相关性分析
# 相关性分析
# 1、作用
相关分析是对变量两两之间的相关程度进行分析。相关分析的计算方式有三种,分别是 Pearson 相关系数(适用于定量数据,且数据满足正态分布)、Spearman 相关系数(数据不满足正态分布时使用)。Kendall's tau -b 相关系数(有序定类变量)
# 2、输入输出描述
输入:两个或者两个以上的定量变量或有序定类变量
输出:两两定类变量之间是否呈现显著性相似以及相似的程度
# 3、案例示例
示例:人的身高和体重之间;空气中的相对湿度与降雨量之间的相关关系都是相关分析研究的问题
# 4、案例数据
相关性分析案例数据
# 5、案例操作
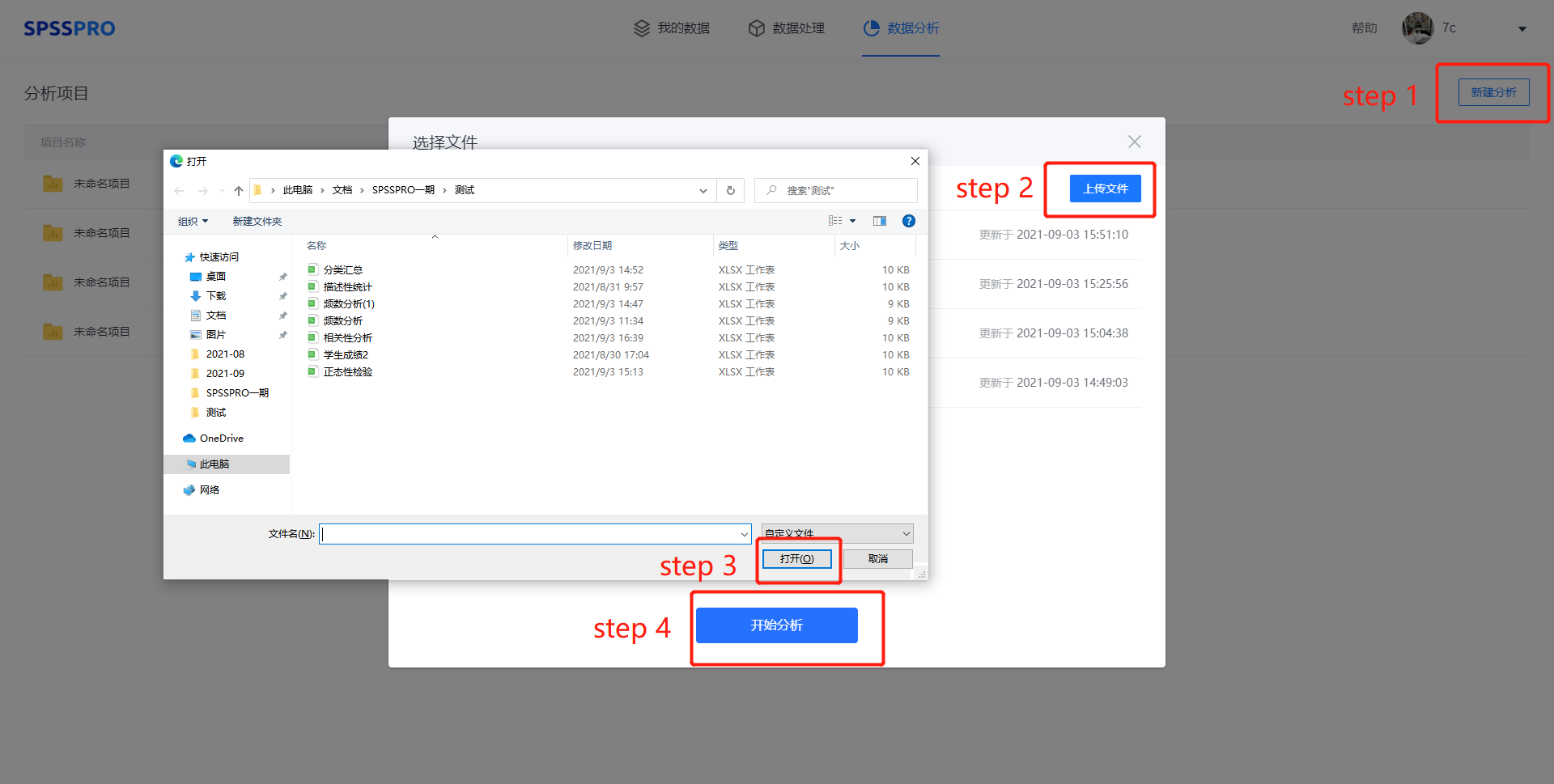 Step1:新建分析;
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
Step4:选中上传的数据或者之前上传过的数据进入分析页面进行分析;
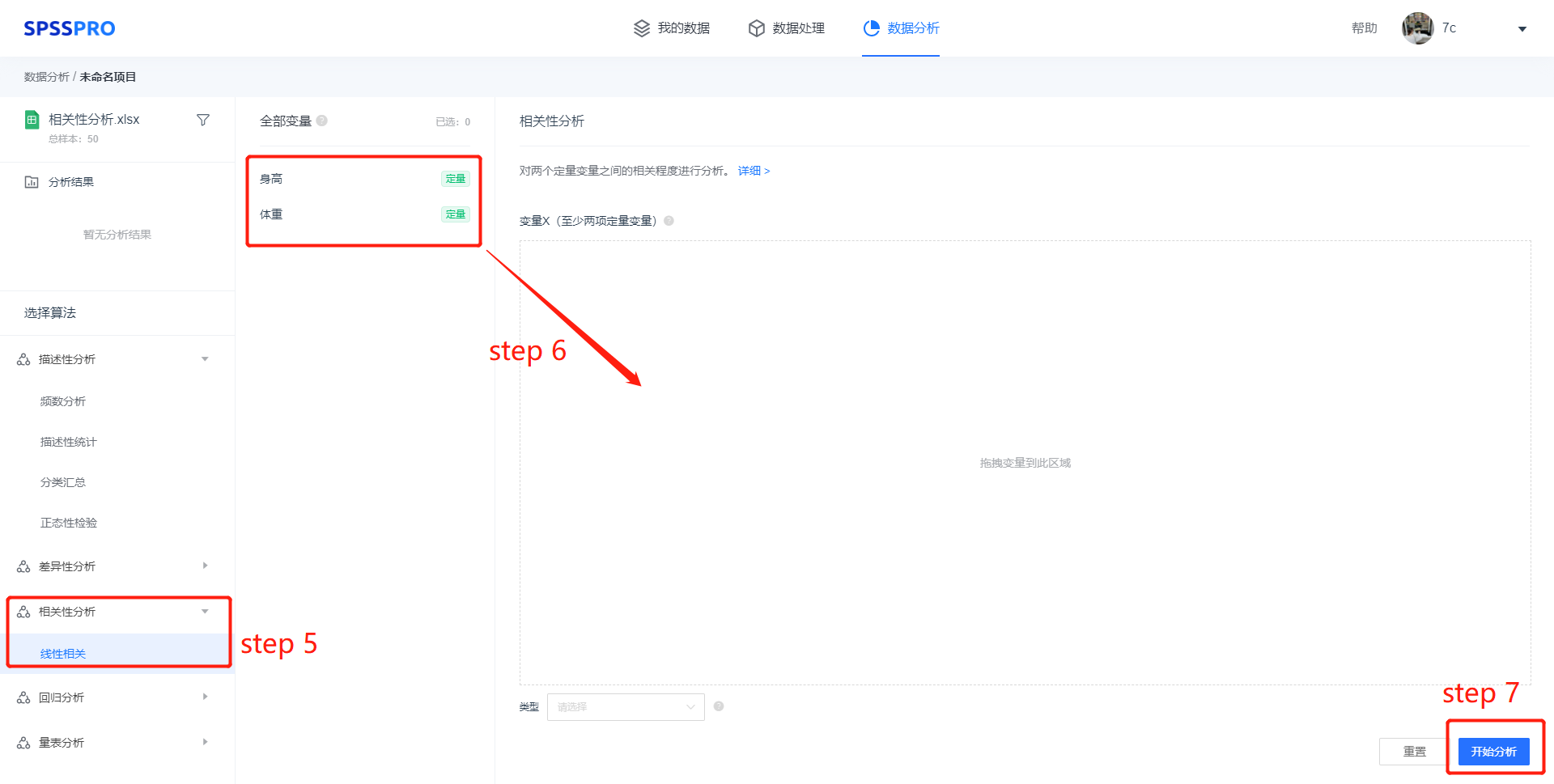
step5:选择【线性分析】;
step6:查看对应的数据数据格式,【线线性分析】要求输入数据为定量变量,至少两项定量变量,选择对应分析类型;
