自定义数据处理
操作视频
SPSSPRO教程-自定义数据处理 # 1、作用
自定义算法基于 Python,在自定义数据处理过程中,可以自写代码对 df 进行修改并运行,若是运行结束后 df 的数据集有所修改,就会出现”替换当前数据“按钮,点击后将更新数据。更新后的数据可以继续进行其它分析。
# 2、操作步骤
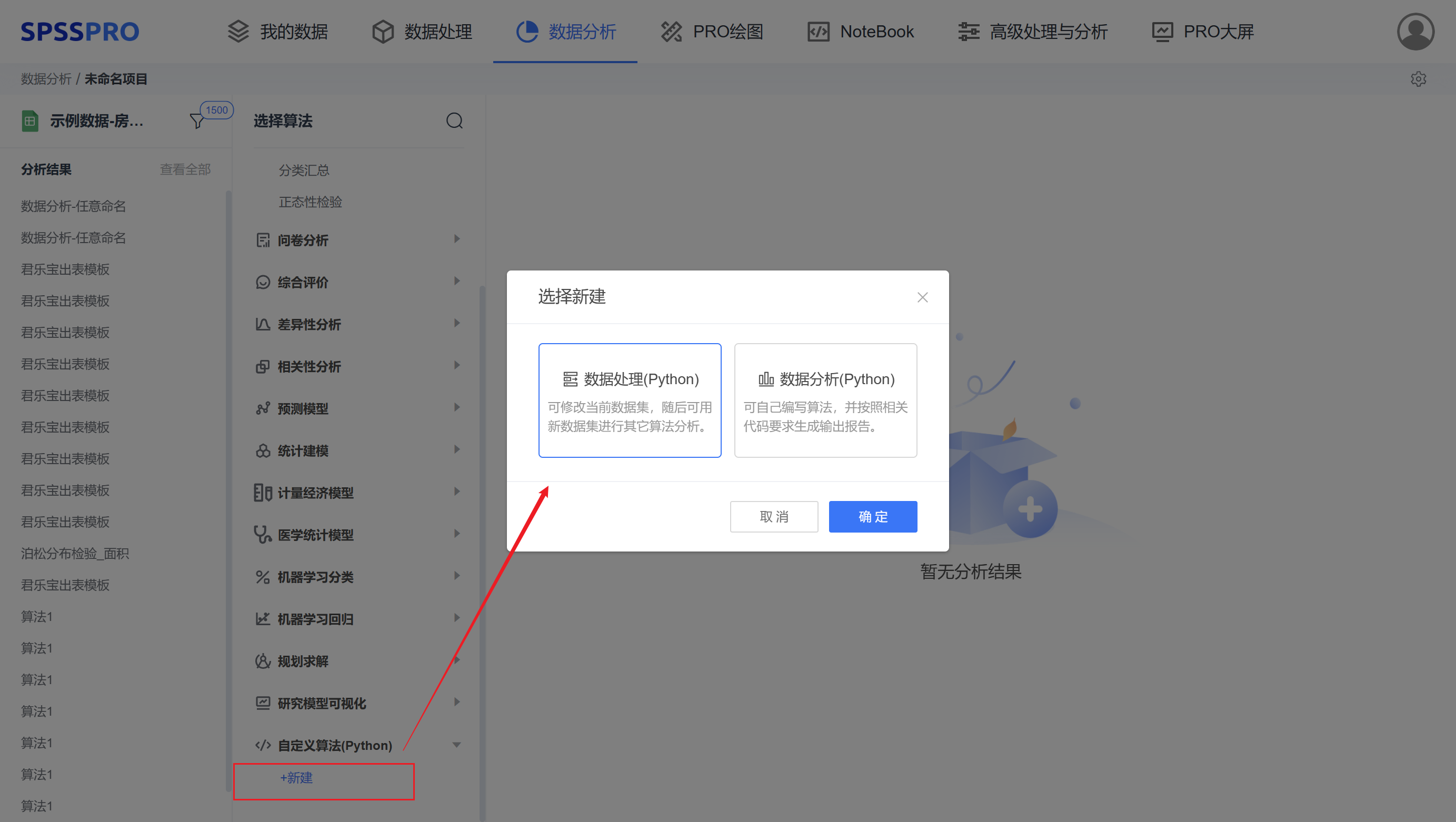
Step1:在【自定义算法(Python)】中点击新建,按照算法目的来创建脚本。
数据处理:可修改当前数据集 df,随后可用新数据集进行其它算法分析。
数据分析:可自己编写算法,并按照相关代码要求生成输出报告。
