自定义数据分析
# 1、作用
自定义算法基于 Python,通过自定义代码实现数据分析以及输出分析报告。
# 2、操作步骤
# 2.1代码模式
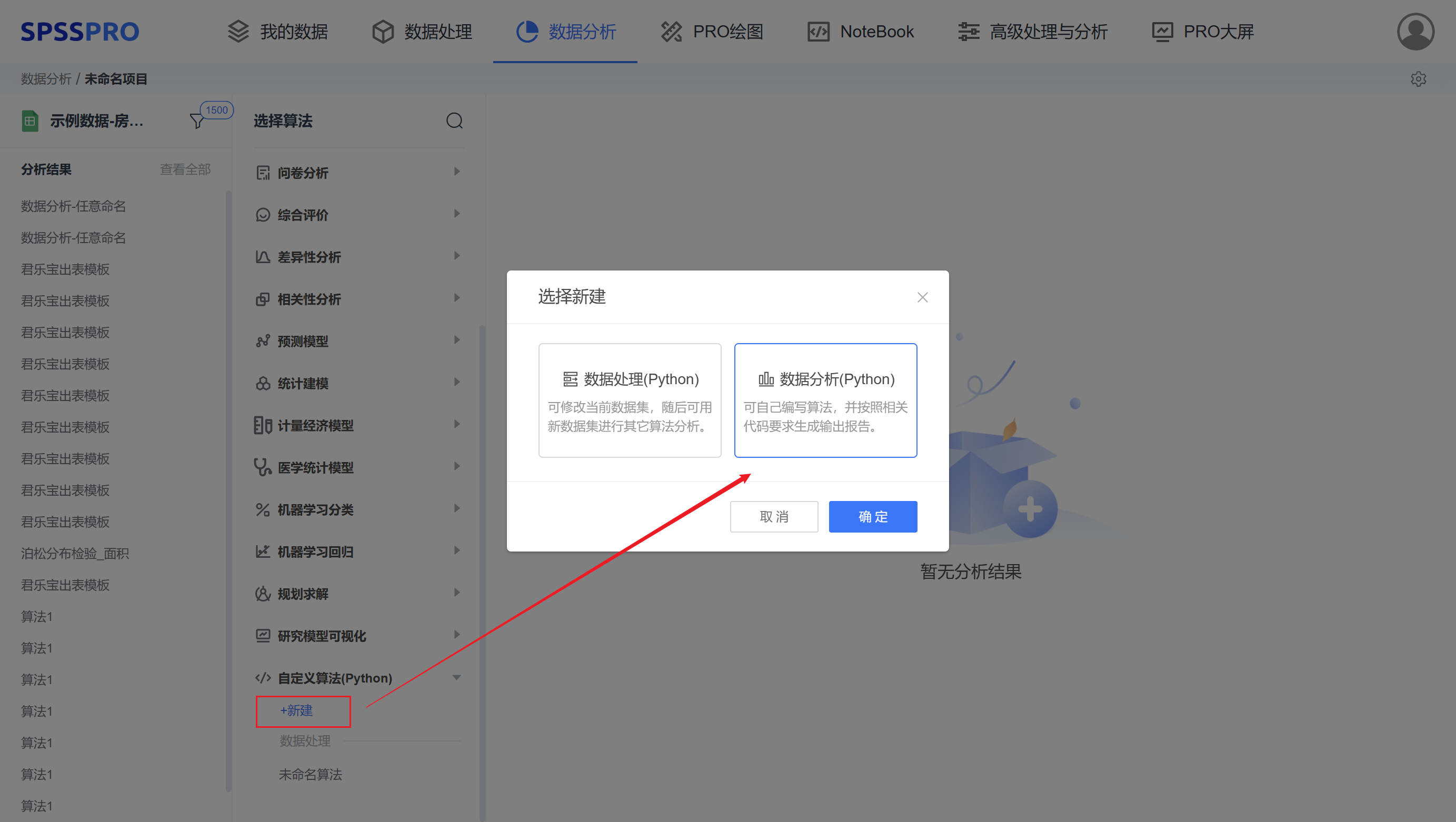
Step1:在【自定义算法(Python)】中点击新建,按照算法目的来创建脚本。
数据处理:可修改当前数据集 df,随后可用新数据集进行其它算法分析。
数据分析:可自己编写算法,并按照相关代码要求生成输出报告。
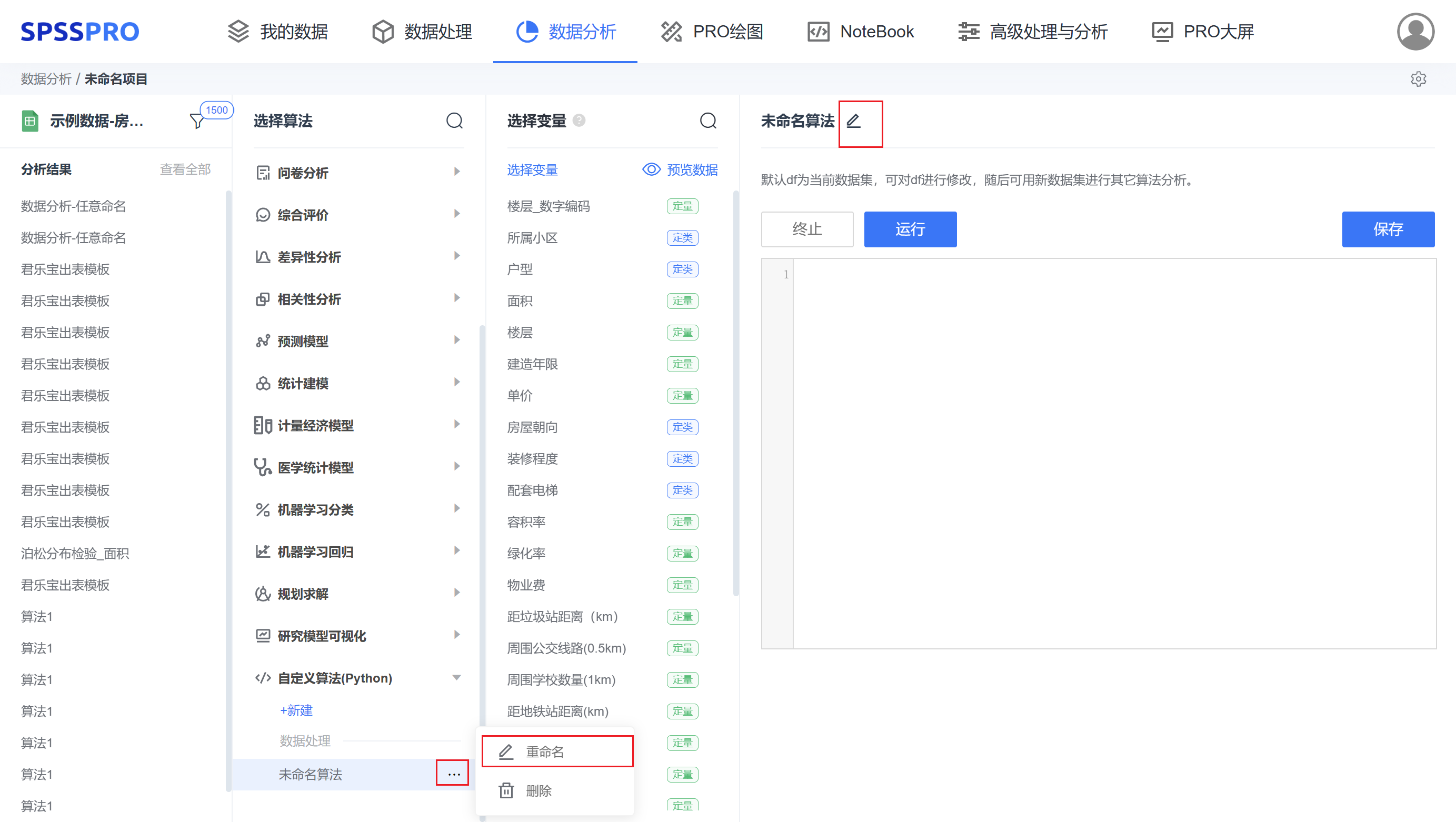
Step2:对算法命名,当前有两个渠道对算法进行重命名。
Step3:开始填写代码,点击”运行“按钮,也可随时”终止“。
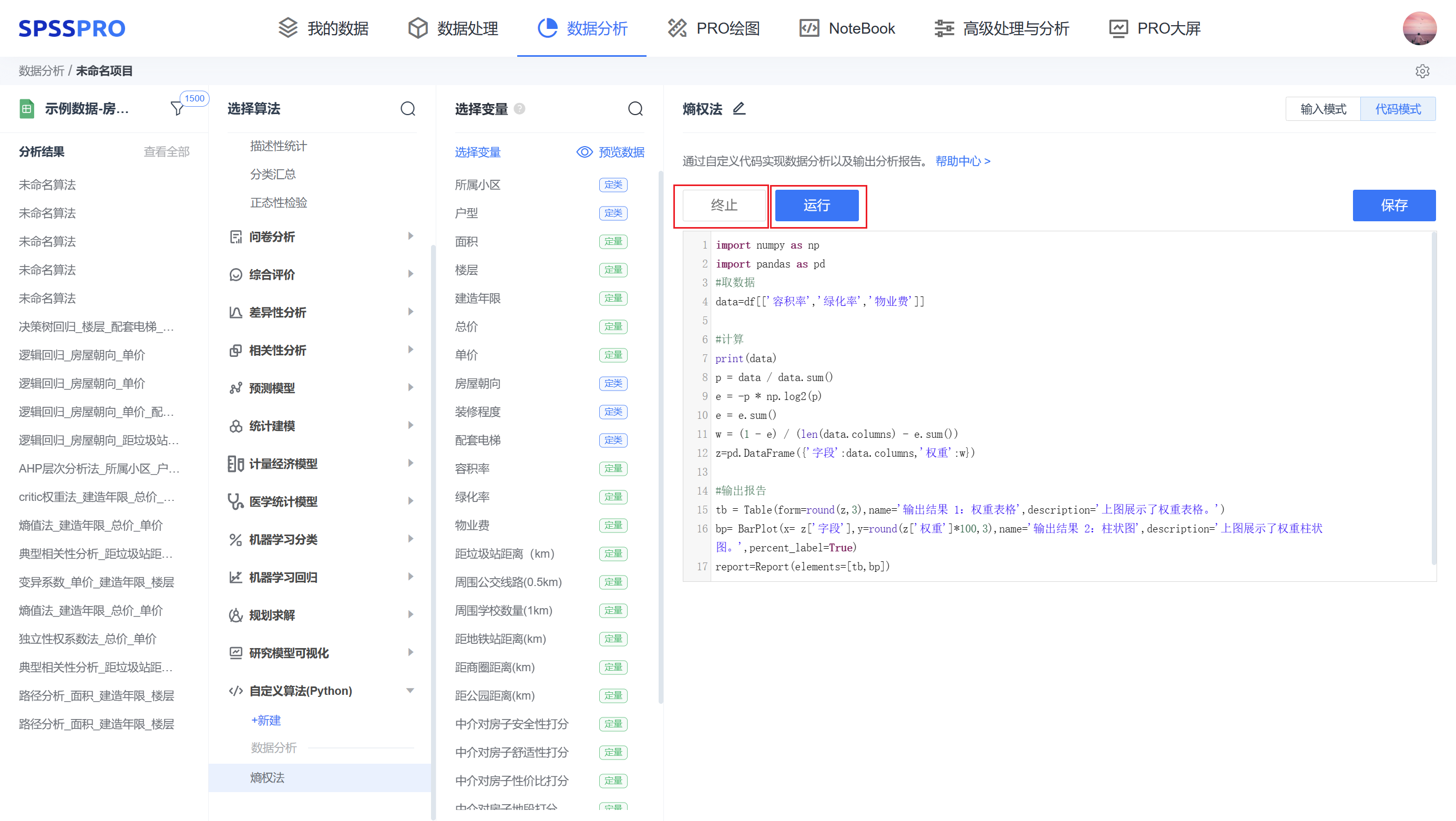
step4:可在代码框中查看报错信息或者 print( ) 运行结果。
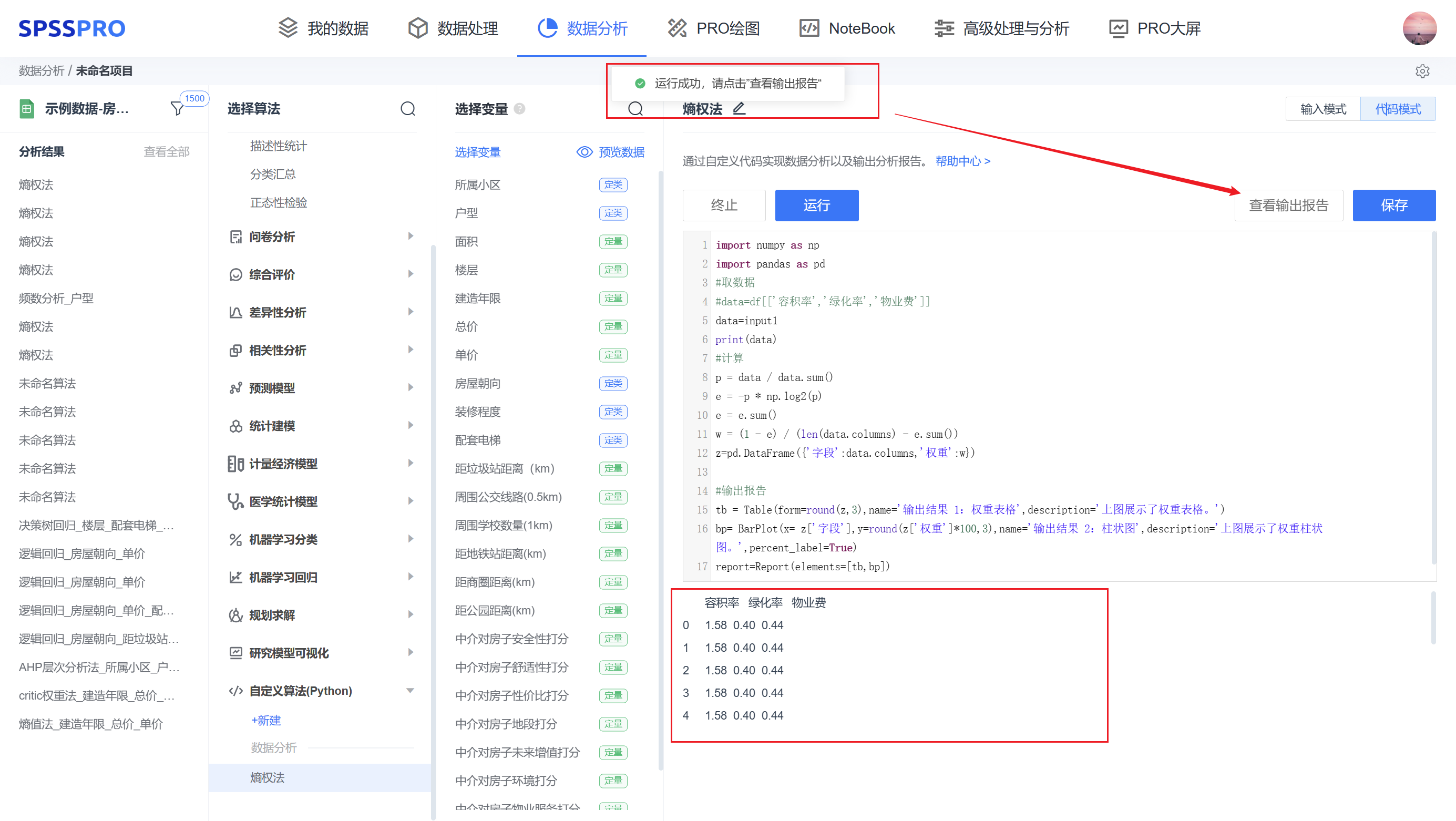
step5:运行完成后系统识别到 report,就会生成”查看输出报告“,点击此按钮将跳转到输出报告页面。
# 2.2 输入模式操作步骤
普通的代码模式仅对当前数据具有普适性,针对于不同的数据每次在运行前都需要去修改列名。这时就可以将算法进行封装,后续拖拉拽变量即可生成输出报告。
step1:点击输入模式,随机切换到输入模式
step2:点击输入配置
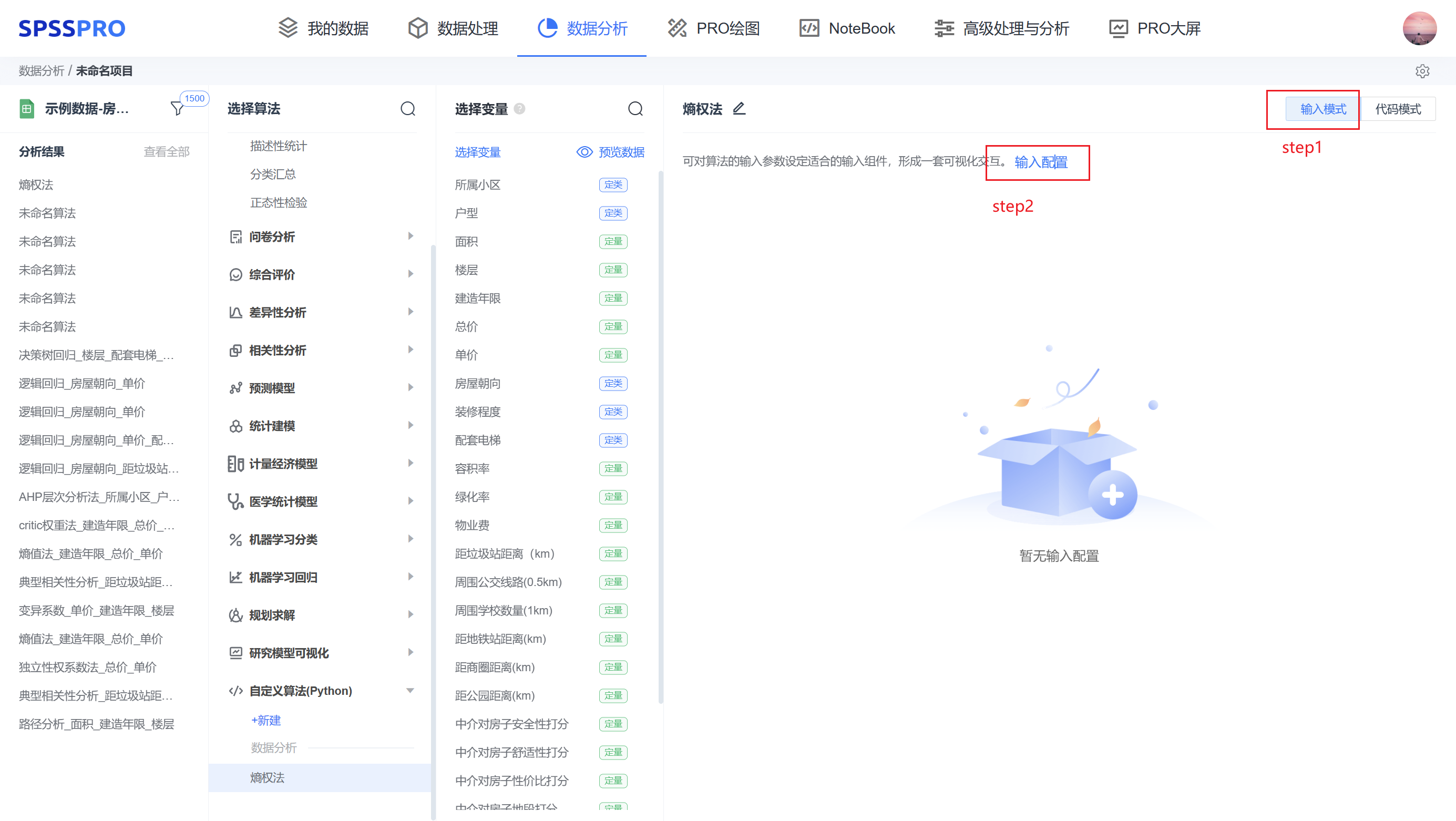
step3:输入组件有拖拽框、下拉选择框、数字输入器,由于熵权法只需要拖入变量,只设置一个拖拽框即可。(但是需要留意组件前面的“input1”,拖拽框在代码中作为数据框来使用,设置成功后,当拖入了变量进拖拽框后,系统会自动识别input1所包含了哪些变量,并进行运算)
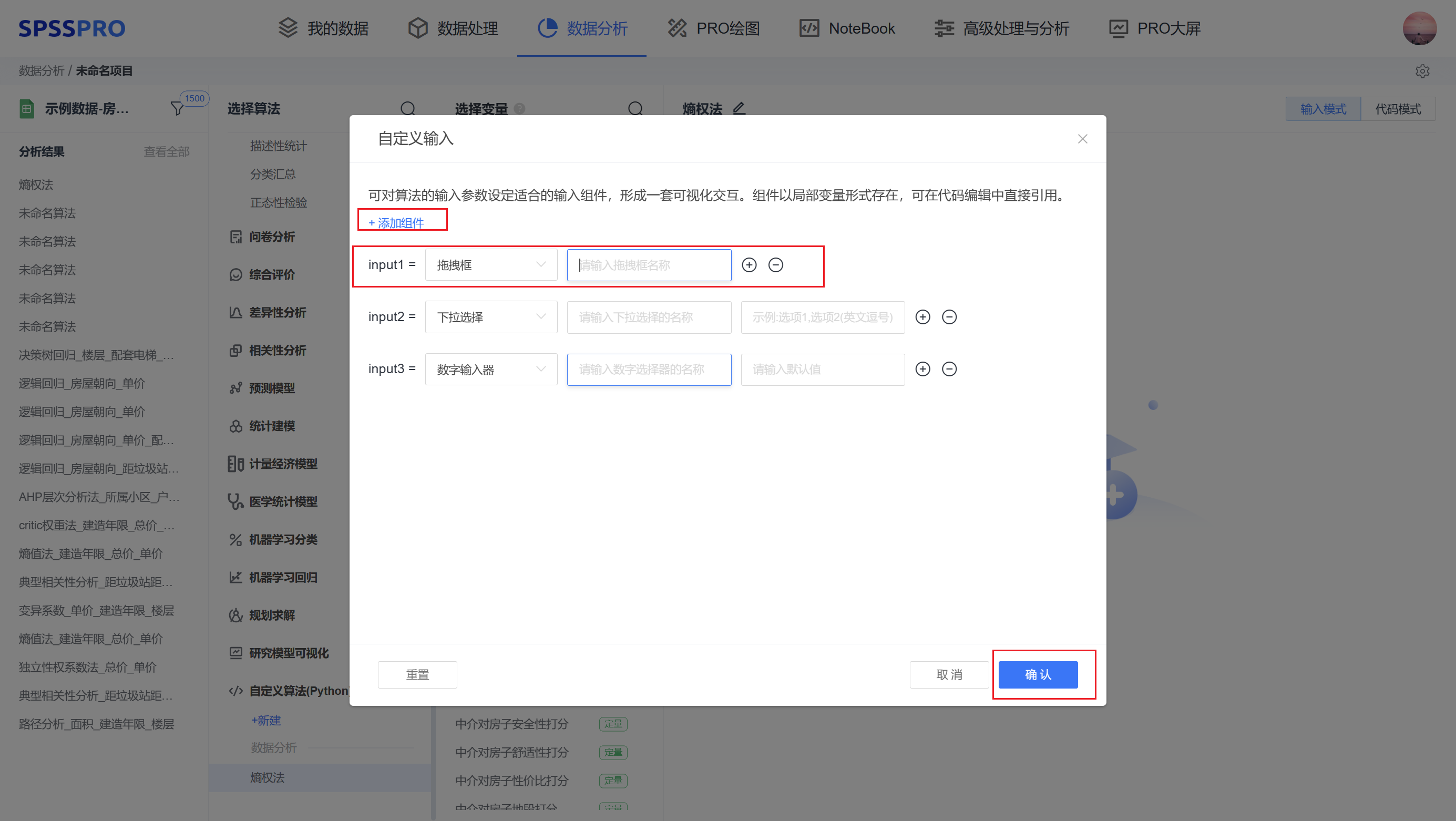 step4:同时在代码模式中去使用input1
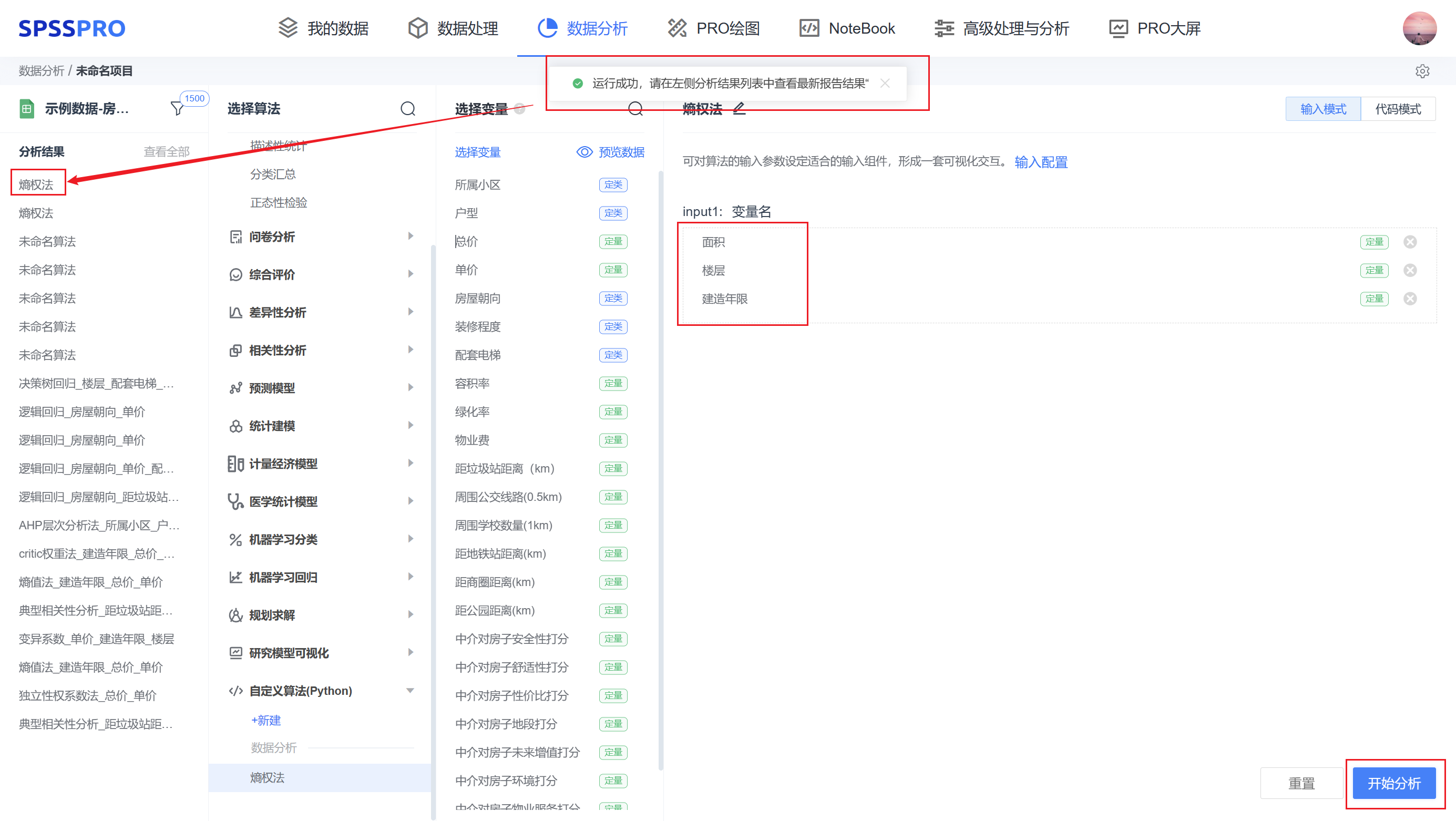
step5:随后再回到输入模式,将其它变量拖入到变量框中后,点击“开始分析”
step4:同时在代码模式中去使用input1
step5:随后再回到输入模式,将其它变量拖入到变量框中后,点击“开始分析”
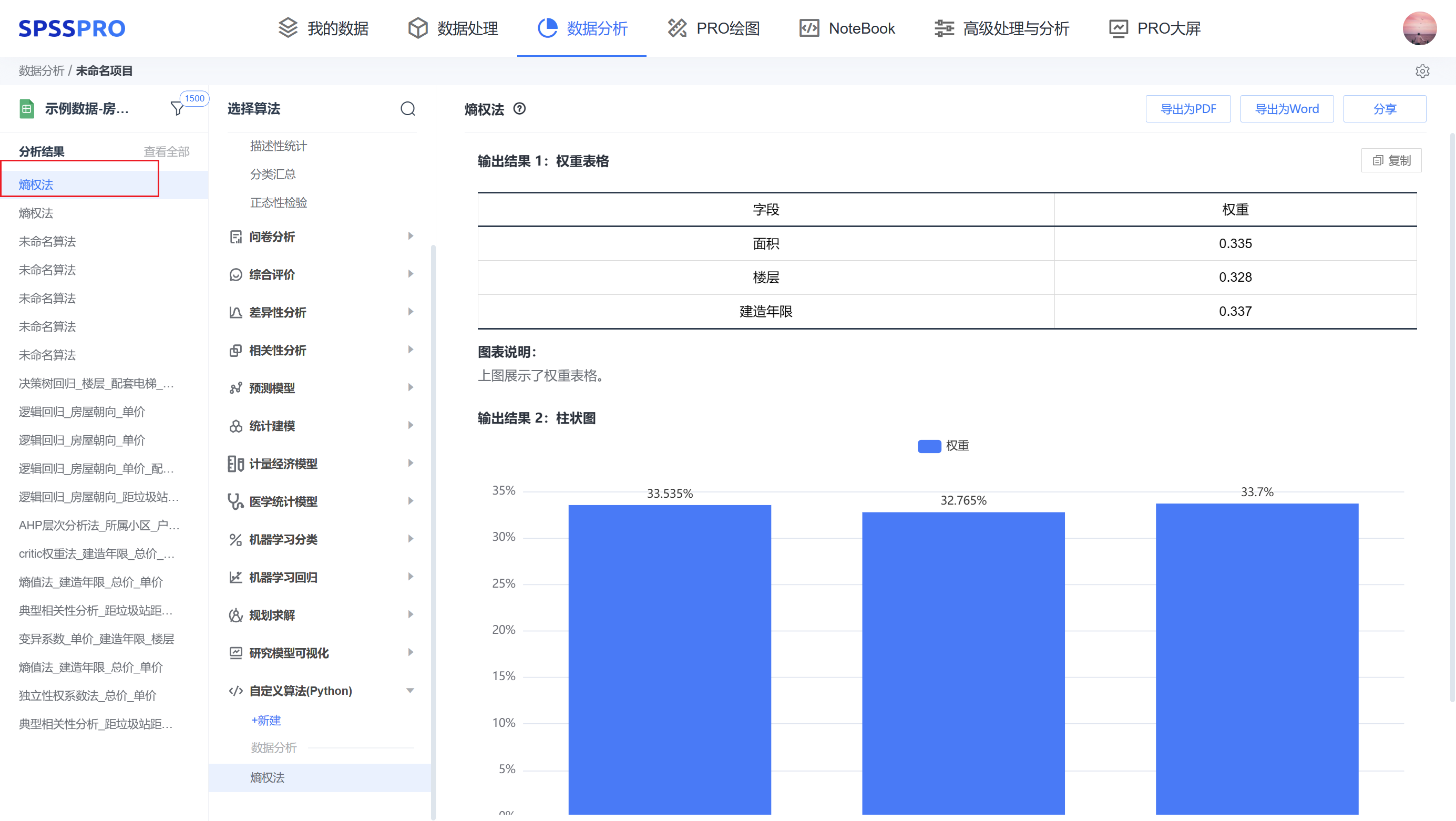
step6:查看结果
# 3、内置变量
df:当前数据集,即已经导入 SPSSPRO 并且进入到数据分析模块的数据集。在脚本中可以 print(df)进行查看。
report:输出报告,当内置函数 Report()定制化了一份输出报告后,需将其赋值给 report 才会生成输出报告。
