数据降维
# 数据降维
# 1、作用
数据降维是通过某种映射方法,将原始高维空间中的数据点映射到低维空间,从而将多维数据合并为更少维度的数据集,并且这些低维数据能够保留原始数据的大部分有效信息。在数据分析中,有些变量可能是冗余或无意义的。当这些无意义变量参与分析时,可能会对结果产生不利影响,因此可以采用降维技术去除噪声和冗余信息。此外,降维还可以用于保护敏感隐私数据,或对数据进行变换和整合。有效的降维方法能够保持数据的重要结构和模式,确保降维后的数据仍能反映原始数据的关系和趋势。另外,在处理高维稀疏数据时,降维可以减少模型训练时间并提高预测准确率。
# 2、输入输出描述
输入:至少两个定量变量(假设变量数为N)。
输出:新生成降维后的M个变量序列(M<N)。
# 3、案例示例
案例:在数据分析前,理论研究收集到10个变量(X1-X10)的信息,现需要将这10个变量进行降维,并且降维后的变量能够保留原本数据中绝大部分有效信息。
# 4、案例数据

数据降维案例数据
# 5、案例操作
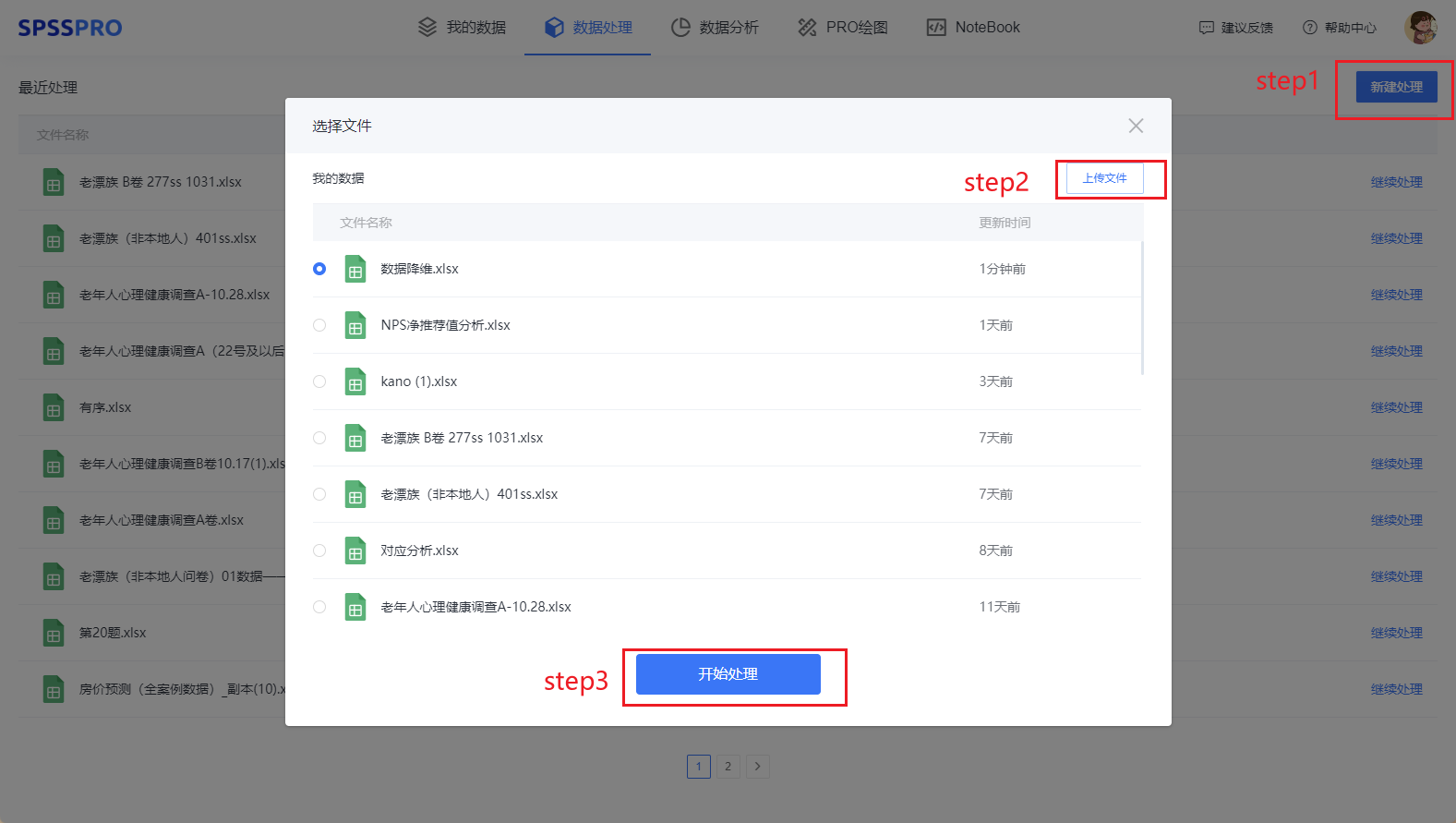
Step1:在“数据处理”模块新建处理;
Step2:上传文件;
Step3:选择对应数据打开后进行预览,确认无误后点击开始处理;
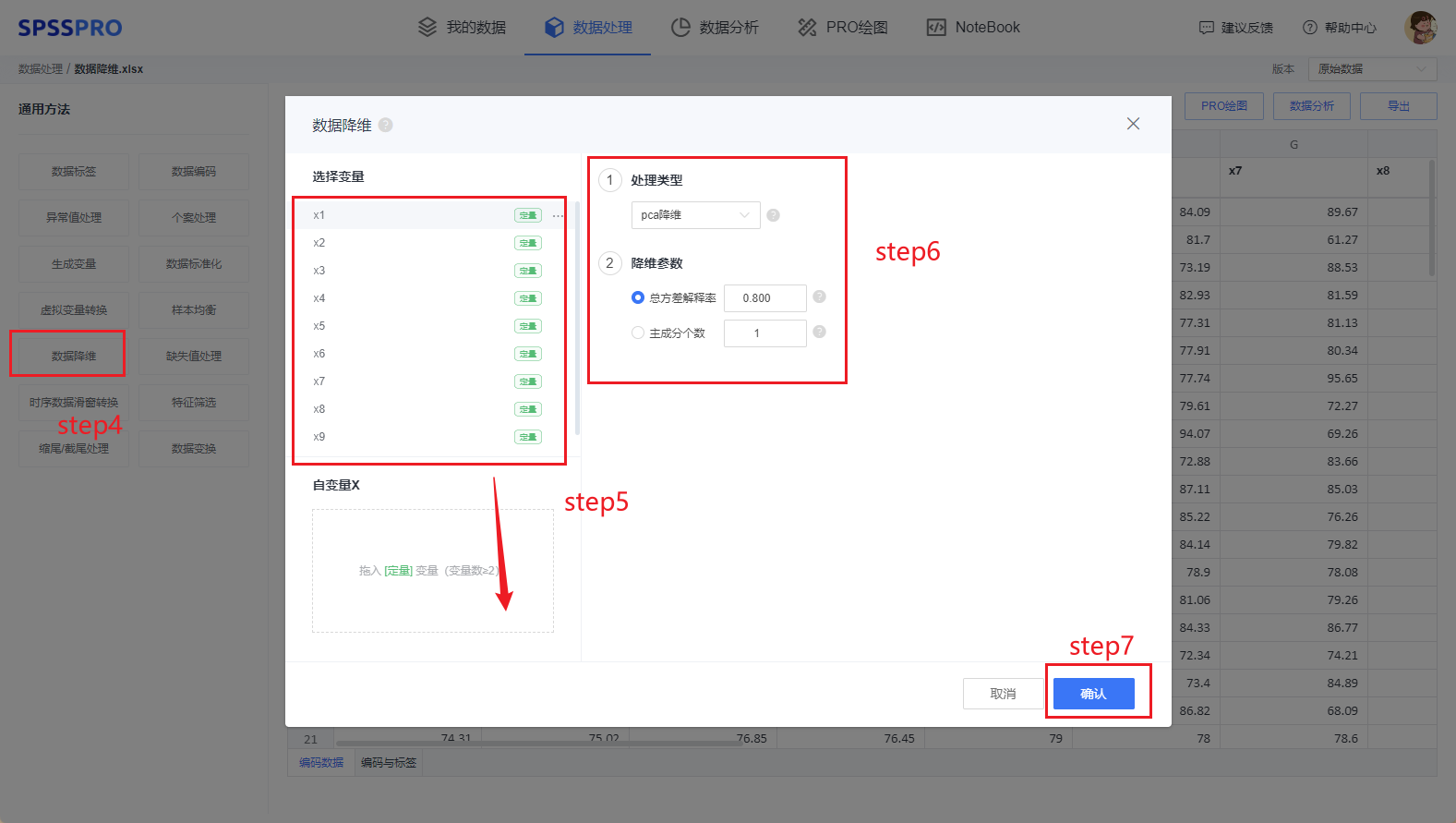
Step4:选择【数据降维】;
Step5:查看对应的数据数据格式,【数据降维】要求变量为定量变量,且至少有两项;
Step6:确认参数,有多种数据降维方法可选择;
Step7:点击【开始处理】,完成全部操作。
# 6、输出结果分析
主成分分析的参数
(1)总方差解释率:方差解释率表示提取的主成分/因子对原有变量的解释能力,方差解释率越大,解释能力越强,越能体现原始变量的关键影响因素,提取的主成分或因子越有效,通常达到80%的程度表现就较为优秀了。比如说现有5个主成分,它们的方差解释率为50%、20%、18%、12%、10%,若总方差解释率设置了80%,前三个主成分的总方差解释率达到了50+20+18=88%,最终降维处理后就是三个变量。
(2)主成分个数:直接确定需要降维为N个主成分,该方法N不得高于原有特征个数。比如说现在有5个变量,主成分设置为3,那么最终降维处理后就是三个变量