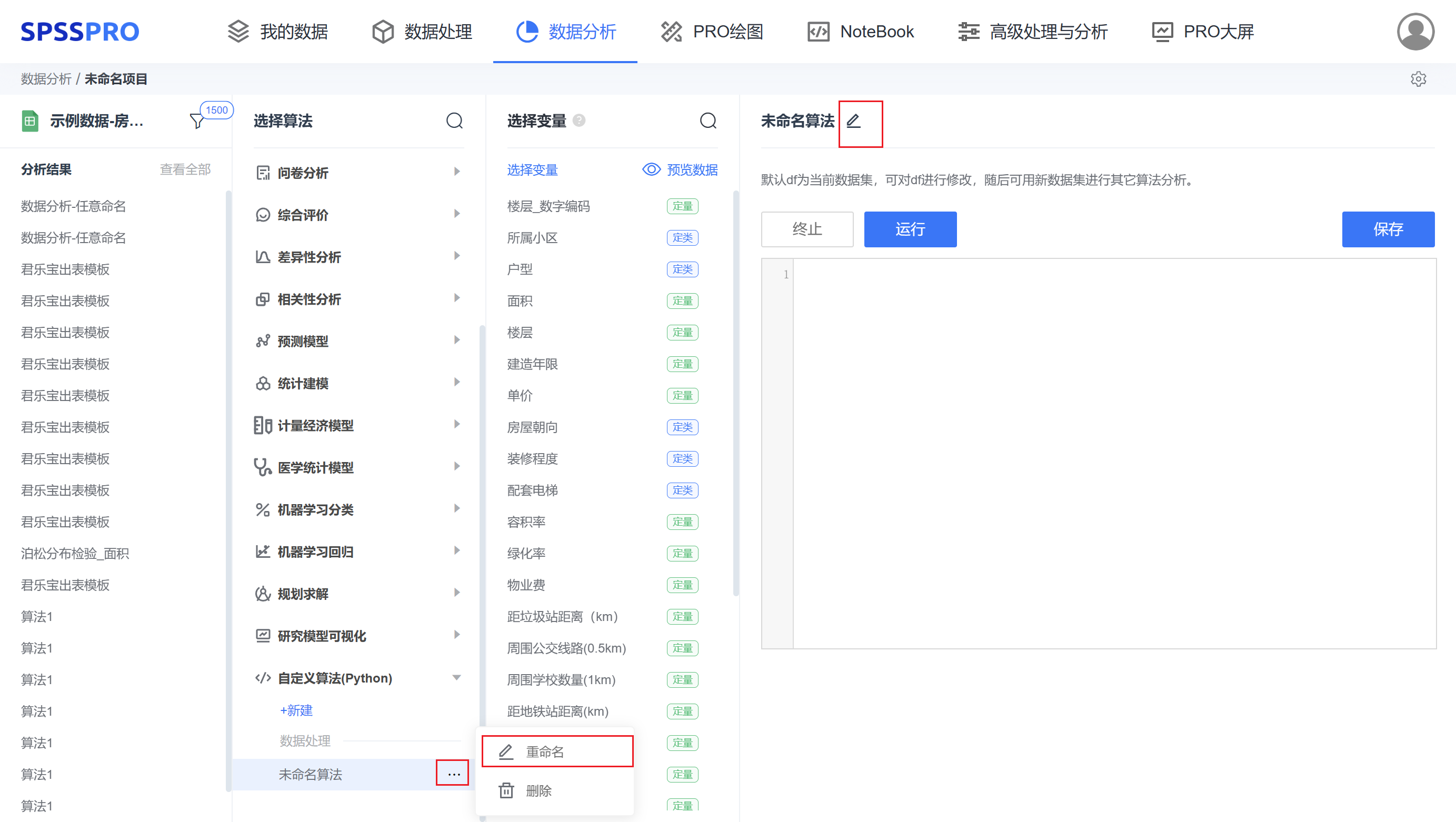
Step2:对算法命名,当前有两个渠道对算法进行重命名。
Step3:开始填写代码,点击”运行“按钮,也可随时”终止“。
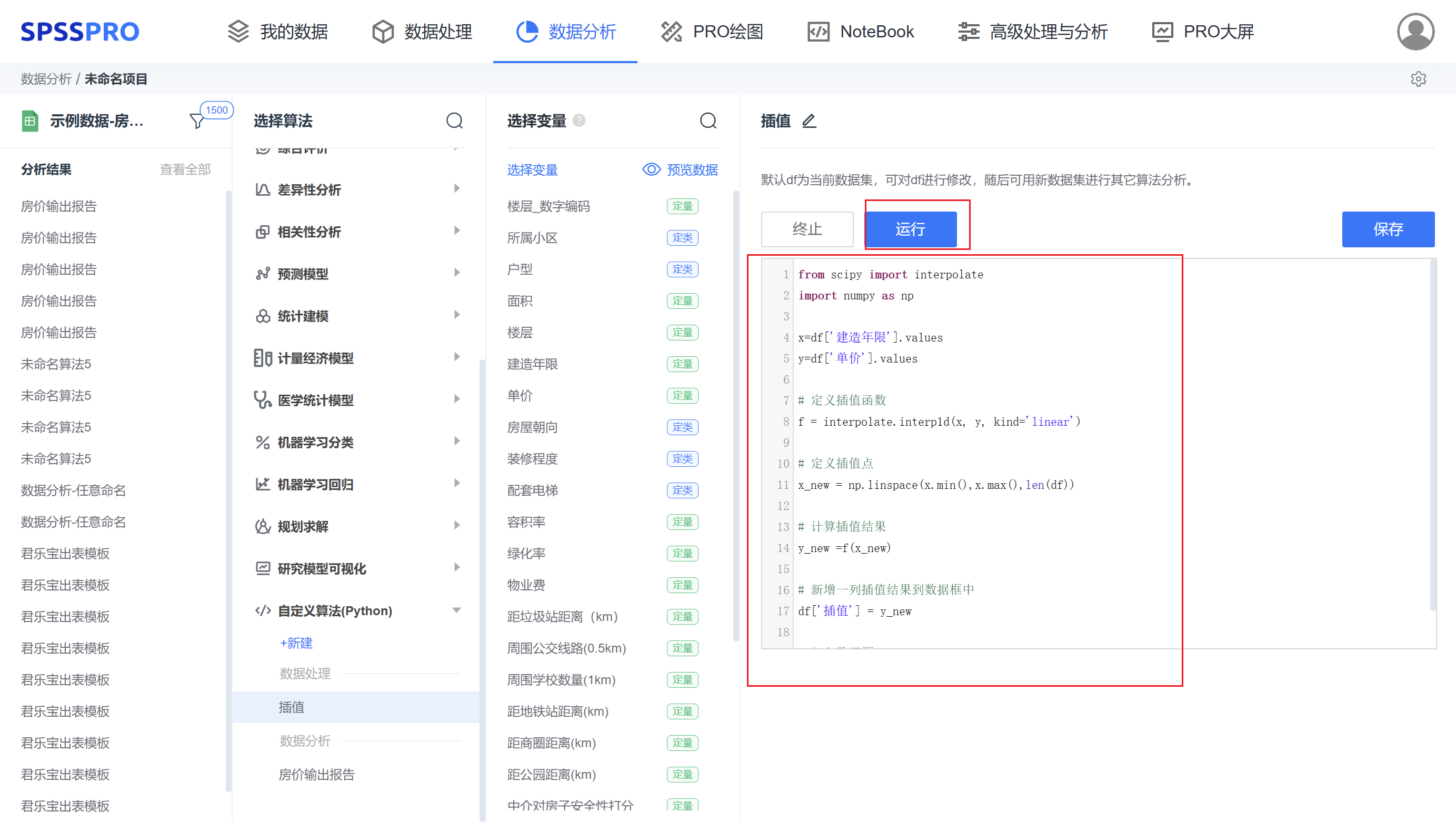
step4:可在代码框中查看报错信息或者运行结果。
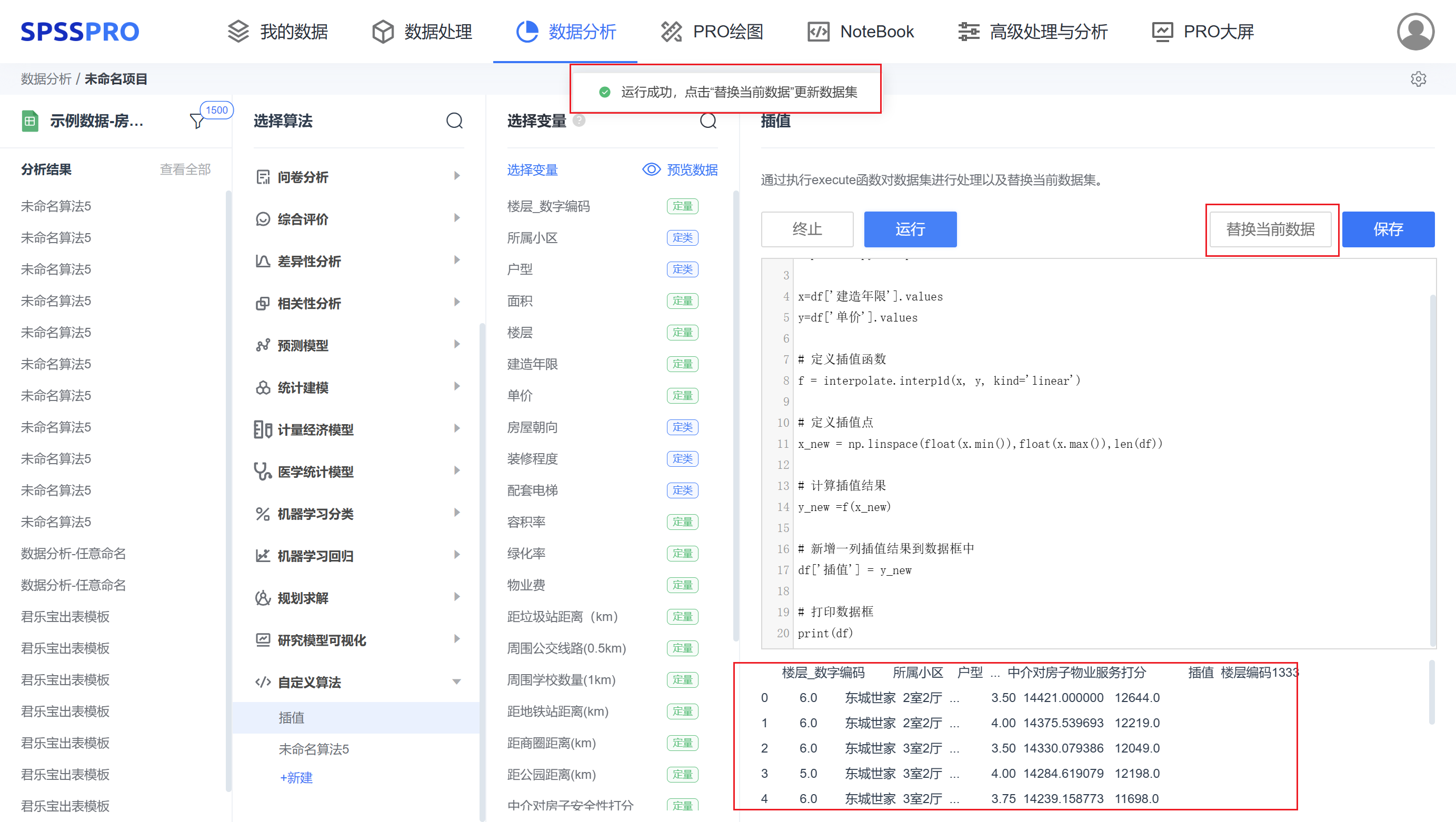
step5:运行完成后系统识别到 df 有所变换,生成”替换数据集“,点击此按钮替换数据集。
# 3、内置变量
df:当前数据集,即已经导入 SPSSPRO 并且进入到数据分析模块的数据集。在脚本中可以 print(df)进行查看。
注意:数据处理必须是对 df 这个数据集进行修改,在运行完成后系统识别到 df 所指代的数据框是否有变化,若有变化则会生成”替换数据集“按钮,点击此按钮替换数据集。
# 4、案例代码
#以下是一个对根据 x 和 y 的关系来对 y 进行线性插值,并在原本数据集 df 上添加新列 df['插值']的数据处理操作。
from scipy import interpolate
import numpy as np
x=df['建造年限'].values
y=df['单价'].values
f = interpolate.interp1d(x, y, kind='linear')
x_new = np.linspace(float(x.min()),float(x.max()),len(df))
y_new =f(x_new)
df['插值'] = y_new
print(df)
# 4、可调用库
numpy、pandas、statsmodels、scipy 、random、math、re、datetime、sklearn、symbol
# 5、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.