计数数据回归
# 1、作用
如若因变量Y只能取非负整数(如0,1,2,3,...)则称此类数据为计数数据,研究自变量X对因变量Y的影响时,需要使用一类特殊方法——计数数据回归。该方法中的常用模型有泊松回归、负二项回归等。
# 2、输入输出描述
输入:定量的计数数据因变量Y、自变量X。
输出:计数数据回归的方程以及部分检验结果。
# 3、案例示例
案例:刑事犯罪侦查中心根据前科、入狱月数、判刑月数、就业情况和人种等,预测当年被捕次数。
# 4、案例数据
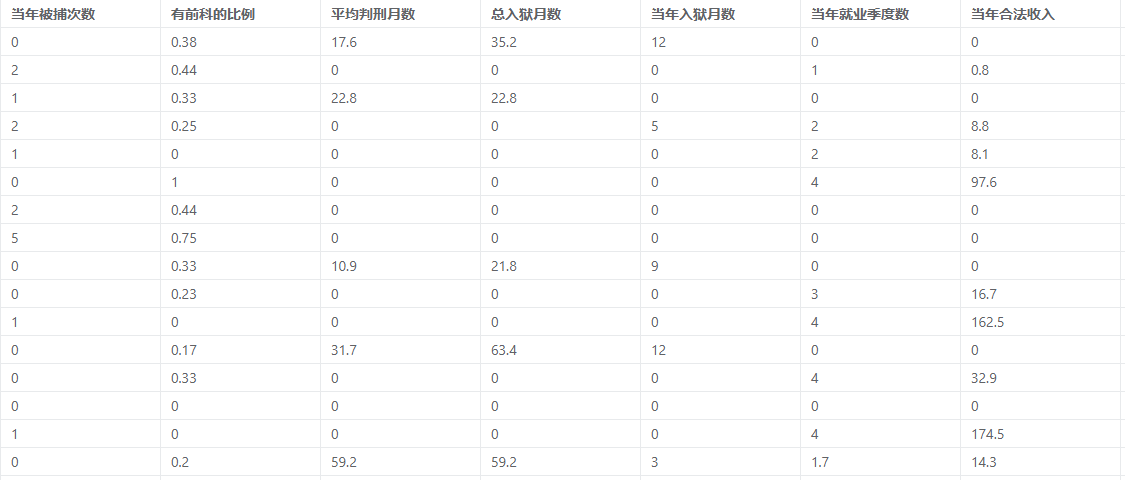
计数数据回归案例数据
# 5、案例操作
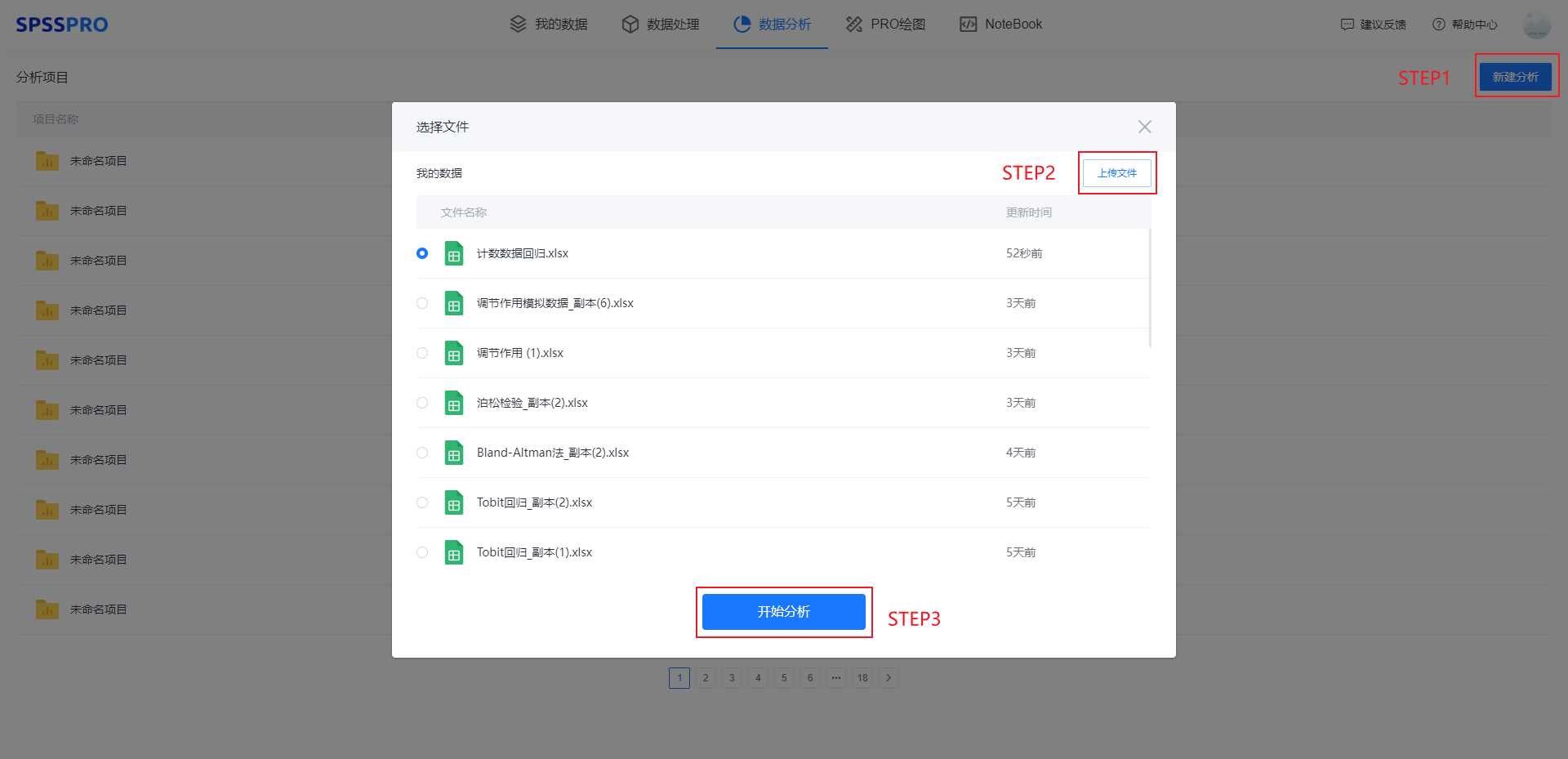
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;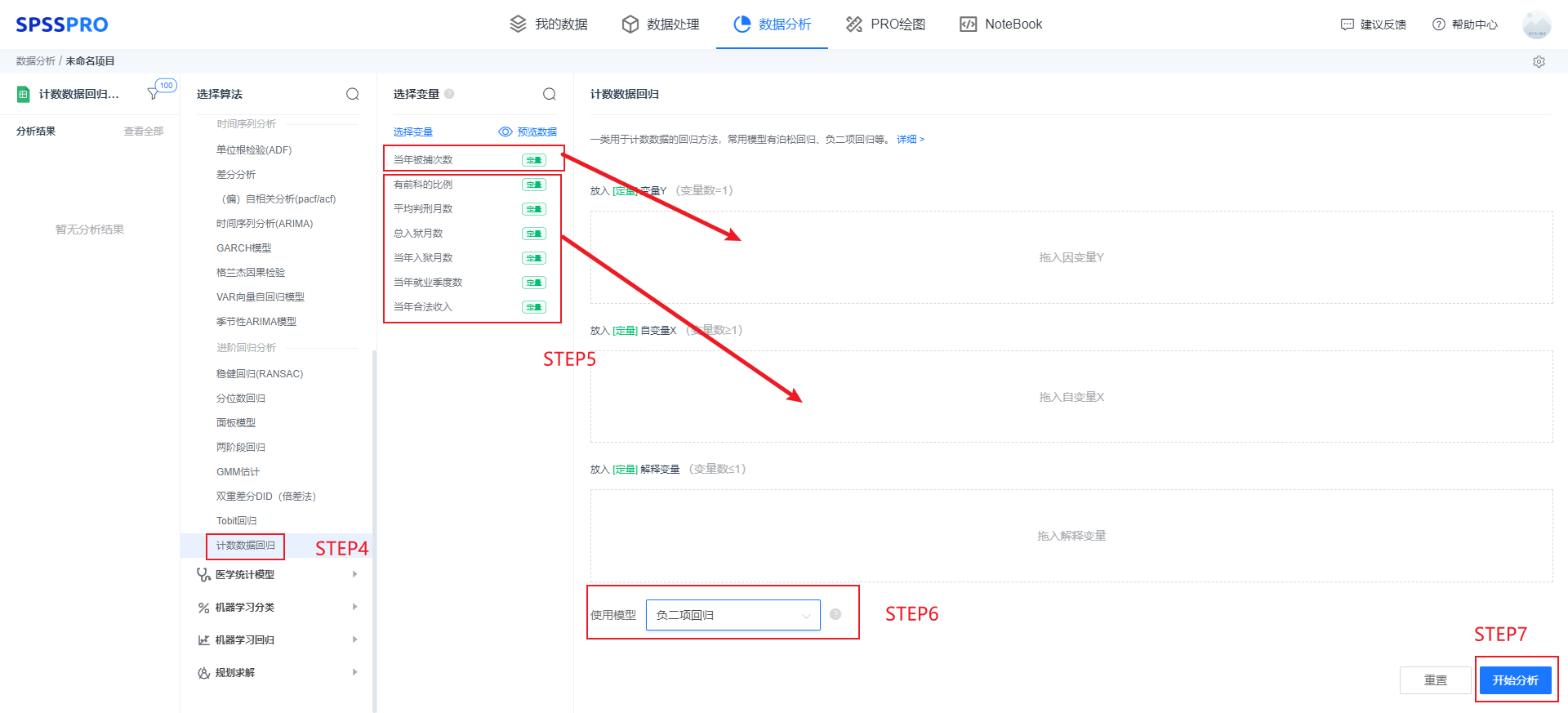
step4:选择【计数数据回归】;
step5:查看对应的数据数据格式,按要求输入【计数数据回归】数据;
step6:选择使用模型,本例使用模型为【负二项回归】;
step7:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果1:O检验
图表说明:
上表展示了O检验的结果,用于判定数据是否过离散。
智能分析:
模型的O检验的结果显示,显著性P值0.000***,水平上呈现显著性,拒绝原假设,因而数据存在过离散现象,可以考虑使用负二项回归。
