数据标准化
# 特征筛选
# 1、作用
数据标准化包括去量纲化和一致化。去量纲化旨在消除不同指标由于量纲差异导致的不可比性。故首先需将指标进行无量纲化,消除量纲影响后再进行接下来的分析和比较。
例如,某个变量的数值在1-10之间,而另一个变量的数值范围在100-1000之间,此时若进行综合评价,从数值的角度,很有可能数值变化范围大的变量,它的绝对作用就会较大,所占的比重较大。
一致化是确保所有指标的作用方向一致。在评价多个指标的综合作用时,有些指标是正向指标,即数值越大越好;而有些是负向指标,即数值越小越好。如果直接将这两类指标的效果直接相加,由于作用方向不同会导致评价结果失真。因此,需要对逆向指标进行一致化处理,通常是通过取反或其他适当的转换方法,以确保所有指标在综合评价中的作用方向一致。
# 2、输入输出描述
输入:一项或以上定量变量。
输出:新生成标准化后的变量。
# 3、案例示例
案例:现有某个年级关于各个班级的平均分以及优秀率、挂科率。仔细观察数据,文化平均分和体育平均分它们的数据量纲不一样,文化科的总分是100,体育的总分是50,如果我们不做数据标准化,那么肯定是文化科更能影响综合评价结果(因为文化课的值更大),所以需要对数据进行标准化处理。另外,去评价一个班级的综合水平,我们期望平均分、优秀率越高越好,挂科率越小越好,这就需要我们去对平均分、优秀率指标做正向指标处理,对挂科率做负向指标处理。
# 4、案例数据

数据标准化案例数据
# 5、案例操作
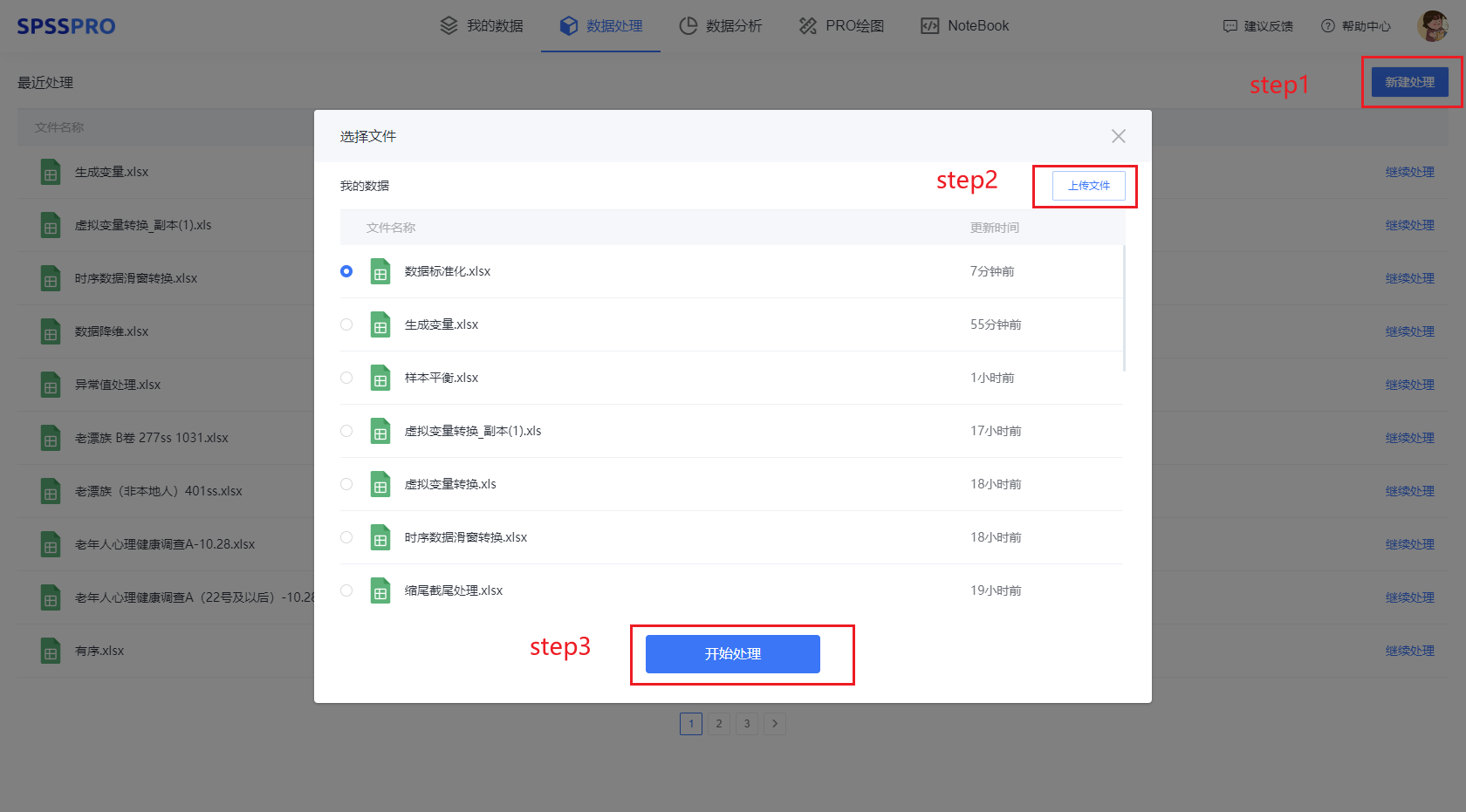
Step1:在“数据处理”模块新建处理;
Step2:上传文件;
Step3:选择对应数据打开后进行预览,确认无误后点击开始处理;
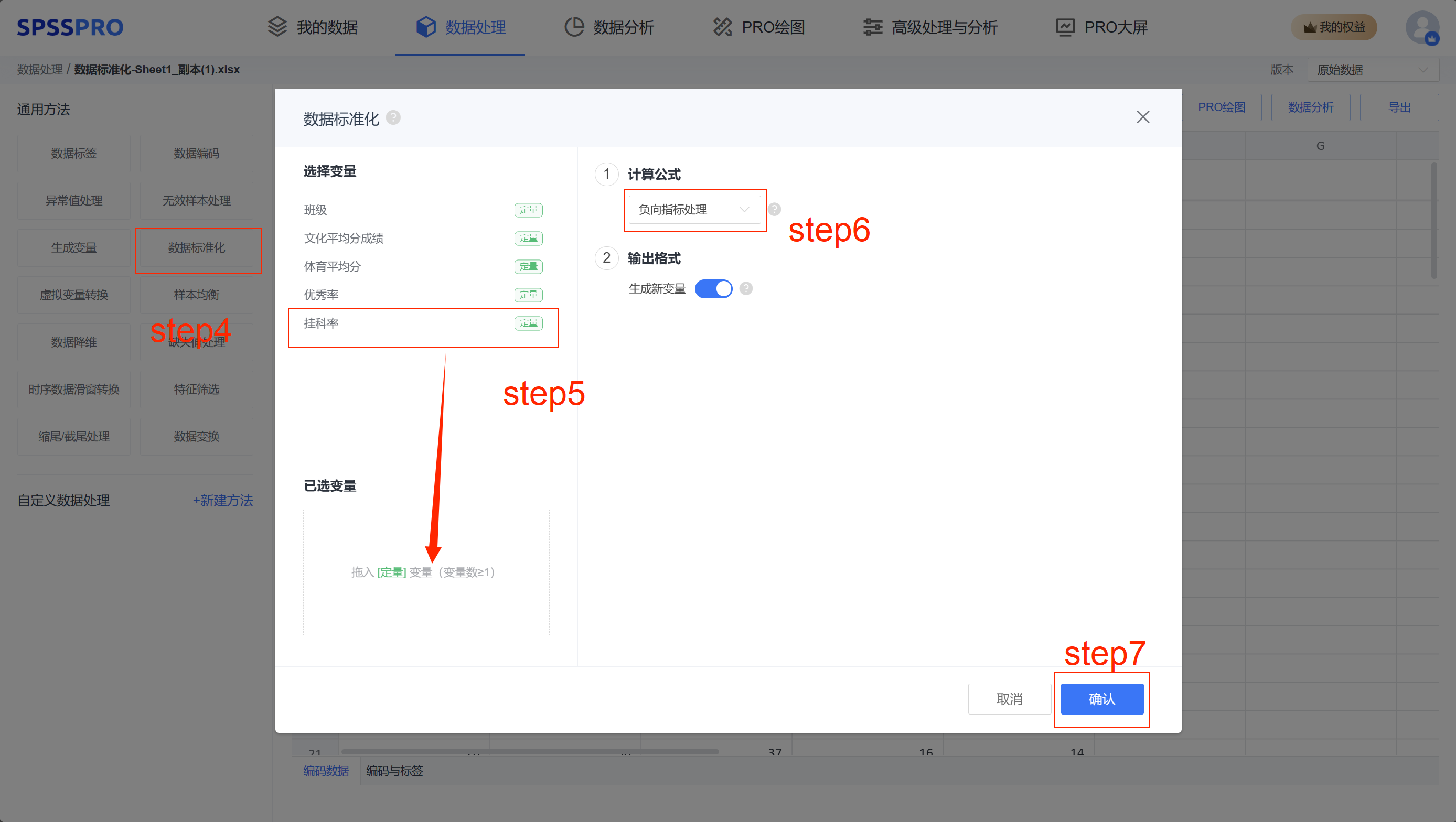
Step4:选择【数据标准化】;
Step5:查看对应的数据数据格式,【数据标准化】要求变量为定量变量,且至少有一项;
Step6:确认参数,有多种数据标准的方法可选择;
