ExtraTrees回归
# 1、作用
Extra-Trees (极其随机的森林)和随机森林非常类似,这里的“及其随机”表现在决策树的结点划分上,它干脆直接使用随机的特征和随机的阈值划分,这样我们每一棵决策树形状、差异就会更大、更随机。
# 2、输入输出描述
输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定量变量。
输出: 模型输出的结果值及模型预测效果。
# 3、案例示例
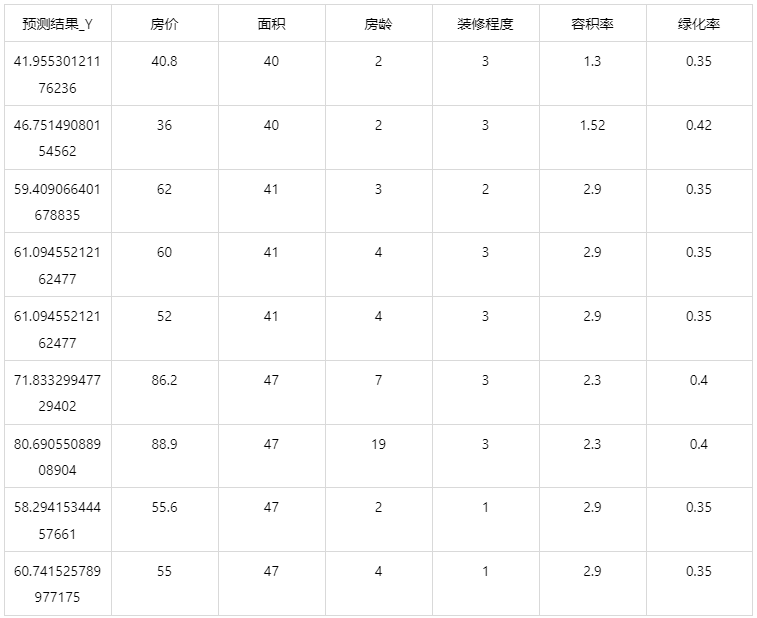
根据房子的户型、电梯、面积、房龄、装修程度、容积率和绿化率,使用 Extra Trees 方法预估该房子的房价。
# 4、案例数据

Extra Trees 回归案例数据
# 5、案例操作
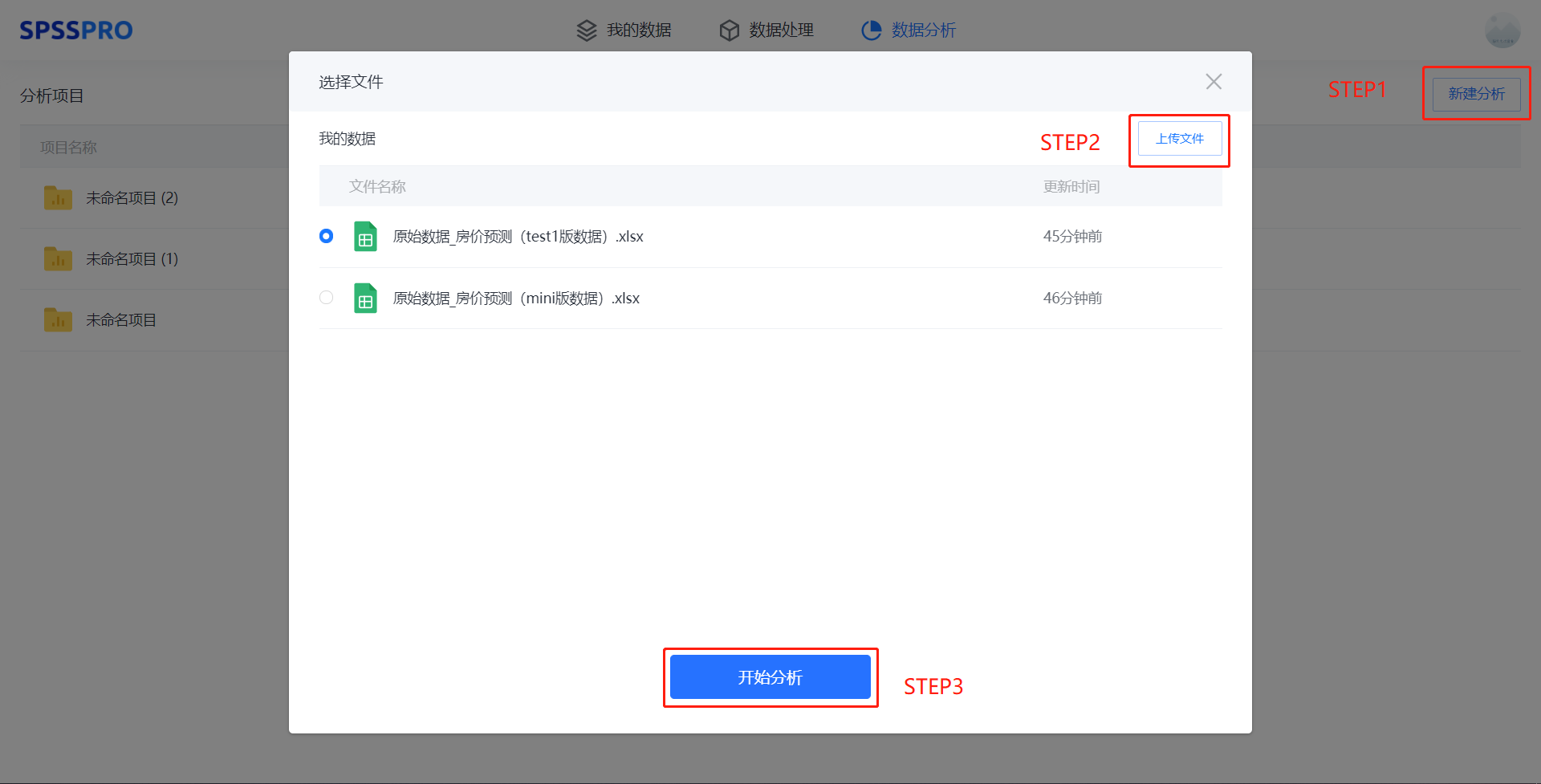
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;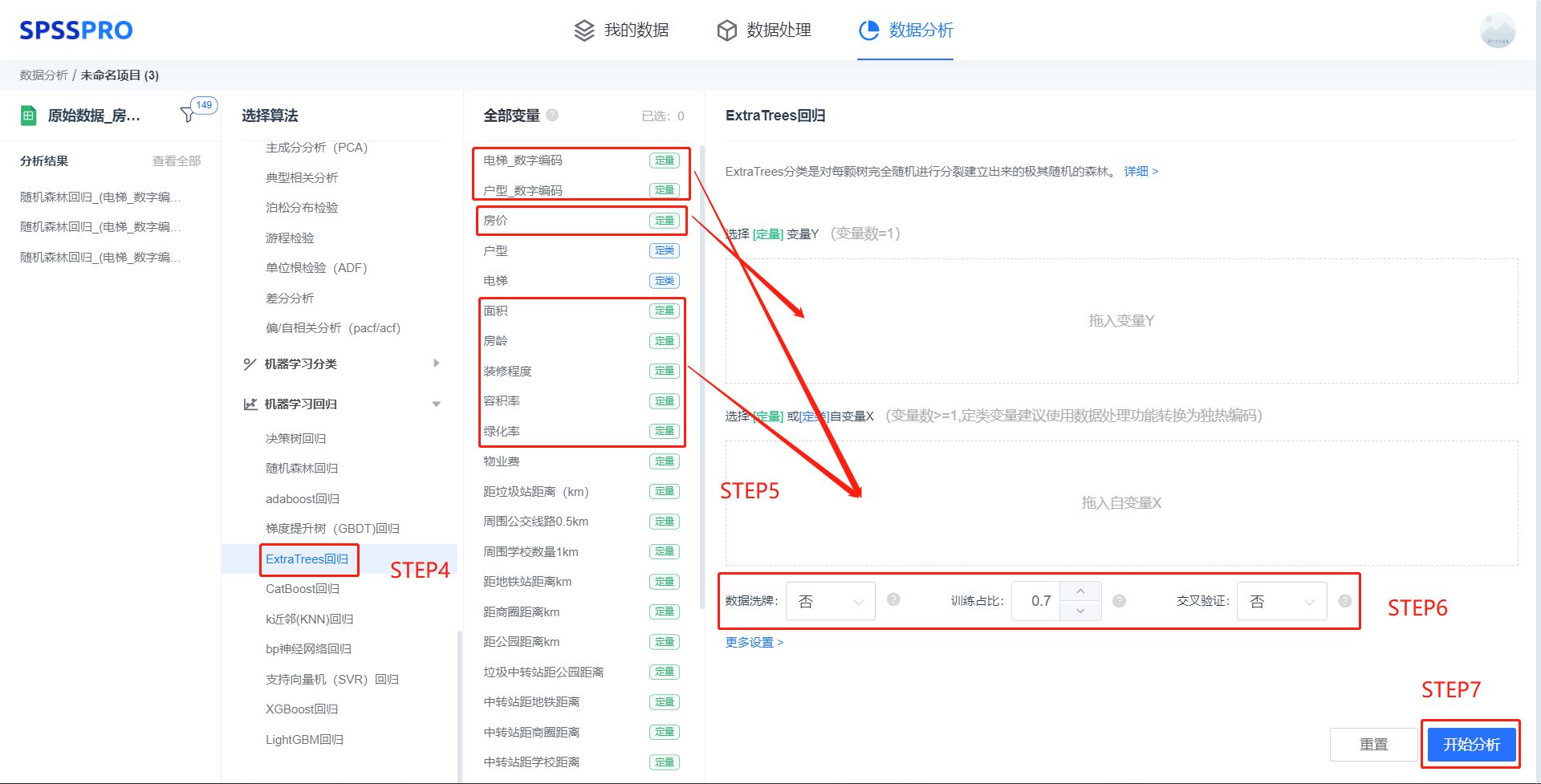
step4:选择【Extra Trees 回归】;
step5:查看对应的数据数据格式,按要求输入【Extra Trees 回归】数据(注:定类变量建议进行编码);
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step7:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:模型参数 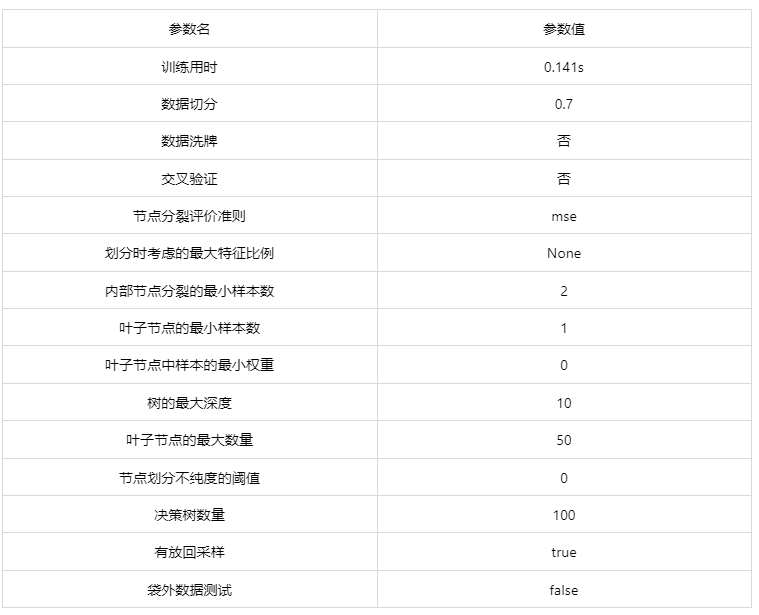