# 4、内置函数
散点图 ScatterPlot()、箱线图 BoxPlot()、折线图 LinePlot()、XY折线图XYLinePlot()、柱形图 BarPlot()、饼图PieChart()、堆叠柱形图StackColumnChart()、词云图 CloudWord()、象限图QuadrantPlot()、地图MapPlot()、叠图OverlapXYPlot()、XY组合图XYPlots()、子图SubPlots()、表格 Table()、文本 Text()、报告 Report()、异常抛出
# (1)散点图
ScatterPlot(x,y,group=None,name,description=None,txt_label=None,font_size=12)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| x | 横坐标的序列 | 序列series | 允许1个定量序列 |
| y | 纵坐标的序列 | 序列series | 允许1个定量序列 |
| group | 分组字段,可将散点按照不同组别划分 | 序列series | 允许0或1个序列 |
| name | 散点图的标题 | 字符串string | 允许1个字符串 |
| description | 散点图的图表说明 | 字符串string | 允许1个字符串 |
| txt_label | 各个散点的标签名称 | 字符串string | 允许1个序列 |
| font_size | 调整图表中文本字号的大小 | 整型 | 允许1个整数 |
e= ScatterPlot(
x=df['x1'],
y=df['x2'],
group=None,
name = "输出结果:x1-x2散点图",
description = "上图展示了x1-x2散点图。")
# (2) 箱线图
BoxPlot(x,name,description=None,font_size=12)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| x | 生成箱状图的序列 | 序列series | 允许1个及以上的定量序列 |
| name | 箱状图的标题 | 字符串string | 允许1个字符串 |
| description | 箱状图的图表说明 | 字符串string | 允许1个字符串 |
| font_size | 调整图表中文本字号的大小 | 整型 | 允许1个整数 |
e = BoxPlot(
x=[df['x1'],df['x2']],name="输出结果:x1/x2箱线图",description ="上图展示了x1/x2箱线图。")
# (3) 时序折线图
LinePlot(index,y,name,description=None,font_size=12)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| index | 横坐标的索引序列 | 序列series | 允许1个序列 |
