倾向得分匹配
# 1、作用
倾向得分匹配用于比较实验组与控制组的结果变量是否存在差异,它的原理是通过匹配寻找干扰变量值较为相似的样本,以为了减少数据偏差和混杂因素的干扰。
# 2、输入输出描述
输入:研究变量为二分类变量;结果变量为定量变量;干扰变量为定量变量,若为定类变量,建议自行对其进行哑变量化后再进行处理。
输出:匹配效果以及匹配后实验组与控制组中结果变量的差异。
# 3、案例示例
案例:比如想研究房价是否受周边地铁影响,这就把数据分成两组(周边有地铁是实验组,周边没有地铁是对照组)。但是否有学校、是否有电梯、房地产商家、物业商家这些因素为干扰因素,基于倾向得分进行匹配,得到干扰因素尽可能相似的样本,再来比较匹配后实验组和对照组各自的房价是否具有差异。
# 4、案例数据
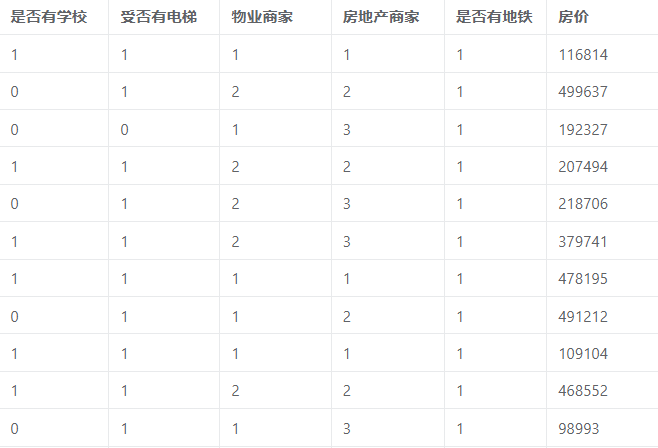
倾向得分匹配分组回归案例数据
# 5、案例操作
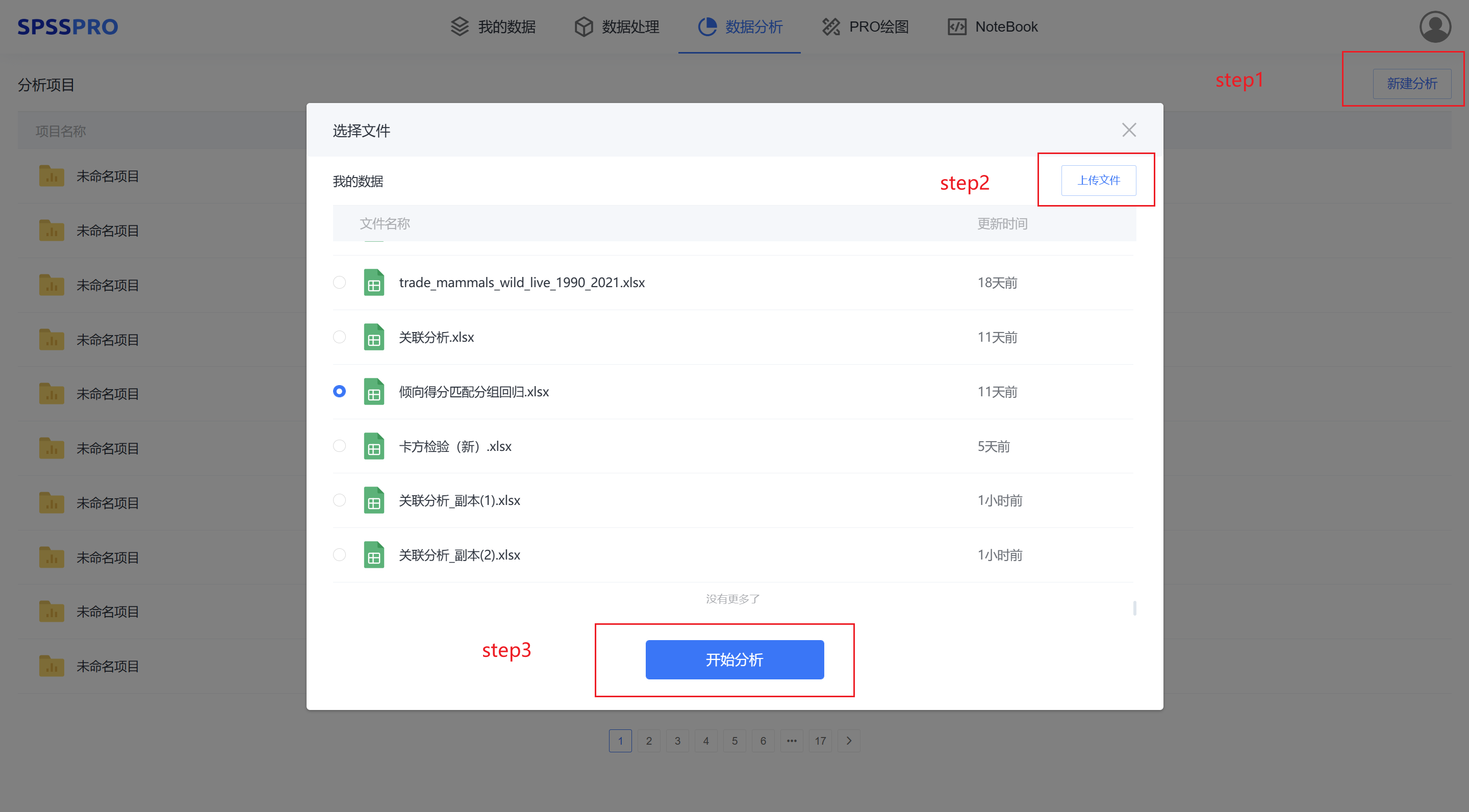
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
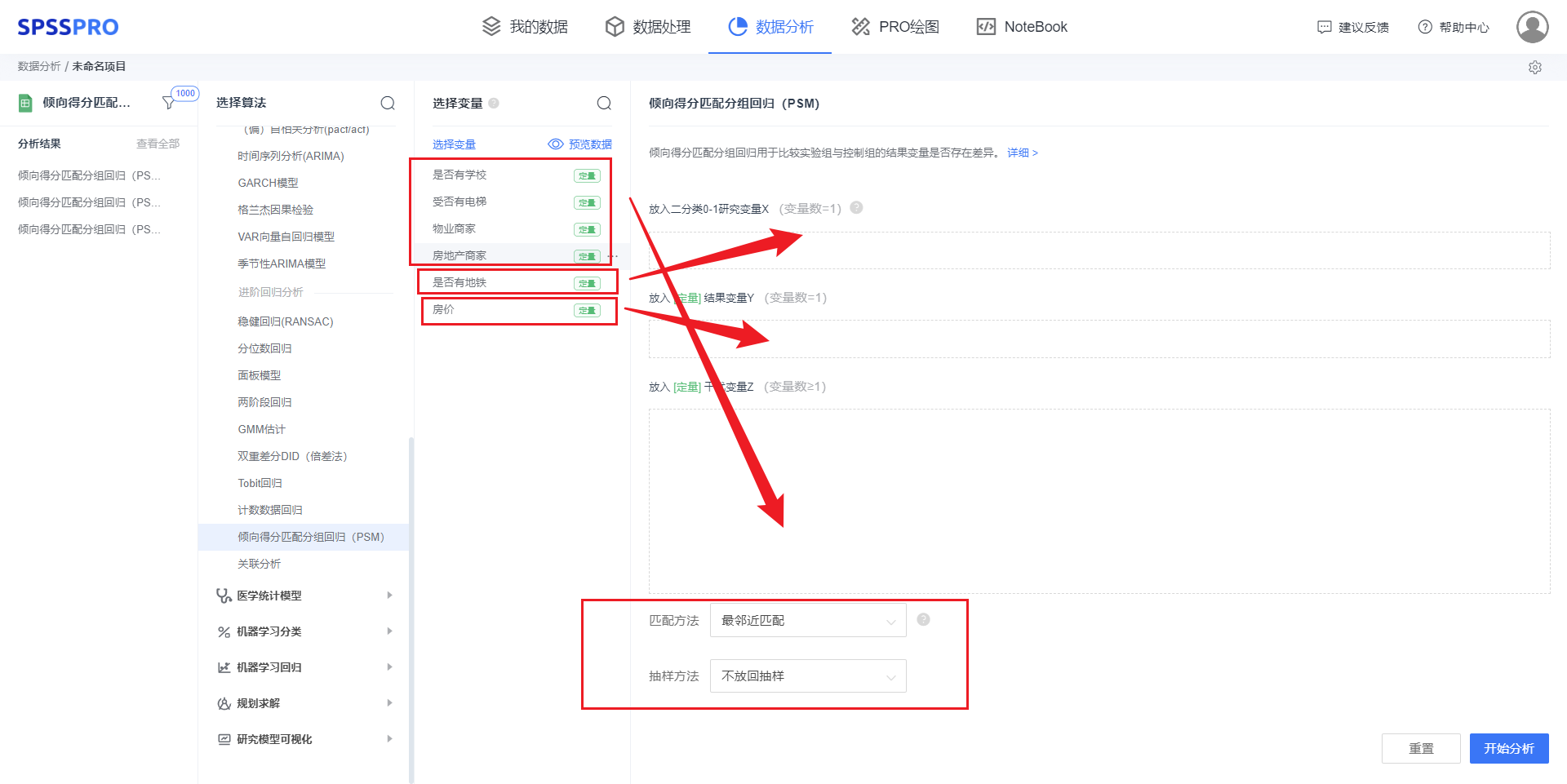
Step4:选择【倾向得分匹配】;