输出结果2:似然比检验结果
图表说明:
上表展示了模型似然比检验结果,对P值进行分析,如果P<0.05,则说明模型有效;反之则说明模型无效。
智能分析:
模型的似然比卡方检验的结果显示,显著性P值0.015**,水平上呈现显著性,拒绝原假设,因而模型是有效的。
输出结果3:计数数据回归结果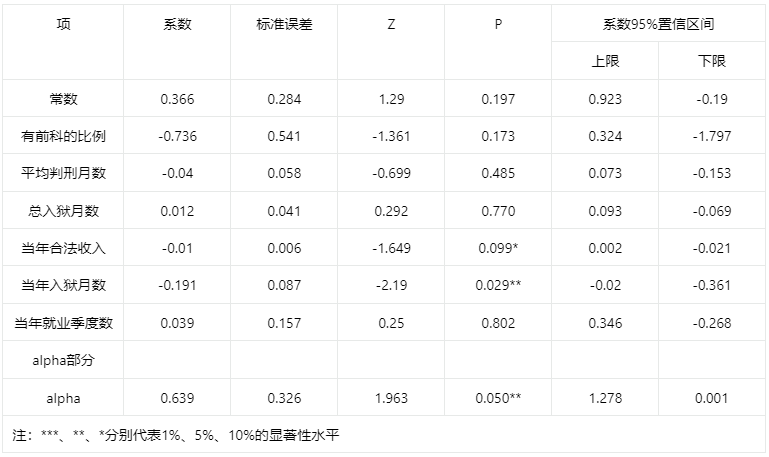
图表说明:
上表展示了模型的参数结果。包括模型的系数、标准误差、z值、P值、置信区间等用于分析模型的公式。
智能分析:
模型的公式为:0.366- 0.736 * 有前科的比例- 0.04 * 平均判刑月数+ 0.012 * 总入狱月数- 0.01 * 当年合法收入- 0.191 * 当年入狱月数
alpha值的系数95%置信区间为[-0.268,0.346],符合alpha为0的假设,不推荐使用负二项回归。
字段有前科的比例显著性P值为0.173,水平上不呈现显著性,不能拒绝原假设,因此有前科的比例项系数不显著。
字段平均判刑月数显著性P值为0.485,水平上不呈现显著性,不能拒绝原假设,因此平均判刑月数项系数不显著。
字段总入狱月数显著性P值为0.770,水平上不呈现显著性,不能拒绝原假设,因此总入狱月数项系数不显著。
字段当年合法收入显著性P值为0.099*,水平上不呈现显著性,不能拒绝原假设,因此当年合法收入项系数不显著。
字段当年入狱月数显著性P值为0.029**,水平上呈现显著性,拒绝原假设,因此当年入狱月数项系数显著。
