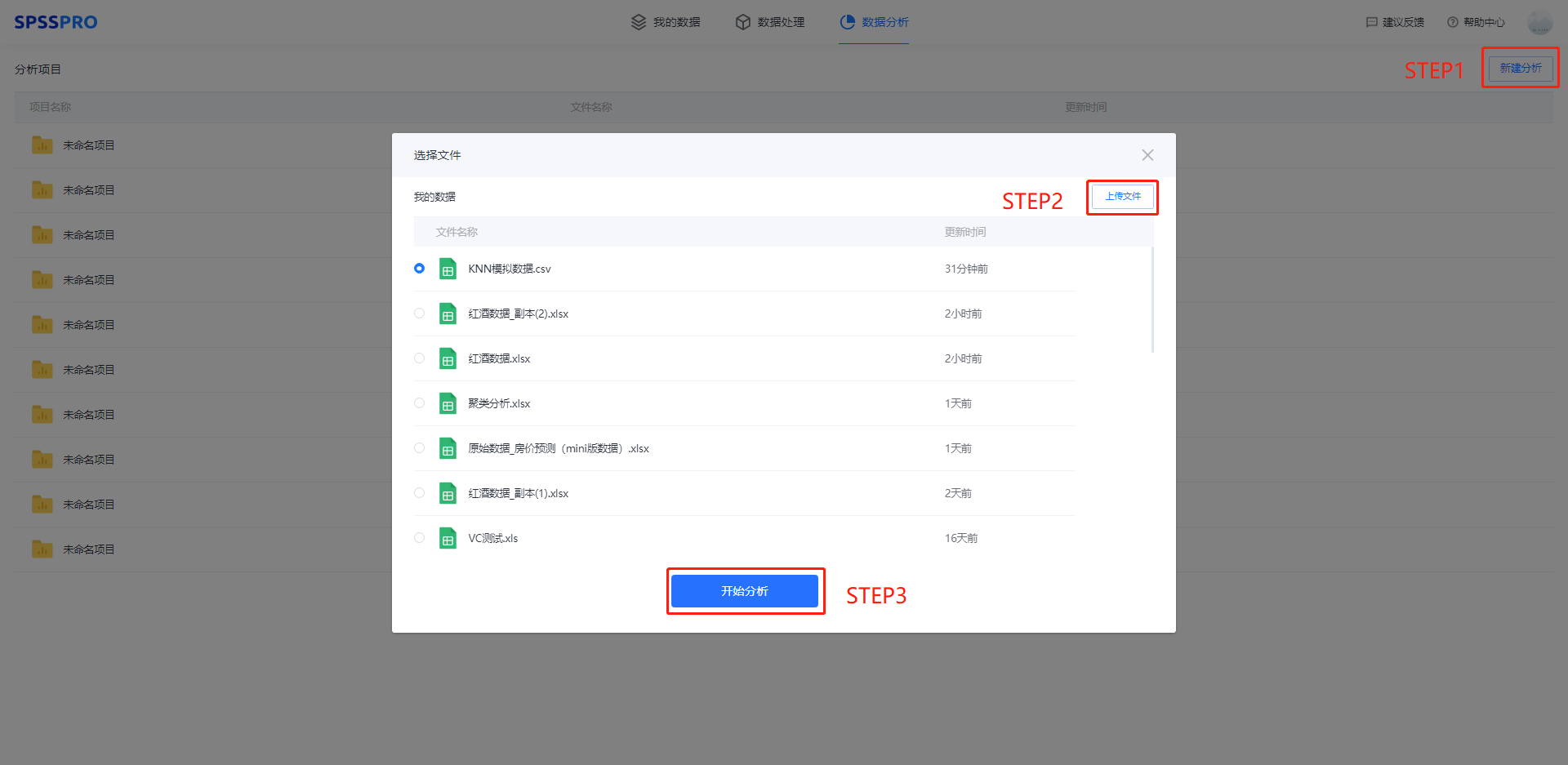
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
step4:选择【bp 神经网络回归】;
step5:查看对应的数据数据格式,按要求输入【bp 神经网络回归】数据(注:bp 神经网络中定类自变量建议进行编码,定量变量建议标准化);
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:模型参数
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
输出结果 2:模型评估结果
图表说明: 上表中展示了训练集和测试集的预测评价指标,通过量化指标来衡量 bp 神经网络的预测效果。
● MSE(均方误差): 预测值与实际值之差平方的期望值。取值越小,模型准确度越高。
● RMSE(均方根误差):为 MSE 的平方根,取值越小,模型准确度越高。
● MAE(平均绝对误差): 绝对误差的平均值,能反映预测值误差的实际情况。取值越小,模型准确度越高。
● MAPE(平均绝对百分比误差): 是 MAE 的变形,它是一个百分比值。取值越小,模型准确度越高。
● R²: 将预测值跟只使用均值的情况下相比,结果越靠近 1 模型准确度越高。
分析:
训练集测试集的各预测评价指标值相差不大,就平均绝对百分比误差来看,误差率仅 9%左右,模型预测良好。
输出结果 3:测试数据预测结果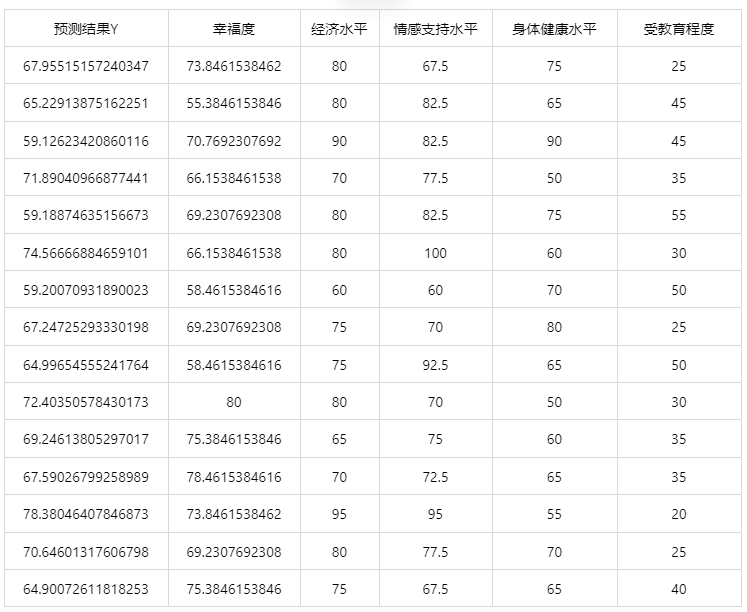