图表说明: 上表展示了训练该模型的时候,输入的参数以及训练所耗的时间。
输出结果 2:特征重要性
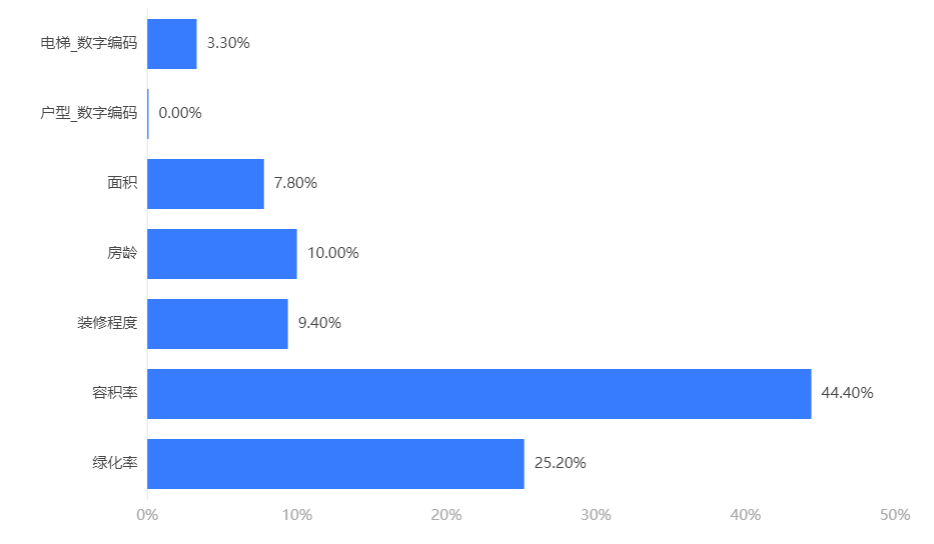
图表说明:上柱形图或表格展示了各特征(自变量)的重要性比例。(附:有时候可以利用特征重要性反推该变量在实际生活中的价值,因为该重要性往往决定结果。)
分析:在 Extra Trees 回归模型中容积率、绿化率和房龄是决定房价的重要因素。
输出结果 3:模型评估结果

图表说明: 上表中展示了交叉验证集、训练集和测试集的预测评价指标,通过量化指标来衡量决策树的预测效果。其中,通过交叉验证集的评价指标可以不断调整超参数,以得到可靠稳定的模型。
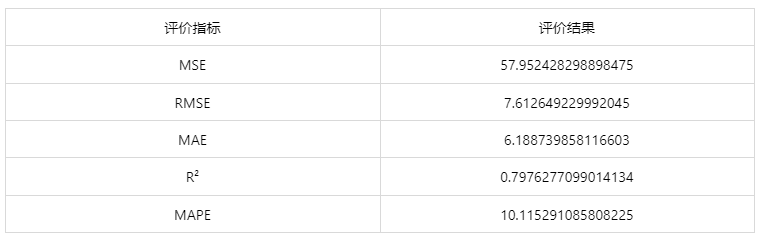
● MSE(均方误差): 预测值与实际值之差平方的期望值。取值越小,模型准确度越高。
● RMSE(均方根误差):为 MSE 的平方根,取值越小,模型准确度越高。
● MAE(平均绝对误差): 绝对误差的平均值,能反映预测值误差的实际情况。取值越小,模型准确度越高。
● MAPE(平均绝对百分比误差): 是 MAE 的变形,它是一个百分比值。取值越小,模型准确度越高。
● R²: 将预测值跟只使用均值的情况下相比,结果越靠近 1 模型准确度越高。