Step7:点击【开始处理】,完成全部操作。
# 6、输出结果分析
现同时有正向指标和负向指标,那需要同一量纲且一致化,就需要选择正向指标处理和负向指标处理,正向指标处理事实上就是普通的归一化处理,把数据的值转换到0-1范围内,原本值越大越接近1。
负向指标处理是负向归一化处理,把把数据的值转换到0-1范围内,原本值越小越接近1。

# 7、注意事项
- 数据标准化不支持对存在空值的变量进行处理,需要提前处理空值。
- 当指标中既存在正向指标又存在负向指标的时候,为了统一处理公式,最好只使用正向指标处理-负向指标处理。
# 8、模型理论
(1)Min-Max标准化
Min-Max标准化是一种常见的数据归一化方法,也称为最小-最大缩放方法。它通过线性变换将数据缩放到
- 优点:简单,保留了原始数据的分布信息,适用于大部分情况。
- 缺点:受异常值影响较大,当数据集中存在极大极小值时,会导致结果精度降低。
- 适用场景:当数据的分布和方差不大,并且对于保留数据的分布和范围有较高的要求时。
# z-score标准化
Z-score标准化,也称为零均值标准化,是一种常用的数据标准化方法,旨在将数据转换为均值为0,标准差为1的正态分布。这种方法假设数据符合正态分布(或近似正态分布),适用于许多统计方法和机器学习算法。其公式为:
其中,
- 优点:保留了数据的分布信息。
- 缺点:受异常值影响大,当数据集中存在极大极小值时,会影响到均值和标准差的计算,从而导致结果精度降低。
- 适用场景:适用于数据集符合正态分布或近似正态分布的情况,如回归分析、聚类分析等场景。
# 归一化
SPSSPRO中使用的归一化方法为总和归一化(Sum Normalization),也可以称为总和标准化或按总和缩放。它对数据进行转换,使结果落在
- 优点:简单,保持比例关系。
- 缺点:易受极端值影响;它仅依赖于数据项的总和,在某些情况下,可能会导致信息的丢失和模糊化从而无法充分反映出每个数据项的绝对大小或重要性。
