随机森林回归
# 1、作用
随机森林回归是在生成众多决策树的过程中,是通过对建模数据集的样本观测和特征变量分别进行随机抽样,每次抽样结果均为一棵树,且每棵树都会生成符合自身属性的规则和判断值,而森林最终集成所有决策树的规则和判断值,实现随机森林算法的回归。
# 2、输入输出描述
输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定量变量。
输出: 模型输出的结果值及模型预测效果。
# 3、案例示例
根据房子的户型、电梯、面积、房龄、装修程度、容积率和绿化率,使用随机森林方法预估该房子的房价。
# 4、案例数据

随机森林回归案例数据
# 5、案例操作
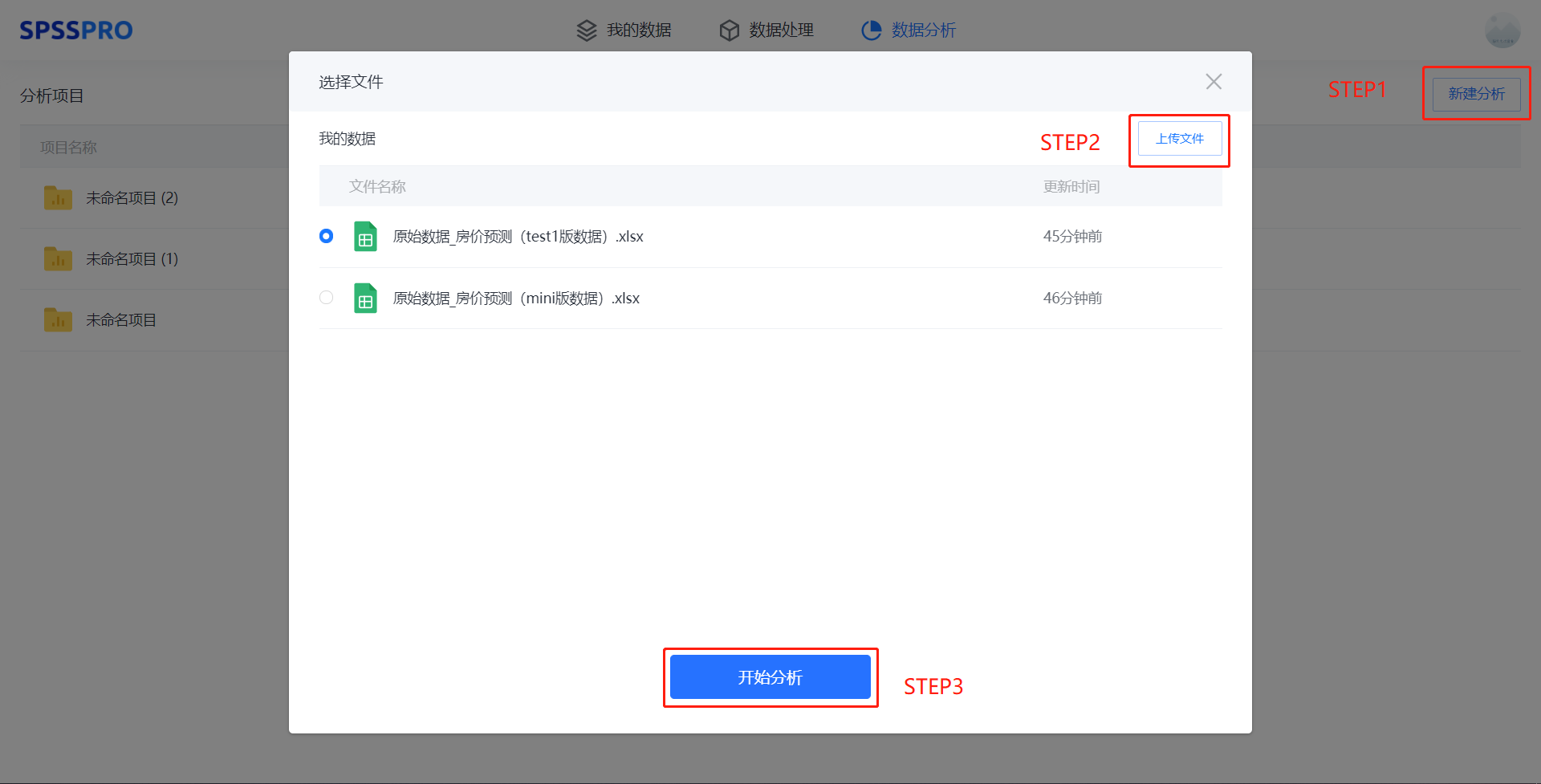
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;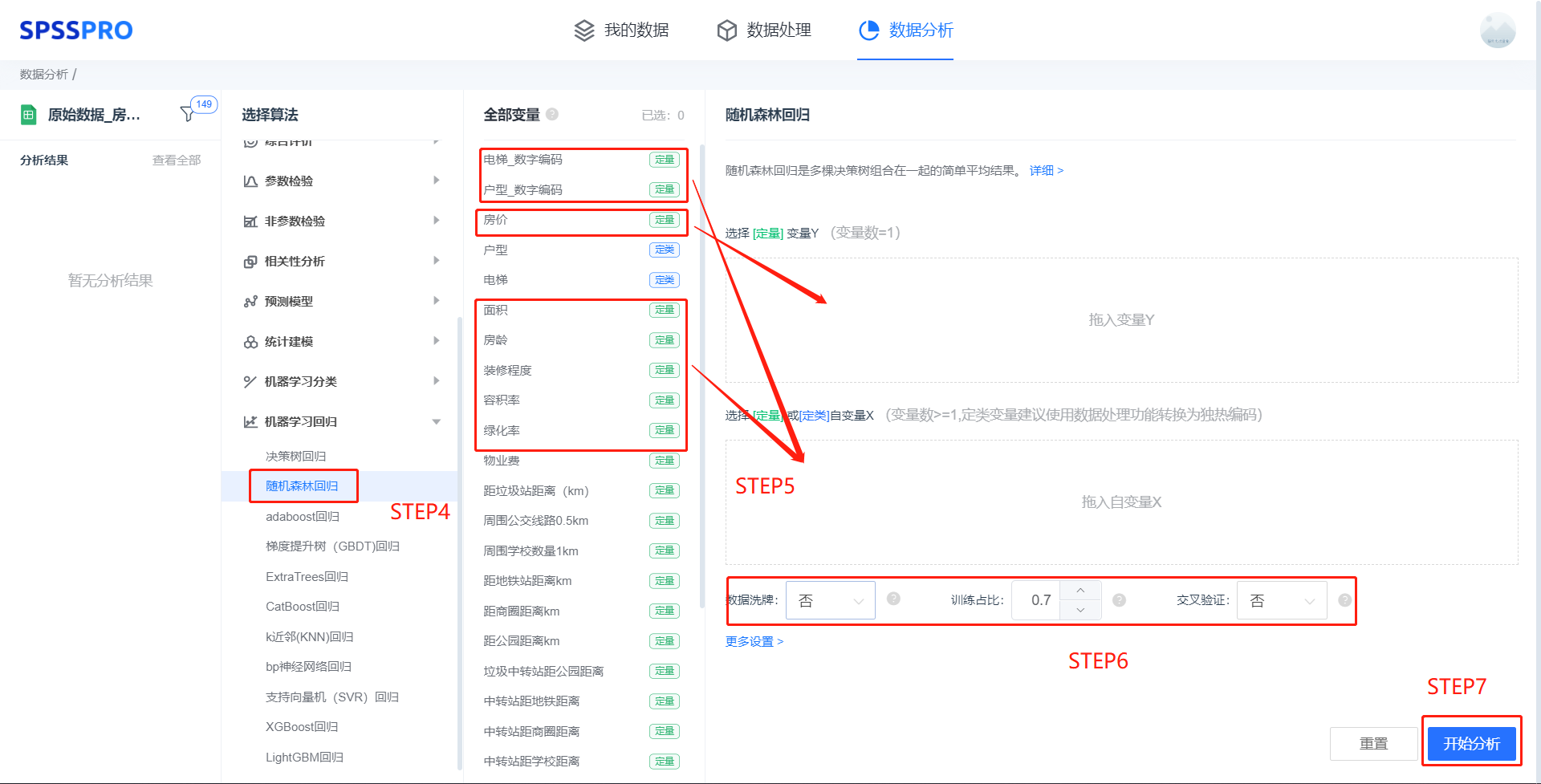
step4:选择【随机森林回归】;
step5:查看对应的数据数据格式,按要求输入【随机森林回归】数据(注:定类变量建议进行编码);
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step7:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:模型参数 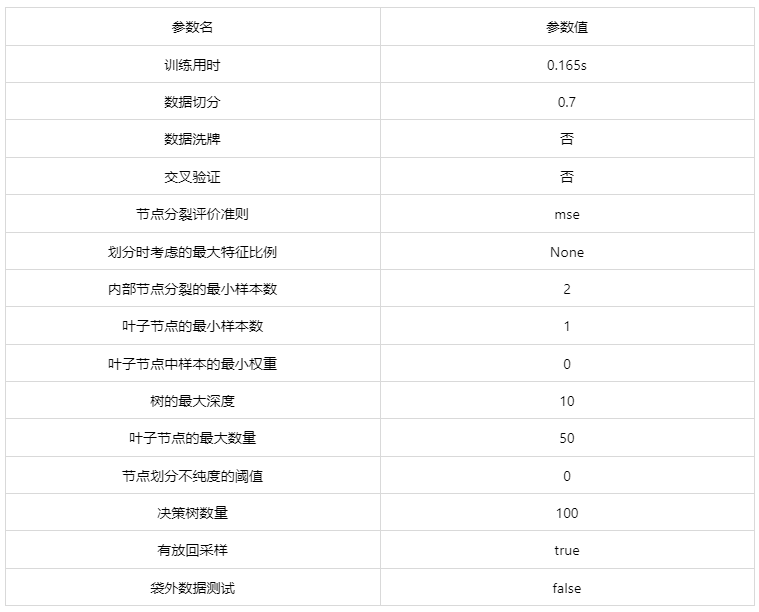
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
输出结果 2:特征重要性
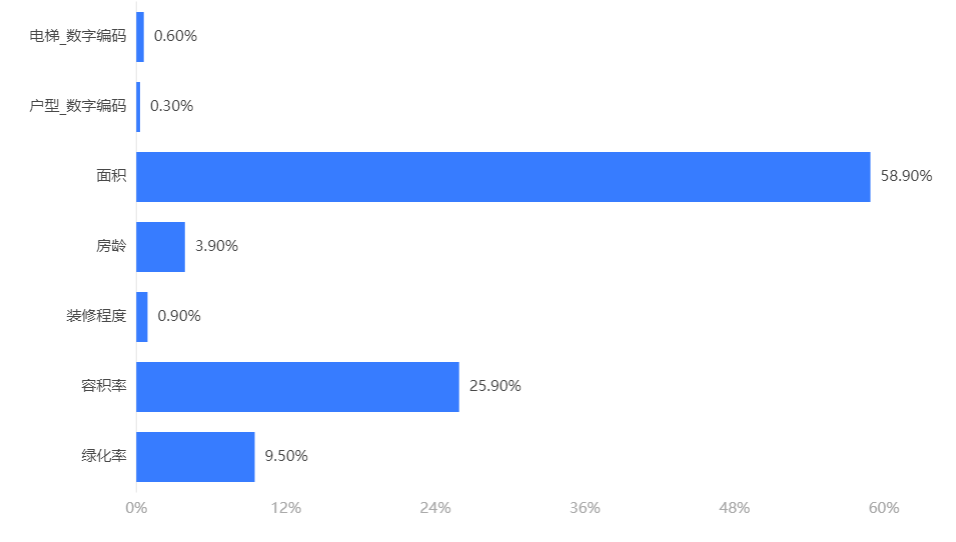
图表说明:上柱形图或表格展示了各特征(自变量)的重要性比例。(附:有时候可以利用特征重要性反推该变量在实际生活中的价值,因为该重要性往往决定结果。)
