样本均衡
# 样本均衡
# 1、作用
进行分类任务时,如果因变量不同类别的样本数量不均衡时,会严重影响模型训练。比如说对于一个二分类问题,某一类别有995个数据,另一类别有5个数据时,此时属于严重的数据样本分布不均衡,模型很难从中提取规律,所以当发现样本不均衡时,需要做样本均衡处理,通过以下三种方法使得因变量不同类别的样本数量相差不大:1. 过采样(oversampling)即增加样本量较少的类别样本;2.欠采样(undersampling)即减少样本量较多的类别样本;3.混合采样(mixed sampling),即结合过采样和欠采样的方法调整两类别的样本数量。
# 2、输入输出描述
输入:至少两项定量变量。
输出:增加样本量较少的类别样本或减少样本量较多的类别样本。
# 3、案例示例
案例:假设某数据集的因变量存在样本不均衡情况,通过数据处理-样本均衡,从而使得数据变得均衡。
# 4、案例数据

样本均衡案例数据
# 5、案例操作
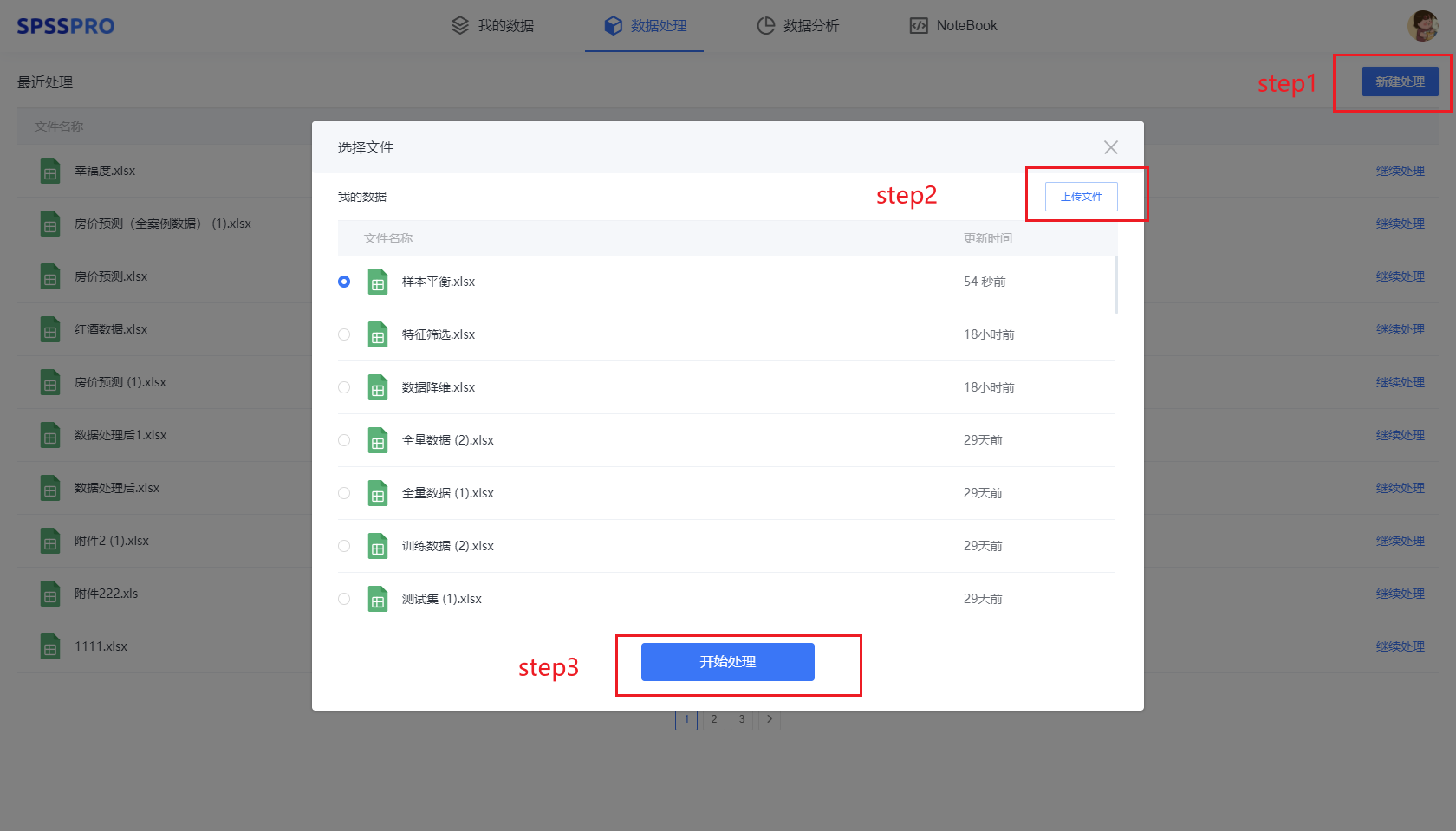
Step1:在“数据处理”模块新建处理;
Step2:上传文件;
Step3:选择对应数据打开后进行预览,确认无误后点击开始处理;
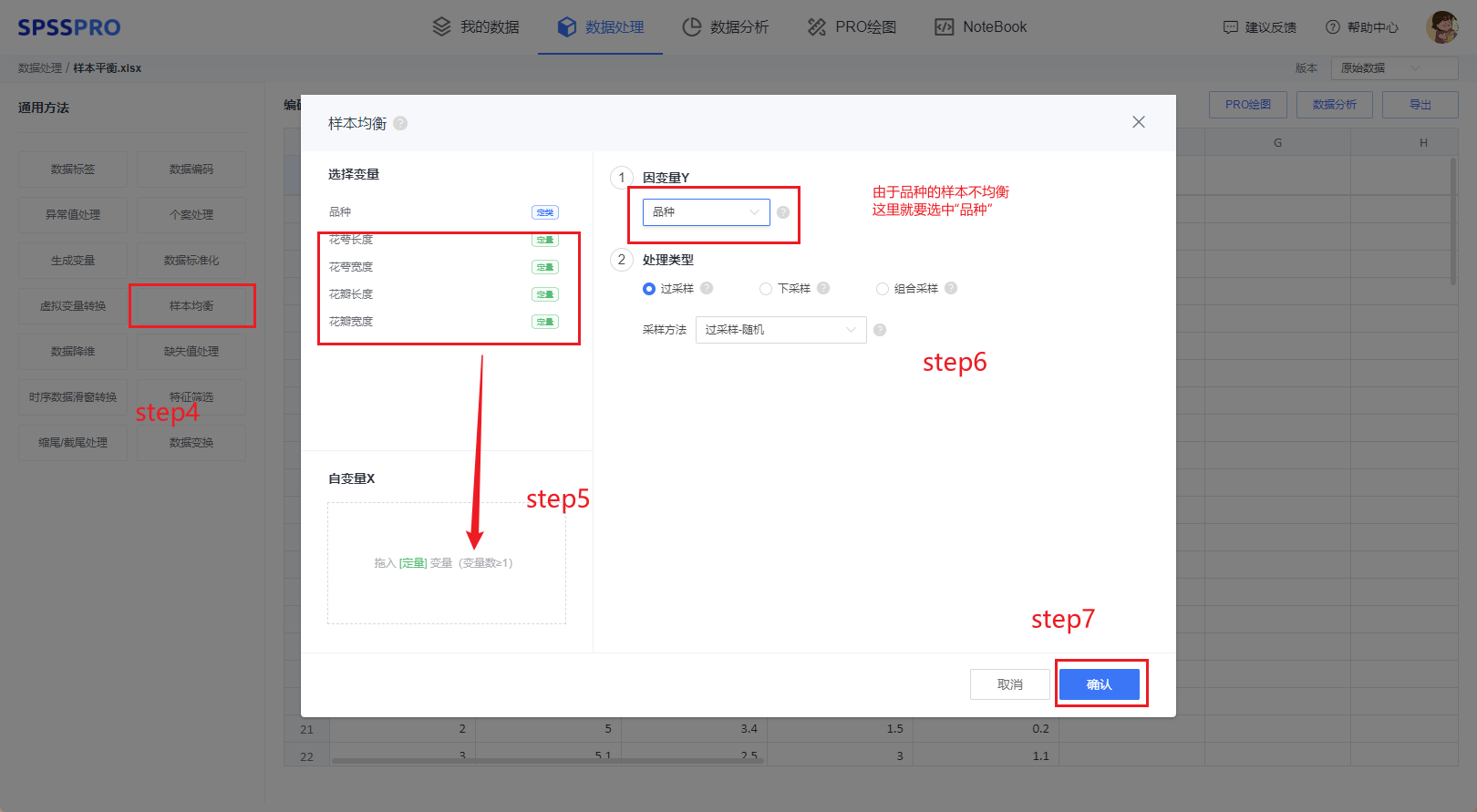
Step4:选择【样本均衡】;
Step5:查看对应的数据数据格式,【样本均衡】要求变量为定量变量,且至少有一项;
Step6:确认参数,存在过采样、欠采样、组合采样这三种方式。
Step7:点击【开始处理】,完成全部操作。
# 6、输出结果分析
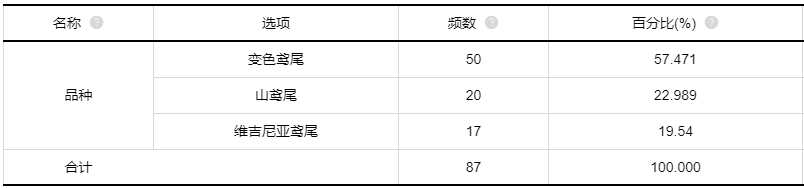
原始数据进行统计,可以看出,各个分类水平的样本量都是大不相同,样本不平衡,变色鸢尾的样本最多,维吉尼亚鸢尾的样本最少。
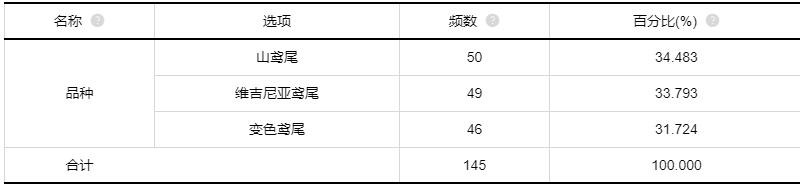
(1)选用“过采样”进行样本均衡处理后,各分类的样本结果如下:可以看出,各个分类水平的样本量都是33.333%,样本非常平衡。