| y | 纵坐标的序列 | 序列series | 允许1个及以上的定量序列 |
| name | 折线图的标题 | 字符串string | 允许1个字符串 |
| description | 折线图的图表说明 | 字符串string | 允许1个字符串 |
| font_size | 调整图表中文本字号的大小 | 整型 | 允许1个整数 |
indexS=np.arange(1,len(df)+1,1)
e = LinePlot(
index=pd.Series(indexS),
y=[df['x2'],df['x3']],name="输出结果:X2/X3时序折线图",description = "上图展示了X2/X3时序折线图。")
# (4) XY折线图
XYLinePlot(x,y,name,description=None,txt_label=None,font_size=12)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| index | 横坐标的序列 | 序列series | 允许1个序列 |
| y | 纵坐标的序列 | 序列series | 允许1个定量序列 |
| name | 折线图的标题 | 字符串string | 允许1个字符串 |
| description | 折线图的图表说明 | 字符串string | 允许1个字符串 |
| txt_label | 各个散点的标签名称 | 字符串string | 允许1个序列 |
| font_size | 调整图表中文本字号的大小 | 整型 | 允许1个整数 |
e= LinePlot(
x=df['x1'],
y=df['x2'],name="输出结果:以x1-x2折线图",description = "上图展示了以x1为横轴,x2为纵轴的折线图。")
# (5)柱形图
BarPlot(x,y,name,description, percent= False,percent_label= False,data_labels=True,font_size=12)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| x | 横坐标的序列 | 序列series | 允许1个序列 |
| y | 纵坐标的序列 | 序列series | 允许1个及以上的定量序列 |
| name | 柱形图的标题 | 字符串string | 允许1个字符串 |
| description | 柱形图的图表说明 | 字符串string | 允许1个字符串 |
| percent | True:自动根据数值求百分比 | bool | True、False |