图表说明: 上表格为预览结果,只显示部分数据,全部数据请点击下载按钮导出。
上表展示了 bp 神经网络模型对测试数据的预测结果,第一列是预测结果,第二列是因变量真实值,其余列是各自变量的值。
输出结果 4:测试数据预测图
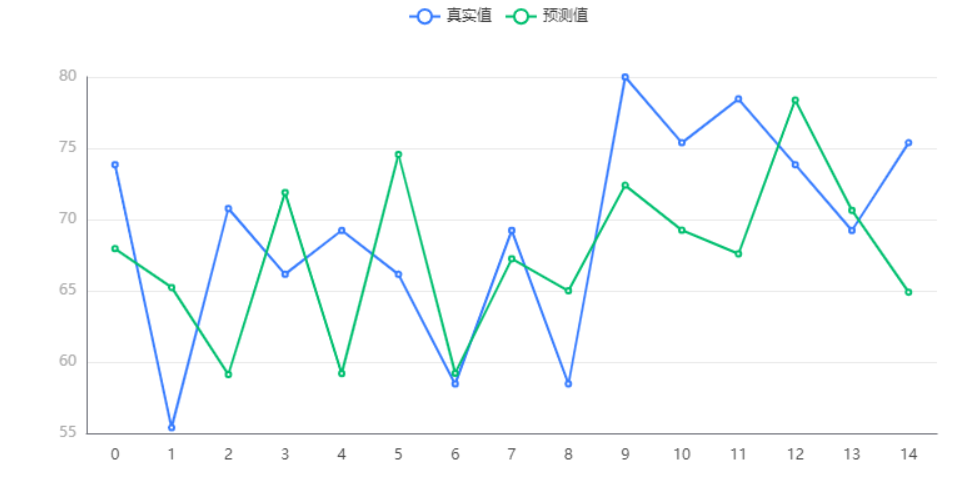
图表说明:上图中展示了 bp 神经网络回归对测试数据的预测情况。
输出结果 5:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
● 当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
● 当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况 1:在上面模型评估后,模型分类结果较好,具有实用性,这时我们将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
经上述操作后,得到以下结果: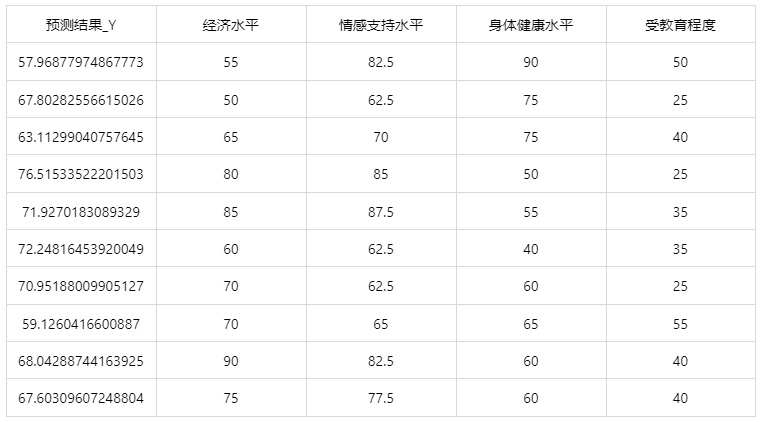
情况 2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到当前应用数据预测评估效果。
经上述操作后,得到以下结果:
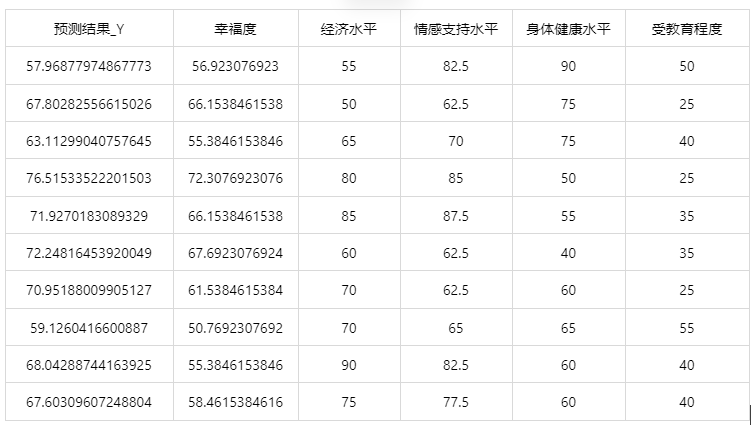
# 7、注意事项
- 由于 bp 神经网络具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用 SPSSPRO 客户端进行。