分析:面积、容积率和绿化率是决定房价的重要因素。
输出结果 3:模型评估结果

图表说明: 上表中展示了交叉验证集、训练集和测试集的预测评价指标,通过量化指标来衡量决策树的预测效果。其中,通过交叉验证集的评价指标可以不断调整超参数,以得到可靠稳定的模型。
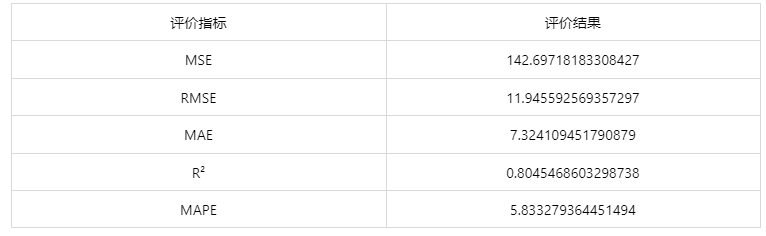
● MSE(均方误差): 预测值与实际值之差平方的期望值。取值越小,模型准确度越高。
● RMSE(均方根误差):为 MSE 的平方根,取值越小,模型准确度越高。
● MAE(平均绝对误差): 绝对误差的平均值,能反映预测值误差的实际情况。取值越小,模型准确度越高。
● MAPE(平均绝对百分比误差): 是 MAE 的变形,它是一个百分比值。取值越小,模型准确度越高。
● R²: 将预测值跟只使用均值的情况下相比,结果越靠近 1 模型准确度越高。
● oob_score:对于回归问题,oob_score 是袋外数据的 R²。若在建立树过程中选择有放回抽样时,大约 1/3 的记录没有被抽取。没有被抽取的自然形成一个对照数据集,可用于模型的验证。所以随机 森林不需要另外预留部分数据做交叉验证,其本身的算法类似交叉验证,而且袋外误差是对预测误差的无偏估计。 (当算法参数选择了“袋外测试数据”后,才会通过 oob_score 来检验模型的泛化能力)
分析:
训练集中 R 方为 0.964,测试集中为 0.264,拟合效果差。模型出现过拟合情况,在训练集中表现优秀,测试集中表现较差。可以考虑:数据是否有问题、参数是否可以优化、是否可以更换其他模型。
输出结果 4:测试数据预测结果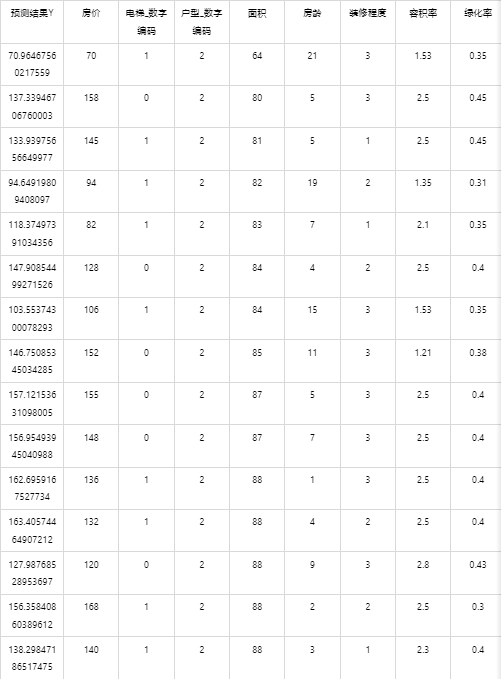
图表说明: 上表展示了随机森林模型对测试数据的预测情况。