| data_labels | True:数值展示在图表上 | bool | True、False |
| percent_label | True:数值的后面加上“%” | bool | True、False |
| font_size | 调整图表中文本字号的大小 | 整型 | 允许1个整数 |
a=pd.Series(['A','B','C'])
b=pd.Series([34,50,16])
c=pd.Series([80,50,16])
e= BarPlot(x=a,y=[b,c],name='输出结果:分组柱状图',description='上图展示了分组柱状图。')
# (6)饼图
PieChart(x,y=None,name,description=None, percent= False,percent_label= False,data_labels=True,font_size=12)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| x | 若只传入x序列,则自动会对去重项进行频数统计 | 序列 series | 允许 1 个序列 |
| y | 若同时传入x,y序列,其中x代表去重项,y代表去重项的数值 | 序列 series | 允许 1 个及以上的序列 |
| name | 标题(名称) | 字符串string | 允许 1 个字符串 |
| description | 图表说明(文本描述) | 字符串string | 允许 1 个字符串 |
| percent | True:自动根据数值求百分比后展示 | bool | True、False |
| data_labels | True:数值展示在图表上 | bool | True、False |
| percent_label | True:数值以及坐标值的展现加上“%” | bool | True、False |
| font_size | 调整图表中文本字号的大小 | 整型 | 允许1个整数 |
a=pd.Series(['A','B','C','A','B','C','A','B','C','A','B','C'])
e= PieChart(x=a,name='输出结果:饼图',description='上图展示了饼图。')
# (7)堆叠柱形图
StackColumnChart(x,y,name,description=None, percent= False,percent_label= False,data_labels=True,font_size=12)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| x | 横坐标的索引序列 | 序列 series | 允许 1 个序列 |