输出结果4:模型路径图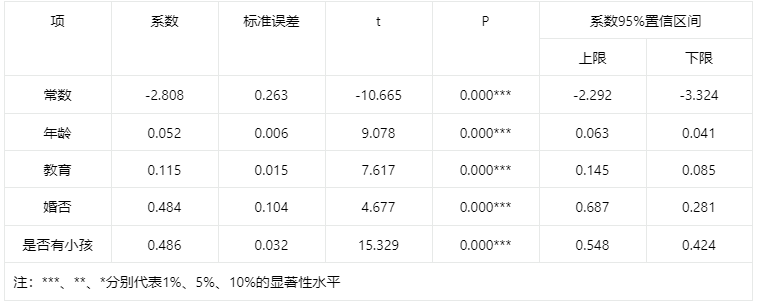
图表说明:
上表展示了模型的参数结果。包括模型的系数、标准误差、t值、P值、置信区间等用于分析模型的公式。
智能分析:
模型的公式为:
工资的对数值=-2.808+0.052×年龄+0.115×教育+0.484×婚否+0.486×是否有小孩
字段const显著性P值为0.000***,水平上呈现显著性,拒绝原假设,因此const项系数显著。
字段年龄显著性P值为0.000***,水平上呈现显著性,拒绝原假设,因此年龄项系数显著。
字段教育显著性P值为0.000***,水平上呈现显著性,拒绝原假设,因此教育项系数显著。
字段婚否显著性P值为0.000***,水平上呈现显著性,拒绝原假设,因此婚否项系数显著。
字段是否有小孩显著性P值为0.000***,水平上呈现显著性,拒绝原假设,因此是否有小孩项系数显著。
输出结果4:计数数据回归结果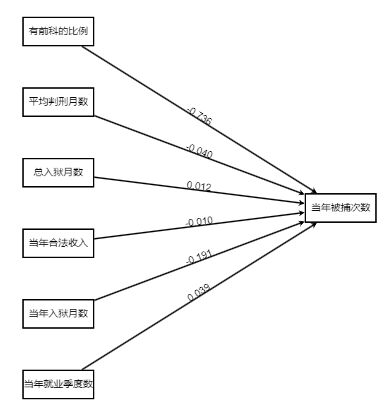
图表说明:
上图以路径图形式展示了本次模型结果,主要包括模型的系数,用于分析X对于Y的影响关系情况。
输出结果5:模型结果预测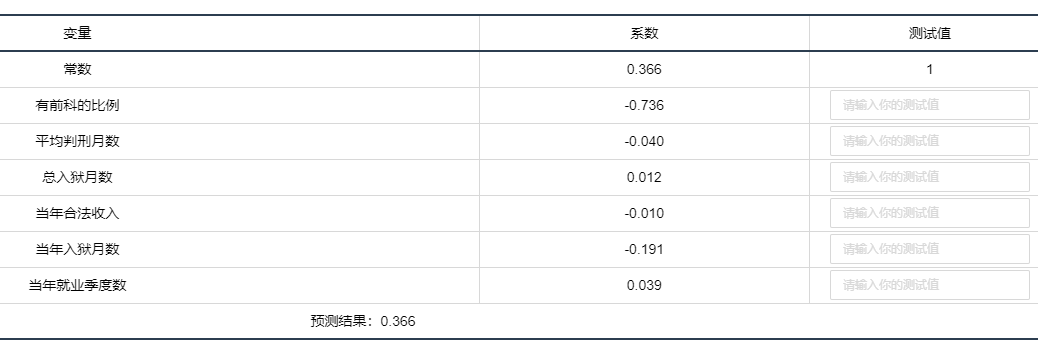
图表说明:
上表格显示了计数数据回归模型的预测情况。
# 7、注意事项
- 有三种判断模型选择的方法:
根据O检验:
O检验如果呈现显著性,则拒绝原假设,因而数据存在过离散现象,推荐使用负二项回归。