● oob_score:对于回归问题,oob_score 是袋外数据的 R²。若在建立树过程中选择有放回抽样时,大约 1/3 的记录没有被抽取。没有被抽取的自然形成一个对照数据集,可用于模型的验证。所以随机 森林不需要另外预留部分数据做交叉验证,其本身的算法类似交叉验证,而且袋外误差是对预测误差的无偏估计。 (当算法参数选择了“袋外测试数据”后,才会通过 oob_score 来检验模型的泛化能力)
分析:
训练集中 R 方为 0.941,测试集中为 0.892,拟合效果比较优秀。
输出结果 4:测试数据预测结果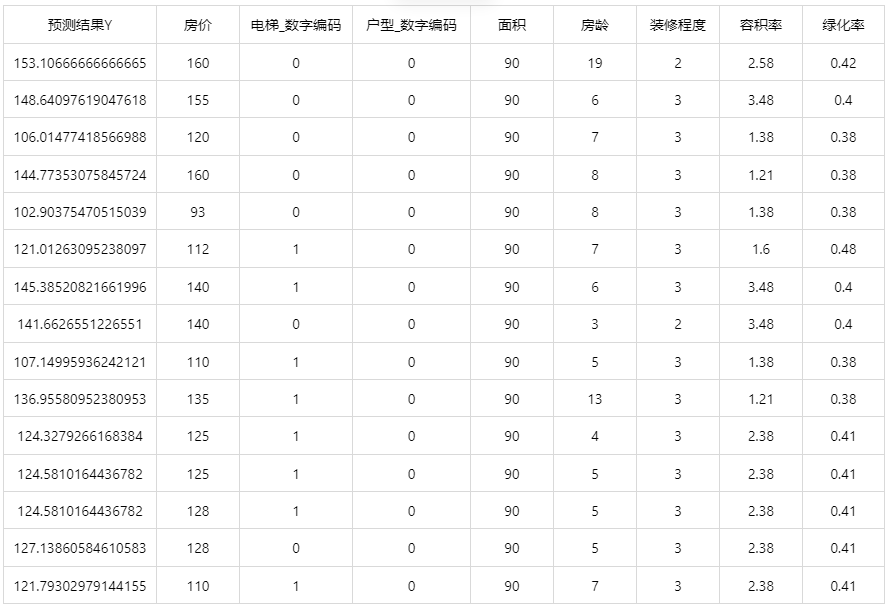
图表说明: 上表展示了 Extra Trees 模型对测试数据的预测情况。
输出结果 5:测试预测图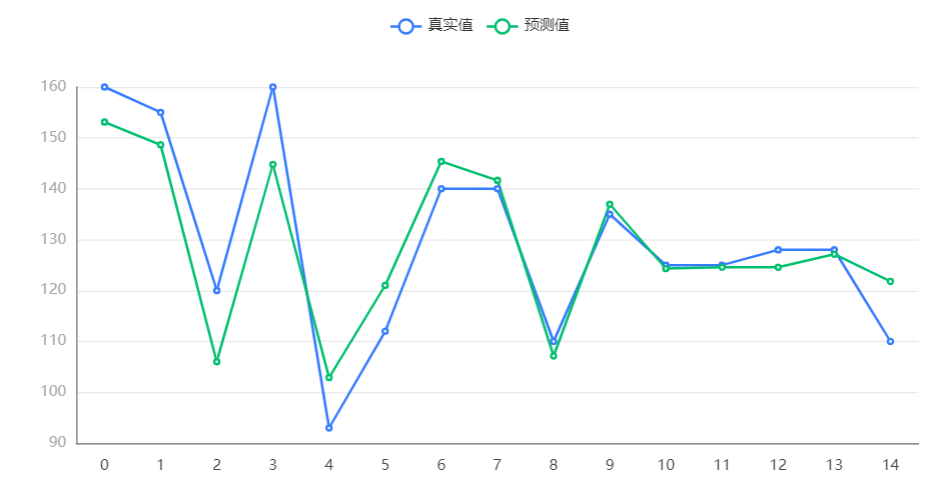
图表说明:上图中展示了随机森林模型对测试数据的预测情况。
输出结果 6:模型预测与应用(此功能只在客户端支持使用)
注:当无法进行预测功能时,可检查数据集中是否存在定类变量或者缺失值:
● 当存在定类变量时,请在用于训练模型的数据集和用于预测的数据集中将变量编码,再进行操作。
(SPSSPRO:数据处理->数据编码->将定类变量编码为定量)
● 当用于预测数据的数据集中存在缺失值时,请删去缺失值再进行操作。
情况 1:在上面模型评估后,若具有实用性,这时我们可将该模型进行应用。点击【模型预测】上传文件可以直接得到预测结果。
情况 2:若是上传的数据包括因变量真实值,不仅仅可以得到预测结果,还可以得到评价效果。