Step5:查看对应的数据数据格式,按要求输入【倾向得分匹配】数据;
Step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
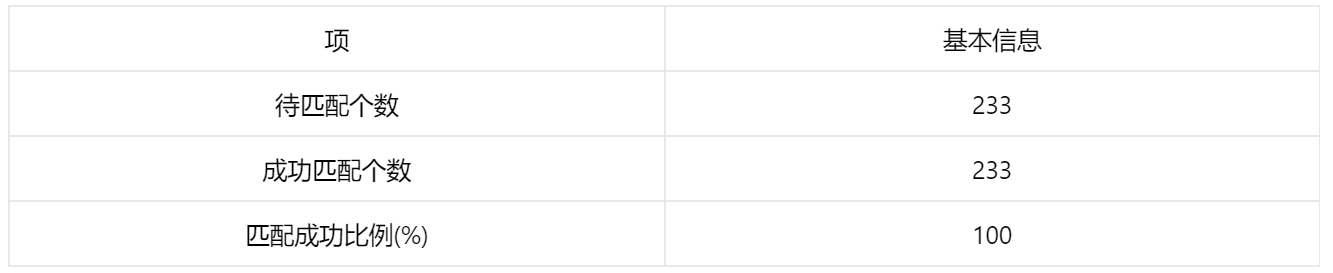
输出结果 1:匹配基本信息表
图表说明:
上表展示了匹配方法以及匹配成功比例等结果。实验组有 233 个样本,也就是 X=1 有 233 个样本,所以待匹配个数有 233 个;倾向得分匹配分组回归是根据实验组的每一个样本,在控制组内去寻找干扰变量尽可能相似的样本。
输出结果 2:匹配前后的均衡性结果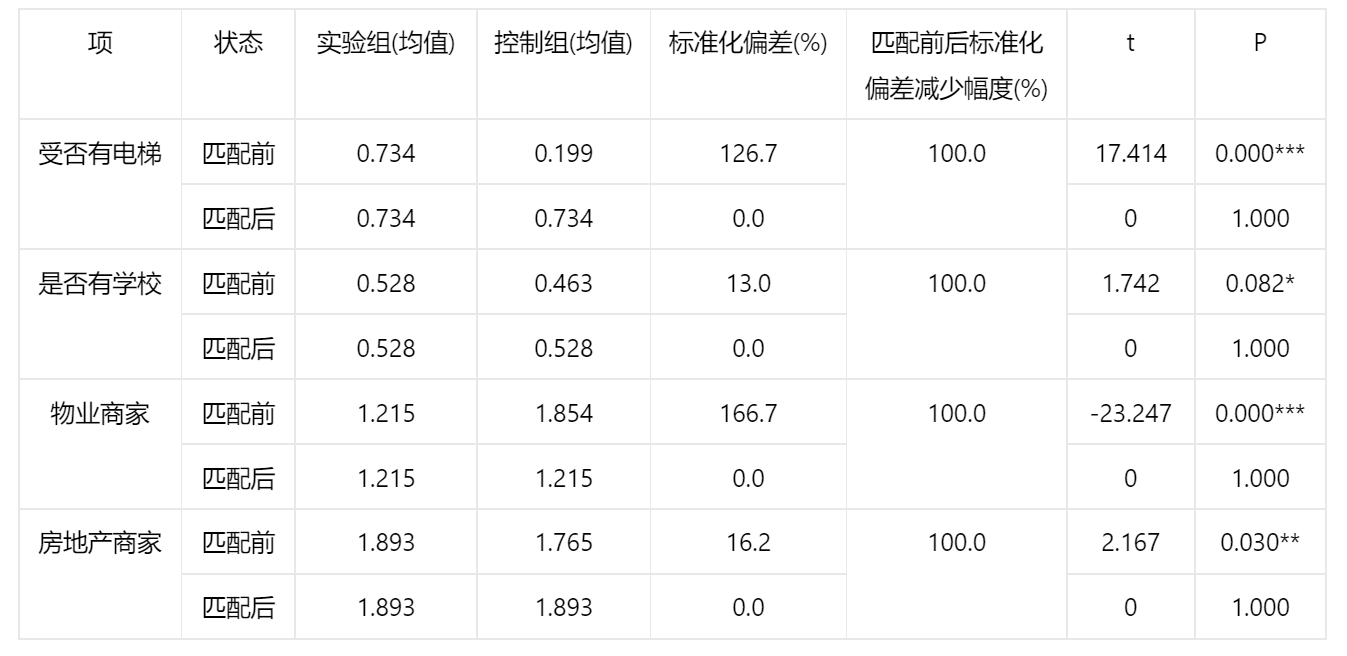
图表说明:上表为匹配前后均衡性检验结果表,目的是为了判断匹配效果。 以下有两个判断匹配效果的方法:
- 若”匹配前后标准化偏差减少幅度“较大,即匹配后的干扰变量 z 值更加集中,说明匹配效果较好。
- 若”匹配前“T 检验有显著性(P<0.05),但”匹配后“ T 检验没有显著性(P>0.05),则说明匹配效果较好。
由上表可知,四个混杂变量在匹配前后标准化偏差减少 100%,并且都是”匹配前“T 检验有显著性(P<0.05),但”匹配后“ T 检验没有显著性(P>0.05),说明匹配效果极好。