| y | 多个y轴进行堆叠 | 序列 series | 允许 1 个及 1 个以上的序列 |
| name | 标题(名称) | 字符串 string | 允许 1 个字符串 |
| description | 图表说明(文本描述) | 字符串 string | 允许 1 个字符串 |
| percent | True:自动根据数值求百分比后展示 | bool | True、False |
| data_labels | True:数值展示在图表上 | bool | True、False |
| percent_label | True:数值以及坐标值的展现加上“%” | bool | True、False |
| font_size | 调整图表中文本字号的大小 | 整型 | 允许1个整数 |
a=pd.Series(['A','B','C'])
b=pd.Series([34,50,16])
c=pd.Series([80,50,16])
e = StackColumnChart(x=a,y=[b,c],name='输出结果 :堆叠柱状图',description='上图展示了堆叠柱状图。')
# (8)词云图
CloudWord(x,y=None,name,description=None)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| x | 若只传入x序列,则自动会对去重项进行频数统计 | 序列 series | 允许 1 个序列 |
| y | 若同时传入x,y序列,其中x代表去重项,y代表去重项的数值 | 序列 series | 允许 1 个及 1 个以上的序列 |
| name | 标题(名称) | 字符串 string | 允许 1 个字符串 |
| description | 图表说明(文本描述) | 字符串 string | 允许 1 个字符串 |
a=pd.Series(['A','B','C','C','B','C','C'])
e = CloudWord(x=a,name='输出结果 :词云图',description='上图展示了词云图。')
# (9)象限图
QuadrantPlot(x,y,name,description=None,txt_label=Series,font_size=12)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| x | 横坐标的序列 | 序列series | 允许1个定量序列 |
| y | 纵坐标的序列 | 序列series | 允许1个定量序列 |
| name | 标题(名称) | 字符串 string | 允许 1 个字符串 |
| description | 图表说明(文本描述) | 字符串 string | 允许 1 个字符串 |