数据降维会将原始的10个变量数据整合成4个变量数据,由10个变量到4个变量的过程,我们达到了降维的目的,但是降维过程中或多或少都会损失一些信息,我们选择了主成分分析法,并且总方差解释率定为了0.8,说明降维后的4个变量至少能解释原始数据的80%的信息,即较少地损失了信息又达到降维的目的。
# 7、注意事项
- 数据降维不支持对存在空值的变量进行处理,需要提前处理空值。
# 8、模型理论
# PCA降维
主成分分析(Principal Component Analysis,PCA)降维是一种常用的无监督学习方法,旨在通过将多个变量转换为少数几个不相关的综合变量来全面反映整个数据集。原始数据集中的变量通常存在一定的相关性,PCA利用较少的主成分来综合这些信息。主成分是由数据集中的变量线性组合而成,彼此之间互不相关,这意味着它们各自代表着独立的信息。
在数学上,PCA的核心思想是通过最大化方差来确保样本点在新的特征空间中的投影尽可能分散,以达到最大可分性的目的。同时,最小化协方差有助于减少维度之间的相关性,因为相关性意味着维度间可能存在重复的信息而非完全独立。
具体步骤为:
1. 数据去中心化:所有数据点减去样本的均值,使数据均值为0。数据去中心化的主要目的是消除数据中的均值偏移,同时保持数据的相对分布特征,使得在进行主成分分析时,各个特征的方差能够更准确地反映它们在原始数据中的变化程度,而不会受到绝对值的影响。
假设我们有一个包含
其中
2. 计算协方差矩阵: 协方差矩阵描述了数据各个特征之间的线性关系强度和方向。它可以同时解决两个优化目标:最大化方差和最小化协方差。
- 首先对数据集
进行标准化,使得每个特征的均值为0,标准差为1。 - 构造协方差矩阵:协方差矩阵
是一个对称矩阵,其对角线上的元素是各个特征的方差,非对角线上的元素是各个特征之间的协方差。
在这种形式下,
3. 特征值分解: 我们的目标就是找到另一组基,使得同样的这些样本在那组基上可以达到方差最大,协方差最小。这就需要对当前协方差矩阵进行对角化了。由于协方差矩阵是对称矩阵,必然可以找到矩阵
可以看到,其中的
4.选择主成分: 所以此时,我们的优化目标就变成:寻找一个矩阵