输出结果 3:匹配前后标准差偏差变化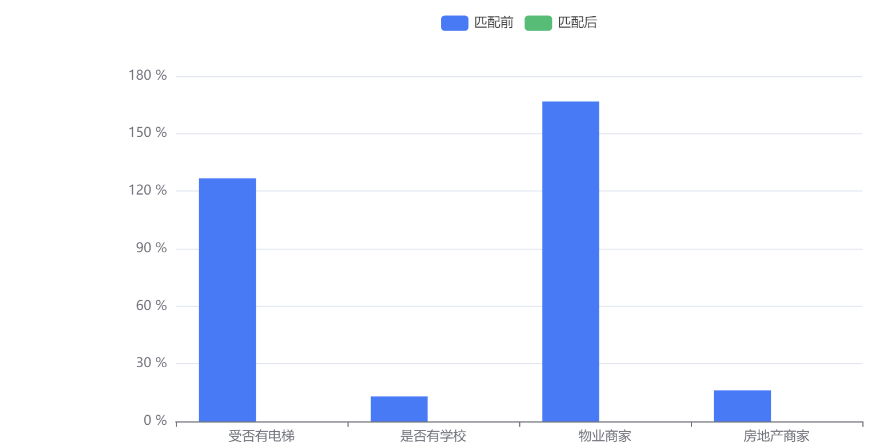
图表说明:上图直观展现了干扰变量 Z 在匹配前-匹配后的标准化偏差变化图,若匹配前后标准化偏差减少幅度“较大,说明匹配效果较好。
输出结果 4:ATT 平均处理效应分析
图表说明:表为匹配前后 ATT 平均处理效应分析结果表,目的是为了研究匹配成功后‘结果变量 Y’的值是否存在着显著性差异。
- 匹配前是指在匹配之前,实验组与控制组在‘结果变量 Y’上是否存在着差异性,其意义不大。
- 匹配后是指在匹配之后,匹配成功在‘结果变量 Y’之间是否存在着差异性,如果对应的 P 值小于 0.05,即意味着实验组与控制组在‘结果变量 Y’上存在着显著性差异。
所以主要是看匹配后的由 ATT 效应结果可知,匹配后数据的显著性 P 值为 7.003,不呈现显著性,不能拒绝原假设,实验组与控制组数据在“结果变量”上不存在显著性差异。
# 7、注意事项
- 倾向得分匹配是根据实验组的每一个样本,在控制组内去寻找干扰变量尽可能相似的样本,所以待匹配的样本永远是值为 1 的实验组。
- 倾向得分匹配法通常需要较大的样本容量来实现高质量匹配。因此有时不适用于小样本容量的研究;
# 8、模型理论
倾向得分匹配步骤如下:
步骤 1 选择合适的混杂变量集