| txt_label | 各个散点的标签名称 | 字符串string | 允许1个序列 |
| font_size | 调整图表中文本字号的大小 | 整型 | 允许1个整数 |
e = QuadrantPlot(x=df['x1'],y=df['x2'],name = "输出结果:象限图",description = "上图展示了以x1的均值和x2的均值作为辅助线的象限图。")
# (10)叠图
OverlapXYPlot(x,y,name,description=None,scatter=False)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| x | 横坐标的序列 | 序列series | 允许1个定量序列 |
| y | 纵坐标的序列 | 序列series | 允许1个及以上定量序列 |
| subname | 叠图中各个子图的名称 | 列表list | 1个列表 |
| name | 标题(名称) | 字符串 string | 允许 1 个字符串 |
| description | 图表说明(文本描述) | 字符串 string | 允许 1 个字符串 |
| scatter | True:叠图中各个折线图上标注散点 | bool | True、False |
e = OverlapXYPlot(
x=df['x1'],
y=[df['x2'],df['x3'],df['x4']],
name = "输出结果:象限图",
description = "上图展示了以x1为横坐标,x2、x3、x4分别为纵坐标的叠图")
# (11)XY组合图
XYPlots(elements , name=None , description)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| elements | 子图的元素(仅允许ScatterPlot和XYLinePlot) | 列表 | 允许1个列表,列表内是已经绘制的散点图和xy折线图 |
| name | 标题(名称) | 字符串 string | 允许 1 个字符串 |
| description | 图表说明(文本描述) | 字符串 string | 允许 1 个字符串 |
e1 = ScatterPlot(
x=df['x1'],
y=df['x2'])
e2 = LinePlot(
x=df['x1'],
y=[df['x2'])
e=XYPlots(elements=[e1,e2],
name="输出结果:XY组合图",
description="上图展现的是一个散点图和一个折线图的组合图")