# 线性判别法(LDA)
线性判别分析(Linear Discriminant Analysis, LDA)是一种经典的监督学习算法,其每个样本都有一个类别标签作为输出。这与PCA不同,PCA是一种无监督降维技术,不考虑样本的类别信息,仅关注数据的方差。相比之下,LDA更注重数据的类别信息和分离性能。LDA的核心思想是在低维空间中投影数据,使得投影后每个类别的样本尽可能接近(最小化类内散度),同时不同类别之间的类别中心之间的距离尽可能大(最大化类间散度)。
- 计算类内散度矩阵(Within-class scatter matrix):假设我们有
个类别,每个类别 中有 个样本。类内散度矩阵 衡量了同一类别内部样本之间的散布程度,其可以通过每个类别的样本均值向量 计算得到:
每个类别的散度矩阵是:
即类内散度矩阵为:
- 计算类间散度矩阵(Between-class scatter matrix): 衡量的是不同类别之间的差异程度,即不同类别的均值之间的差异。使用全局均值向量
和每个类别的均值向量 来计算:
- 根据特征向量构造目标函数 :
因为我们希望最小化类内散度和最大化类间散度,因此目标函数越大越好。相当于在约束条件为
对上述式子求导,令其等于0:
相当于解决广义特征值问题:
通常来说,我们只需要计算前
# ISOMap
等度量映射(Isometric Feature Mapping,Isomap)是流形学习的一种,通过等距映射的非线性降维,即尽可能地保持数据点之间的测地距离(geodesic distances),是一种无监督算法。这种方法通常用于当数据具有复杂的非线性结构时。Isomap最主要的优点就是使用“测地距离”,而不是使用原始的欧几里得距离,这样可以更好得控制数据信息的流失,能够在低维空间中更加全面地将高维空间的数据表现出来 具体步骤为:
计算距离矩阵(Distance Matrix): 给定高维数据集,首先计算数据点之间的距离或相似度。通常使用欧氏距离或者其他合适的距离度量来计算每对数据点之间的距离。
距离矩阵构建: 根据计算得到的距离(或相似度)数据,构建一个距离矩阵
。 计算测地距离矩阵(Geodesic Distance Matrix): 使用图论中的最短路径算法(如 Dijkstra算法)来计算每对数据点之间的最短路径,这些路径被认为是在流形上的测地线。
多维标度法(Multidimensional Scaling,MDS): 对测地距离矩阵进行特征值分解,可以得到低维空间中的坐标表示,这些坐标表示了每个数据点在低维空间中的位置。