根据数据的描述性分析:
1.当因变量Y的方差近似等于均值时,往往采用泊松回归。
2.当因变量Y的方差大于均值时,往往采用负二项回归。
3.当因变量Y在0取值较多,正整数部分方差近似等于均值时,往往采用零膨胀泊松分布回归。
4.当因变量Y在0取值较多,正整数部分方差大于均值时,往往采用零膨胀负二项回归。
根据Alpha值:
Alpha值的95%置信区间是否不包含0,如果不包含则不符合alpha为0的假设,推荐使用负二项回归。
其中前两种方法更优先选择用于模型选择的判断。
- 当选择零膨胀模型(零膨胀泊松/零膨胀负二项回归)时会附带Vuong检验,但有论文认为Vuong检验不适用于零膨胀的检验,故结果仅供参考。
# 8、模型理论
# 泊松回归
首先回顾泊松分布,泊松分布的概率密度函数为:
其中,
当y=k时,为事件发生k次的概率,为
若y≥k,
则泊松回归的基本形式为:
式中:
# 负二项回归
负二项回归亦称为帕斯卡分布,有两个基本模型:
1)设p为伯努利试验中每次试验成功的概率,则伯努利试验列中恰好出现n次成功所需试验次数Y服从参数为(n,p)的负二项分布。
2)设p为伯努利试验中每次试验成功的概率, 则伯努利试验列中恰好出现n次成功之前失败的次数X服从参数为(n,p) 的负二项分布。
其中μ是自变量的指数函数,负二项方差为
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] 陈强. 高级计量经济学及Stata应用[M]. 高等教育出版社, 2010.