- bp 神经网络的参数修改需要使用 SPSSPRO 客户端进行。
# 8、模型理论
BP 神经网络是一种多层的前馈神经网络,其主要的特点是:信号是前向传播的,而误差是反向传播的。具体来说,对于如下的只含一个隐层的神经网络模型:
BP 神经网络的过程主要分为两个阶段,第一阶段是信号的前向传播,从输入层经过隐含层,最后到达输出层;第二阶段是误差的反向传播,从输出层到隐含层,最后到输入层,依次调节隐含层到输出层的权重和偏置,输入层到隐含层的权重和偏置。
以一个三层 BP 神经网络举例
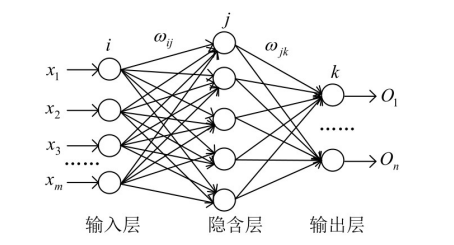
隐含层的输出量设为 Fj,输出 层的输 m 量设为 Ok, 系统 的激励函数设为 G, 学习速率设为 β, 则其三个层之间有如下数学关系:
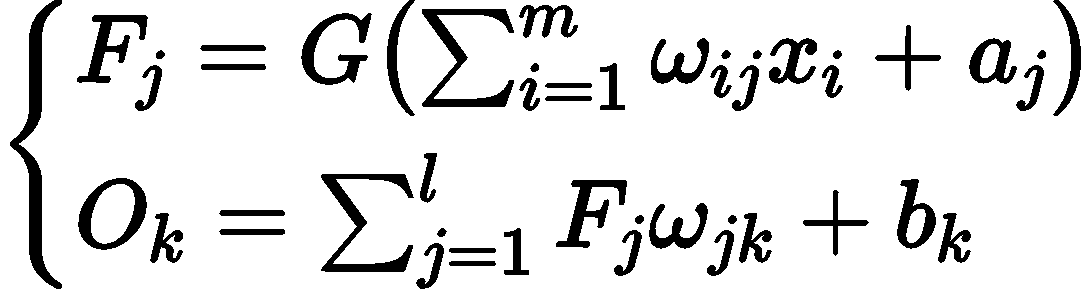
系统期望的输出量设为 Tk,则系统的误差 E 可由 实际输出值和期望目标值的方差表示,具体关系表达式如下:

并令
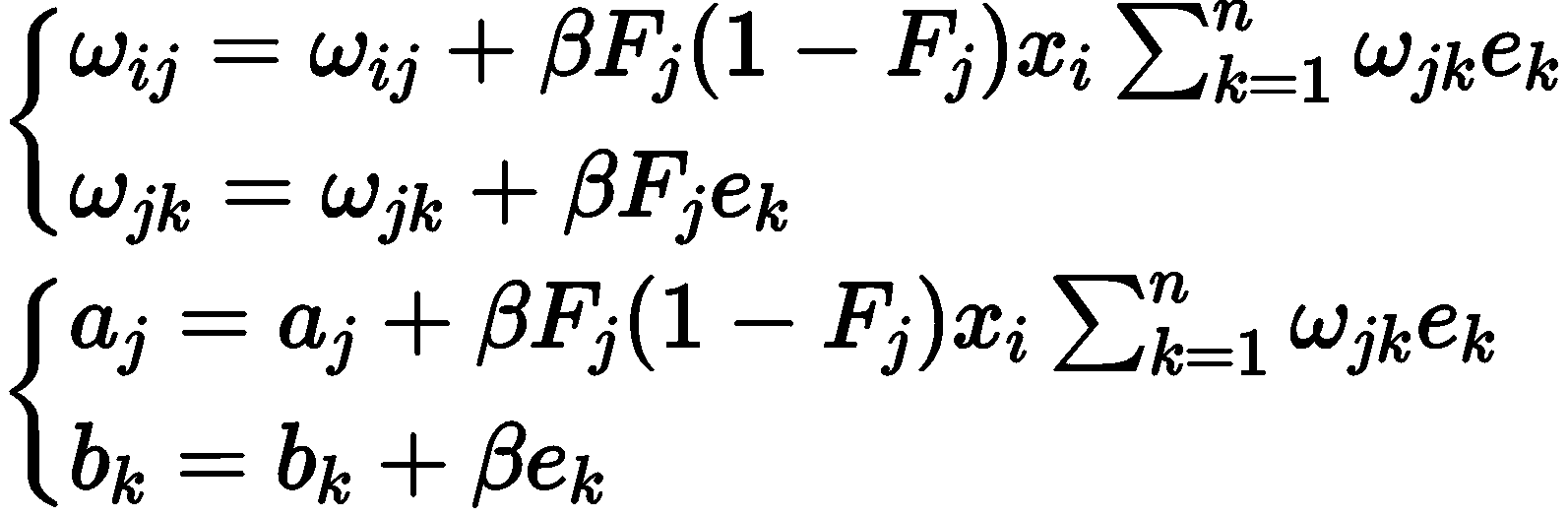
# 9、手推步骤
| 编号 | 年龄 | 体重(kg) | 身高 |
|---|---|---|---|
| 0 | 5 | 20 | 1.1 |
| 1 | 7 | 30 | 1.3 |
| 2 | 21 | 70 | 1.7 |
| 3 | 30 | 60 | 1.8 |
| 4 | 25 | 65 | ? |
现有四组训练数据,用BP神经网络回归预测第五组数据身高的过程如下:
step1:数据预处理