降维: 最后,得到了每个数据点在低维空间中的坐标,这些坐标可以用来可视化数据或者作为后续机器学习模型的输入。
# LLE
局部线性嵌入算法(Locally Linear Embedding,LLE)和Isomap都属于流形学习方法。与Isomap不同的是,LLE在降维中,试图保持邻域内样本之间的线性关系,使得样本之间的映射坐标能够在低维空间中得以保持,尤其适用于数据分布在一个或多个局部线性结构(local linear structures)上的情况。
领域选择: 给定高维数据集,首先选择每个数据点的邻域
。可以用knn算法来确定。 局部重建权重: 对于每个数据点
,找到其领域内的最近邻点集合后,计算重建系数(reconstruction weights) ,用来线性重建 。 重建误差最小化: 对于每个数据点
通过优化一个损失函数来得到最优的重建系数。损失函数通常是重建误差的平方和:
其约束条件通常是重建系数的和为1。
- 构建低维表示: 通过优化得到的重建系数,使用数值优化法,如最小二乘法来计算最优的低维表示矩阵
,其中每行 表示数据点 在低维空间中的表示。
# KPCA
核主成分分析(Kernel Principal Component Analysis,KPCA)是主成分分析(PCA)的一种非线性扩展方法。它利用核函数处理非线性特征,有效捕捉数据的复杂结构和非线性关系。与传统PCA不同,KPCA不仅可以降维,还能将数据映射到高维空间,以更好地描述数据的内在结构。
PCA用于无监督数据处理,旨在将原始数据从m维降至k维。然而,PCA在处理非线性可分的数据时表现不佳,难以正确分离。相比之下,KPCA通过核技巧克服了这一限制,能够将数据在高维特征空间中进行非线性映射,从而在目标维度中实现更好的分离性能。无论是PCA还是KPCA,它们的共同目标都是优化数据的线性可分性,以便更好地适应数据分析和模式识别的需求。其具体步骤为:
- 数据标准化: 为了避免变量之间的差异影响分析结果,我们需要先对数据集
进行标准化处理,确保数据的均值 ,方差 。 - 计算核矩阵(Kernel Matrix): KPCA的核心是通过核函数计算数据点之间的相似度。常用的核函数包括高斯核(RBF核)、多项式核、sigmoid核等,其中,径向基函数核是最常见最有效的核函数之一。核矩阵