# 7、注意事项
- 由于 Extra Trees 具有随机性,每次运算的结果不一样。若需要保存本次训练模型,需要使用 SPSSPRO 客户端进行。
- Extra Trees 的参数修改需要使用 SPSSPRO 客户端进行。
# 8、模型理论
极其随机的森林(Extra-Trees)算法是由传统的决策树(DecisionTrees)算法衍生而来。传统的决策树算法根据数据对象在不同特征上的值将其分配到不同的集合(Branches)中,应用该算法的关键在于选择最优的用于决策的数据特征及其拆分点。而 Pierre 等创造性地通过在传统决策树算法中加入如下步骤,在增加决策树的随机性的同时,还提高了对次优解的准确性和求解计算的灵活性,这种改良的效果在处理分类问题时尤为突出:
停止条件:
随机拆分:
最终拆分步骤:
其中,对于回归问题![]() =
=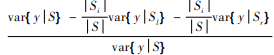 , var{yS}为样本 S 中输出的 y 的方差,r 和 l 分别表示结点在右边和左边的分叉。
, var{yS}为样本 S 中输出的 y 的方差,r 和 l 分别表示结点在右边和左边的分叉。
# 9、手推步骤
| 序号 | 花萼长度 | 花萼宽度 | 花瓣长度 | 花瓣宽度 |
|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 |
| 2 | 4.9 | 3 | 1.4 | 0.2 |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 |