为了消除数据间的量纲差异,将数据进行归一化处理。
归一化公式:
归一化后的数据:
| 编号 | 年龄 | 体重 | 身高 |
|---|---|---|---|
| 0 | 0.00 | 0.00 | 0.0000 |
| 1 | 0.08 | 0.20 | 0.2857 |
| 2 | 0.64 | 1.00 | 0.8571 |
| 3 | 1.00 | 0.80 | 1.0000 |
预测样本归一化后:(0.80,0.90)
step2:设置初始参数
输入层2节点(m),隐藏层2节点(l),输出层1节点(n)
设置初始权重:
输入层 i→ 隐藏层j的权重:
隐藏层 j → 输出层k的权重(这里 k=1):
隐藏层激活函数:
学习率:
训练轮次=100
step3:训练样本1
样本1:X=(0.00,0.00),T=0.00
前向传播:
隐藏层输入:
隐藏层输出:
输出层(线性):
输出层误差:
反向传播:
更新
更新
更新
更新
step4:继续训练 用更新数据重复step3步骤继续训练其余样本,训练100轮次后得到最终权重:
这里的最终权重并非真实值,是为了方便展示下一步预测样本的过程。
step5:预测样本
新样本:X=(0.80,0.90)
隐藏层:
输出层:
反归一化:
所以样本的预测身高为1.6597。
# 10、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] 周志华.机器学习.北京:清华大学出版社,2016:pp.121-139, 298-300
[3]李航.统计学习方法.北京:清华大学出版社,2012:第七章,pp.95-135