- 适用场景:常用于概率分布、百分比、比例等需要表示数据在整体中的相对贡献或比例的情况下,例如在生成概率分布、计算权重等方面。
# 中心化
中心化(Centering)指的是将数据减去其均值,以使得数据的均值接近于零。其公式为:
- 优点:中心化不仅可以使数据更容易处理,还有助于消除数据中的偏差,使得特征在相对值上更具有可比性。
- 缺点:中心化仅仅改变数据的位置而不改变其变化幅度和分布形态,可能会导致一些绝对数值的信息丢失。在某些算法和分析中,可能需要保留原始数据的绝对数值信息,此时中心化可能不适用。
- 适用场景:在数据分布不平衡的情况下,即当数据分布在一个很大的范围内或者有显著偏差时,中心化可以将数据集中在一个更合理的区间内,使得数据更容易处理和分析。
# 均值化
SPSSPRO中使用的均值化方法为均值归一化,又叫均值标准化,主要目的是将数据调整到相对于其均值的比例,以便消除数据的尺度差异。其公式为:
# 区间化
SPSSPRO中支持自定义压缩在一个自定义的区间
区间化可以使得数据具有统一的尺度和范围,有助于提高机器学习模型的稳定性和收敛速度。
# 初值化
初值化确保序列中的元素都相对于第一个非零元素进行了归一化处理,有助于消除序列中的比例差异。其公式为:
需要注意的是,在使用这种初值化方法时需要确保选择到的第一个非零元素合适,以避免数值计算中的除零错误或者造成不合适的标准化效果。
# 最小值化
# 最大值化
# 正向指标处理
在评价多个指标的综合作用时,有些指标是正向指标,即数值越大越好;而有些是负向指标,即数值越小越好。如果直接将这两类指标的效果直接相加,由于作用方向不同会导致评价结果失真。因此,需要对逆向指标进行一致化处理,通常是通过取反或其他适当的转换方法,以确保所有指标在综合评价中的作用方向一致。
# 负向指标处理
将负向指标准换成正向指标,并使结果落在
# 中间型指标处理
对中间型指标数据做线性变换,使结果落在
# 区间型指标处理
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.