| 4 | 5 | 3.3 | 1.4 | 0.2 |
| 5 | 7 | 3.2 | 4.7 | 1.4 |
| 6 | 6.4 | 3.2 | 4.5 | 1.5 |
| 7 | 6.9 | 3.1 | 4.9 | 1.5 |
| 8 | 5.7 | 2.8 | 4.1 | 1.3 |
| 9 | 6.3 | 3.3 | 6 | 2.5 |
| 10 | 5.8 | 2.7 | 5.1 | 1.9 |
| 11 | 7.1 | 3 | 5.9 | 2.1 |
| 12 | 5.9 | 3 | 5.1 | 1.8 |
现有12组鸢尾花数据,用ExtraTrees回归算法根据花萼长度、花萼宽度和花瓣长度预测花瓣宽度的过程如下:
step1:设置参数
树的数量=3
每个节点随机选择的特征数=2
树深=2
step2:构建第一棵树的根节点
根据分裂子集的均方误差MSE选择分裂点,选择MSE更小的分裂点作为最佳分裂点。
随机选择两个特征,这里选择花瓣长度
特征1:随机取
左节点:y = [0.2,0.2,0.2,0.2],均值=0.2,
右节点:y = [1.3,1.9,1.8,2.5,1.5,1.5,1.4,2.1],均值=1.75,
加权
特征2:随机取
左节点:y=[1.9,1.3,0.2,2.1,1.8],均值=1.46,
右节点:y=[1.5,0.2,1.4,1.5,0.2,2.5,0.2],均值=1.07,
加权
step3:第一次分裂
左子节点:花瓣长度
右子节点:花瓣长度
step4:右子节点继续分裂
随机选择两个特征,这里选择花萼长度