# (12)子图
SubPlots(shape,elements,subname,name,desciption=None)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| shape=[row,col] | 子图的个数[row,col] | 列表list | row代表行数,col代表列数,比如[4,3]代表四行三列,最多放4*3=12个图表 |
| elements | 子图的元素 | 列表list | 允许1个列表,列表内是已经绘制的各个图表 |
| subname | 叠图中各个子图的名称 | 列表list | 1个列表 |
| name | 标题 | 字符串 string | 允许 1 个字符串 |
| description | 图表说明 | 字符串 string | 允许 1 个字符串 |
e1 = ScatterPlot(
x=df['x1'],
y=df['x2'])
e2 = LinePlot(
x=df['x1'],
y=[df['x2'])
a=pd.Series(['A','B','C'])
b=pd.Series([34,50,16])
e3=BarPlot(x=a,y=b)
e=SubPlots(shape=[2,2],elements=[e1,e2,e3],subname=['图1','图2','图3'],name='输出结果:子图",description='上图中展现了三个子图')
# (13)地图
MapPlot(area,number,name ,description=None,data_label=False)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| area | 当前仅支持中国省份简称,如广东省、上海市、新疆维吾尔自治区,应被写成广东、上海、新疆 | 序列Series | 允许1个序列 |
| number | 各个省份的数值 | 序列Series | 允许1个定量序列 |
| name | 标题 | 字符串 string | 允许 1 个字符串 |
| description | 图表说明 | 字符串 string | 允许 1 个字符串 |
| data_label | True:将各个省份的number值展示出来 | bool | True、False |
MapPlot(
area=df['地区‘],
number=df['人数'],
name= "输出结果 :地图",
description = "上图展示了地图。",
data_label=False)
# (14) 表格
Table(form,name,description=None)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| form | 表格的内容(包括表头和数据值) | 数据框dataframe | 允许1个数据框 |