混杂变量集一般来说应该对被解释变量和解释变量都有影响,所以我们需要通过匹配相似的混杂因素从而消除其对因变量的影响。
步骤 2 计算倾向值
基于选定的协变量集,通过“probit”或“logit”模型来计算个体进入处理组的概率(倾向值)。
步骤 3 进行匹配
根据各个样本的倾向得分的距离来进行样本匹配,以每一个实验组为基准,在控制组内去寻找干扰变量尽可能相似的样本。其中匹配的方法有:
(1)最邻近匹配(nearest neighbor matching)
将控制组中与处理组倾向得分差异最小的个体进行匹配。虽然处理组所有个体都能匹配成功,但是不放弃任一处理组个体可能影响匹配质量,降低处理效应的精确度。
(2)半径匹配(radius matching)
提前设定卡尺,按照半径范围寻找控制个体进行匹配,卡尺越小匹配严格程度越高。
步骤 4 根据匹配后的样本计算平均处理效应
将匹配后的对照组和实验组的因变量 Y 进行平均效应 ATT 处理,令 D=0 表示未接受干预;D=1 表示接受干预;Yi(1)是指各个样本在接受干预的结果变量;Yi(0)是指各个样本在未接受干预的结果变量:
![]()
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] 陈强. 高级计量经济学及 Stata 应用[M]. 高等教育出版社, 2010.