step7:点击【开始分析】,完成全部操作
# 6、输出结果分析
输出结果 1:相关系数表
| 身高 | 体重 | |
|---|---|---|
| 身高 | 1.000(***) | 0.886(0.000) |
| 体重 | 0.886(0.000) | 1.000(***) |
图表说明: 上表展示了模型检验的参数结果表,包括了相关系数、显著性 P 值。P 值呈现显著性(0.000<p<0.01),说明两变量之间存在相关性。
输出结果 2:相关系数热力图
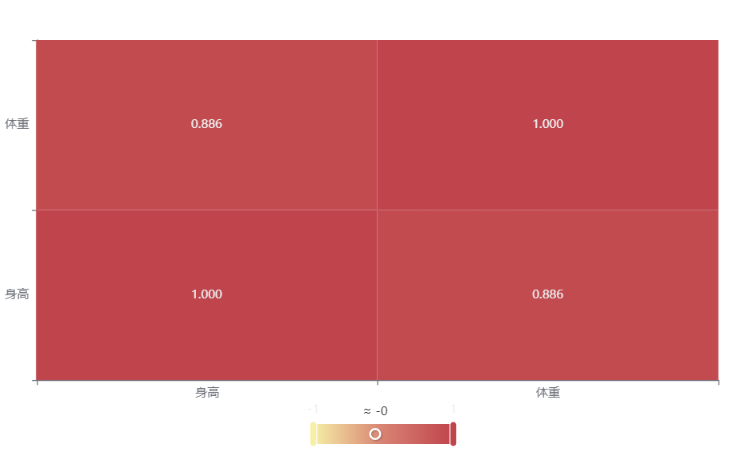
图表说明: 上图展示了热力图的形式展示了相关系数的值,主要通过颜色深浅去表示值的大小。
# 7、注意事项
- Pearson 相关系数适用于定量数据,且要求数据满足正态分布、Spearman 相关系数是数据不满足正态分布时使用,也可用于分析有序定类变量,Kendall's tau -b 相关系数用于分析有序定类变量
# 8、模型理论
皮尔逊相关系数
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:

上式定义了总体相关系数,常用希腊小写字母 作为代表符号。估算样本的协方差和标准差,可得到皮尔逊相关系数,常用英文小写字母
作为代表符号。估算样本的协方差和标准差,可得到皮尔逊相关系数,常用英文小写字母 代表:
代表:

 亦可由
亦可由  样本点的标准分数均值估计,得到与上式等价的表达式:
样本点的标准分数均值估计,得到与上式等价的表达式:

其中  、
、  及
及  分别是对
分别是对 样本的标准分数、样本平均值和样本标准差。
样本的标准分数、样本平均值和样本标准差。
斯皮尔曼相关系数
斯皮尔曼相关系数被定义成等级变量之间的皮尔逊相关系数。对于样本容量为n的样本,n个原始数据被转换成等级数据,相关系数 ρ 为

原始数据依据其在总体数据中平均的降序位置,被分配了一个相应的等级。如下表所示:
| 变量 Xi | 降序位置 | 等级 xi |
|---|---|---|
| 0.8 | 5 | 5 |
| 1.2 | 4 | 4 |
| 1.2 | 3 | 3 |
| 2.3 | 2 | 2 |
| 18 | 1 | 1 |
实际应用中,变量间的连结是无关紧要的,于是可以通过简单的步骤计算 ρ.被观测的两个变量的等级的差值,则 ρ 为

其中 P 是一致对的数量,Q 是不一致对的数量,T 是仅在 x 中的系数,U 是仅在 y 中的系数。如果同一分组在 x 和 y 中出现相同数量,则不将其添加到 T 或 U 中。
# 9、手推步骤
# Step 1:计算均值
总样本数
身高均值:
体重均值:
# Step 2:计算偏差乘积与平方
对每个数据点计算:
示例计算(序号1):
- 乘积:
- 平方:
,
# Step 3:应用皮尔逊公式
如下所示:
最终结果:
# Step 4:显著性检验与相关性程度判断
- 根据输出结果1中的P值(
),远小于 ,说明身高与体重的相关性在统计学上显著。 - 皮尔逊相关系数
,根据常规标准: 表示高度正相关。
# 10、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]张厚粲,徐建平.现代心理与教育统计学.北京:北京师范大学出版社,1988:112-115
[3]Fieller, E.C.; Hartley, H.O.; Pearson, E.S. (1957) Tests for rank correlation coefficients. I. Biometrika 44, pp. 470–481
[4]Piantadosi, J.; Howlett, P.; Boland, J. (2007) "Matching the grade correlation coefficient using a copula with maximum
disorder", Journal of Industrial and Management Optimization, 3 (2), 305–312
[5]Maurice G. Kendall, “The treatment of ties in ranking problems”, Biometrika Vol. 33, No. 3, pp. 239-251. 1945.