输出结果 5:测试预测图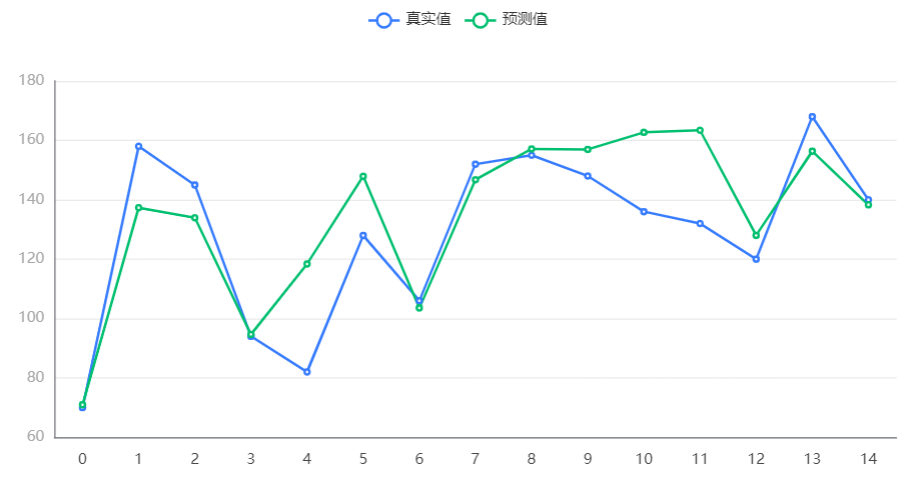
图表说明:上图中展示了随机森林模型对测试数据的预测情况。
输出结果 6:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
● 当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
● 当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况 1:在上面模型评估后,若具有实用性,这时我们可将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
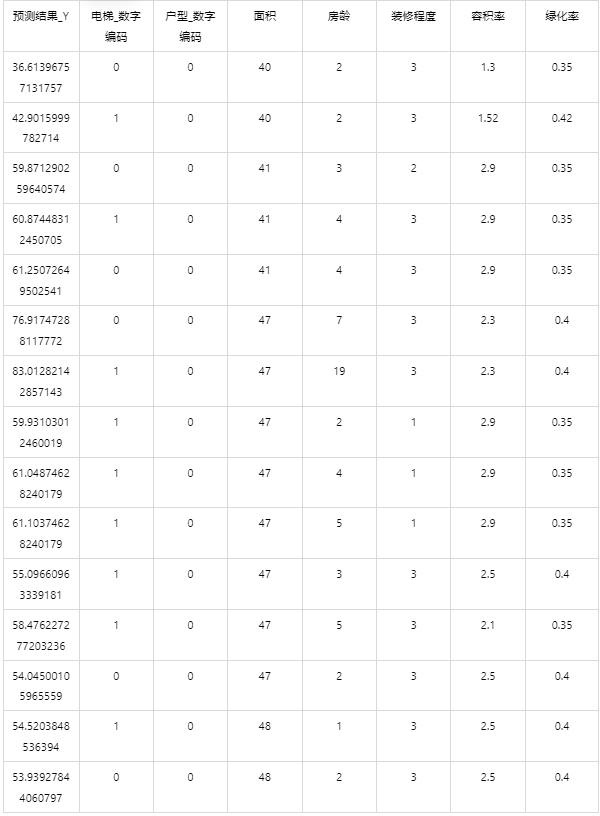
情况 2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到评价效果。
# 7、注意事项
- 由于随机森林具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用 SPSSPRO 客户端进行。
- 随机森林的参数修改需要使用 SPSSPRO 客户端进行。
# 8、模型理论
随机森林是以决策树为基学习器通过集成方式构建 而成的有监督机器学习方法 ,进一步在决策树的训练过程引入了随机性,使其具备优良的抗过拟合 以及抗噪能力. RF 分别从样本选取和特征选择 2 个角度体现其随机性。
1) 随机选取样本:RF 中每一棵决策树的样本 集均是从原始数据集中采用 Bootstrap 策略有放回 地抽取、重组形成与原始数据集等大的子集合. 这就意味着同一个子集里面的样本可以是重复出现 的,不同子集中的样本也可以是重复出现的.