特征1:随机取
左节点:y=[1.3,1.9,1.8],均值=1.667,
右节点:y = [2.5,1.5,1.5,1.4,2.1],均值=1.8,
加权
特征2:随机取
左节点:y=[1.3,1.9,1.8,2.1],均值=1.775,
右节点:y = [2.5,1.5,1.5,1.4],均值=1.725,
加权
当前树深为2,分裂结束。
右左子节点:花萼长度
右右子节点:花萼长度
step5:构建第2、3棵树
重复step2-step4,构建第二棵树和第三棵树。
step6:预测
新样本:花萼长度=5.8,花萼宽度=3,花瓣长度=4.5
使用ExtraTrees回归预测新样本花瓣宽度:
第一棵树:
第二棵树:预测值=1.43(假设)
第三棵树:预测值=1.82(假设)
所以ExtraTrees回归预测新样本的花瓣宽度=1.639。
# 10、参考文献
[1]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]PIERRE G,DAMIEN E,LOUIS W. Extremely randomized trees[J].Machine Learning,2006,63(1):3-42.
[3]彭敦诚,王开团,孙学利,安江峰,吴军,张三平.基于 Extra-Trees 算法的大气环境因素对聚酯涂层老化失光影响的研究[J].材料保护,2020,53(04):84-88+92.DOI:10.16577/j.cnki.42-1215/tb.2020.04.014.