(2)采用“欠采样”进行样本均衡处理后,各分类的样本结果如下:可以看出,各个分类水平的样本量都是33.333%,样本非常平衡。

(3)采用“组合采样”进行样本均衡处理后,各分类的样本结果如下:可以看出,变色鸢尾的样本有所减少、山鸢尾和维吉尼亚鸢尾的样本有所增加。
# 7、注意事项
- 样本均衡不支持对存在空值的变量进行处理,需要提前处理空值。
- 样本均衡仅支持在客户端进行下载使用。
# 8、模型理论
(1)过采样(oversampling)
当数据不平衡的时,比如对于一个只用0和1的二分类问题,样本标签1有995个数据,样本标签0有5个数据时,为了保持样本数目的平衡,可以选择增加或通过算法生成标签0的数据量,这个过程就叫做上采样,也叫过采样。
过采样一般有两种方法:
随机过采样(Random oversampling):从数据量少的类别中随机选择样本进行复制,直到两类别的样本数量相近。
SMOTE(Synthetic Minority Over-sampling Technique):生成少数类别的合成样本,通过插值在少数类别样本之间生成新的样本。
自适应合成抽样(adaptive synthetic sampling,ADASYN)是一种基于样本分布密度自适应生成合成样本的过采样方法。
ADASYN相对于简单的复制少数类样本或使用固定比例的合成样本(如SMOTE)的优势在于,它能够更加自适应地调整合成样本的数量,更好地保持生成样本的多样性和代表性。这使得ADASYN在处理高度不平衡的数据集时,通常能够提供更好的性能和效果。
其核心思想是根据样本的分布密度来生成合成样本。具体来说,ADASYN在生成合成样本时,对每个少数类样本计算其最近邻样本的数量,并根据这个数量来调整生成的合成样本。这意味着对于那些与多数类样本相距较远的少数类样本,ADASYN会生成更多的合成样本,而对于那些与多数类样本相距较近的少数类样本,生成较少的合成样本。