2) 随机选取特征:不同于单个决策树在分割过 程中考虑所有特征后,选择一个最优特征来分割节 点. RF 通过在基学习器中随机考察一定的特征变 量,之后在这些特征中选择最优特征[16] . 特征变量 考察方式的随机性使得 RF 模型的泛化能力和学习 能力优于个体学习器 。
随机森林的算法步骤如下:
A)从原始样本集中抽取训练集。每轮从原始样本集中使用 Bootstraping 的方法抽取 n 个训练样本(有放回的抽样)。共进行 k 轮抽取,得到 k 个训练集。(k 个训练集之间是相互独立的)
B)每次使用一个训练集得到一个模型,k 个训练集共得到 k 个模型。
C)对分类问题:将上步得到的 k 个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。
# 9、手推步骤
| 序号 | 花萼长度 | 花萼宽度 | 花瓣长度 | 花瓣宽度 |
|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 |
| 2 | 4.9 | 3 | 1.4 | 0.2 |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 |
| 4 | 5 | 3.3 | 1.4 | 0.2 |
| 5 | 7 | 3.2 | 4.7 | 1.4 |
| 6 | 6.4 | 3.2 | 4.5 | 1.5 |
| 7 | 6.9 | 3.1 | 4.9 | 1.5 |
| 8 | 5.7 | 2.8 | 4.1 | 1.3 |
| 9 | 6.3 | 3.3 | 6 | 2.5 |
| 10 | 5.8 | 2.7 | 5.1 | 1.9 |
| 11 | 7.1 | 3 | 5.9 | 2.1 |
| 12 | 5.9 | 3 | 5.1 | 1.8 |
现有12组鸢尾花数据,用随机森林回归算法根据花萼长度、花萼宽度和花瓣长度预测花瓣宽度的过程如下:
step1:随机抽取数据
从原始数据集中有放回的随机抽取12次,进行三轮抽取,获得三个训练集。
训练集1:{1,2,3,3,5,7,7,8,9,10,11,12}
训练集2:{2,3,4,4,5,6,7,8,8,9,10,12}
训练集3:{1,2,2,4,5,6,6,8,10,11,12,12}
为简化计算过程,这里设置每棵树的树深=3。
step2:构建第一棵树
计算训练集1的均方误差
均方误差公式
目标值:
均值:
step3:确定最佳分裂点
随机森林需要将所有相邻值间的数都作为可能分裂点进行一一计算,这里为了简化计算,只计算个别分裂点的加权MSE。
特征1:花萼长度
分裂点
左节点:y = [0.2,0.2,0.2,0.2],均值=0.2,
右节点:y = [1.3,1.9,1.8,2.5,1.5,1.5,1.4,2.1],均值=1.75,
加权
分裂点
左节点:y=[0.2,0.2],均值=0.2,
右节点:y=[0.2,0.2,1.3,1.9,1.8,2.5,1.5,1.5,1.4,2.1],均值=1.44,
加权
特征2:花萼宽度
分裂点
左节点:y=[1.9,1.3],均值=1.6,
右节点:y=[0.2,2.1,1.8,1.5,0.2,1.4,1.5,0.2,2.5,0.2],均值=1.16,
加权
分裂点
左节点:y=[1.9,1.3,0.2,2.1,1.8],均值=1.46,
右节点:y=[1.5,0.2,1.4,1.5,0.2,2.5,0.2],均值=1.07,
加权
特征3:花瓣长度
分裂点
左节点:y = [0.2,0.2,0.2,0.2],均值=0.2,
右节点:y = [1.3,1.9,1.8,2.5,1.5,1.5,1.4,2.1],均值=1.75,
加权
分裂点
左节点:y=[0.2,0.2,0.2,0.2,1.3],均值=0.42,
右节点:y=[1.5,1.4,1.5,1.9,1.8,2.1,2.5],均值=1.81,