的元素 表示数据点 和 之间的相似度,可以用核函数计算(以径向基函数核为例):
- 中心化核矩阵: 将核矩阵K按列或按行进行中心化。假设我们有
行 列共 个样本的核矩阵 ,其元素 表示数据点 和 之间的核函数计算结果。首先我们计算每个样本点的核函数值与所有样本点的核函数值之和,即: ,再计算整个核矩阵的元素之和,即: 。这两部分分别减去了 和 的核函数总和,以消除偏差。最后,我们根据以下公式中心化核矩阵 的元素 :
其中,最后加上的
通过以上步骤,就可以得到中心化后的核矩阵
- 计算特征值和特征向量: 对中心化后的核矩阵
进行特征值分解,得到特征值 和对应的特征向量 ,满足:
- 选择主成分: 选择前
个最大的特征值和对应的特征向量作为主成分,这些特征向量 就是在高维特征空间中的投影方向。
# t-SNE
t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种非线性降维和数据可视化技术,旨在将高维数据映射到二维或三维空间,并且在映射过程中保持数据点之间的局部和全局结构。这种方法特别适用于探索和视觉呈现复杂的高维数据集。与传统的降维算法(如PCA)不同,t-SNE通过优化过程创建了一个新的低维特征空间,其中相似的样本由邻近的点表示,而不相似的样本则由较远处的点表示,从而更有效地捕捉数据的内在结构和关系。其具体步骤为:
- 1.计算相似度和条件概率: 对于给定的高维数据集,首先计算每对数据点之间的相似度。通常使用高斯核(Gaussian kernel)来计算相似度:
其中,
然后根据相似度计算条件概率
- 2.计算低维空间的相似度: 使用
分布计算每对数据点之间的相似度 :
- 3.最小化KL散度: 通过最小化高维空间和低维空间之间的KL散度来优化数据点在低维空间中的分布:
- 4.梯度下降优化: 使用梯度下降等优化算法,更新低维空间中每个数据点的位置
,以减少KL散度。 - 重复步骤2到步骤4,直到达到预定的迭代次数或者KL散度收敛到一个较小的值。
需要注意的是:t-SNE的优化过程中,由于随机初始化和损失函数的非凸性,可能会导致不同运行结果。
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.