(2)欠采样(undersampling)
当数据不平衡的时,比如对于一个只用0和1的二分类问题,样本标签1有995个数据,样本标签0有5个数据时,为了保持样本数目的平衡,可以选择减少或通过算法减少标签1的数据量,这个过程就叫做下采样,也叫欠采样。
随机欠采样(Random undersampling): 从多数类别中随机选择样本进行删除,直到两类别的样本数量相近。
集中删除(Cluster Centroids):通过聚类的方法减少数据量多的类别的样本数量。
(3)组合采样(mixed sampling)
结合上采样和下采样的方法,为了保持样本数目的平衡,可以选择通过算法减少或生成不均衡标签的数据量。
- SMOTE ENN(Edited Nearest Neighbors)是一种结合了SMOTE过采样和ENN欠采样的组合方法。其工作流程是:
首先,使用 SMOTE 方法生成合成样本来增加少数类样本的数量。SMOTE (Synthetic Minority Over-sampling Technique) 通过在少数类样本之间进行插值,生成新的合成样本,以平衡类别之间的数据分布。
然后,应用 Edited Nearest Neighbors (ENN) 方法来移除多数类样本中的噪声点。ENN 会检查每个样本的最近邻居,如果某个样本的多数类邻居比少数类邻居多,那么它就会被认为是噪声点,并被移除。
SMOTE ENN 旨在综合利用过采样和欠采样的优势,既增加了少数类样本的数量,又减少了多数类样本的噪声,从而改善了数据集的平衡性。
- Tomek Link。对于两个样本
和 和 ,如果它们是彼此的最近邻,并且它们属于不同的类别,那么这对样本 就被称为 Tomek Link。它会将占比多的一方 ,与离 最近的一个少的另一方 进行配对,然后将这个配对删除,构造出一条明显的分界线,从而起到去噪和边界清晰化的效果,帮助分类器更准确地划分类别。
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.