加权
选择加权MSE最小的特征值作为分裂点,这里选择
step4:第一次分裂
左子节点:花瓣长度
右子节点:花瓣长度
step5:右子节点继续分裂
重复step2的步骤,右子节点包含y = [1.3,1.9,1.8,2.5,1.5,1.5,1.4,2.1]。为了简化计算,这里同样不对每一个可能分裂点进行一一计算。
分裂点
左节点:y=[1.3,1.9,1.8],均值=1.667,
右节点:y = [2.5,1.5,1.5,1.4,2.1],均值=1.8,
加权
分裂点
左节点:y=[1.3,1.9,1.8,2.1],均值=1.775,
右节点:y = [2.5,1.5,1.5,1.4],均值=1.725,
加权
分裂点
左节点:y = [1.3,1.5,1.5,1.4],均值=1.425,
右节点:y = [1.9,1.8,2.5,2.1],均值=2.075,
加权
选择加权MSE最小的特征值作为分裂点,这里选择
右左子结点:花瓣长度
右右子节点:花瓣长度
当前树深为3,分裂结束,第一棵树Tree1构建完成。
step6:构建完整的森林
根据训练集2和训练集3的数据重复step2-step5,得到Tree2和Tree3,组成森林。
step7:通过森林进行预测
新样本:花萼长度=4.3,花萼宽度=3.1,花瓣长度=4.7
让森林里每棵树都进行预测:
Tree1:预测值=1.425
Tree2:预测值=1.785(假设)
Tree3:预测值=1.620(假设)
最终预测结果:(1.425+1.785+1.620)/3=1.610,即随机森林回归预测新样本的花瓣宽度为1.610。
# 10、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] 周志华. 机器学习[M]. 第一版. 北京:清华大学出版社, 2016 年 1 月.