| name | 表格的标题 | 字符串string | 允许1个字符串 |
| description | 表格的图表说明 | 字符串string | 允许1个字符串 |
data = [[110, 120, 110], [130, 130, 130], [130, 120, 130]]
columns = ['语文', '数学', '英语']
score= pd.DataFrame(data=data, columns=columns)
tb = Table(
form=score,
name='输出结果5:成绩表格',
description='上图展示了各科成绩表格。')
# (15)文本
Text(name,description)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| name | 标题(名称) | 字符串string | 允许1个字符串 |
| description | 图表说明(文本描述) | 字符串string | 允许1个字符串 |
txt = Text(
name='输出结果6:总结',
description='由以上分析,得出XX结论')
# (16)输出报告
将上述绘图对象作为参数传给Report(),并且还需要Report赋值给report,当系统成功识别到report,就会生成输出报告。 report=Report(elements)
| 参数 | 参数说明 | 参数类型 | 参数条件 |
|---|---|---|---|
| elements | 将绘制的各个图标放进报告后输出 | 列表 | 允许1个列表,列表内是已经绘制的各个图表 |
e1 = ScatterPlot(
x=df['x1'],
y=df['x2'])
e2 = LinePlot(
x=df['x1'],
y=[df['x2'])
a=pd.Series(['A','B','C'])
b=pd.Series([34,50,16])
e3=BarPlot(x=a,y=b)
report=Report(elements=[e1,e2,e3])
# (17)异常抛出
当if满足了某个条件时,就异常抛出,中断算法运行,并给出提示”算法报错,请检查数据“
if True:
raise CustomScriptError('算法报错,请检查数据')
# 5、案例代码
以下是将熵权法的结果进行封装的案例,如果仅使用代码模式,我们需要提取参与计算的数据data=df[['容积率','绿化率','物业费']],但如果使用输入配置,则data=input1,直接在输入页面将变量进行拖入即可。
import numpy as np
import pandas as pd
#取数据
#data=df[['容积率','绿化率','物业费']]
data=input1
#计算
print(data)
p = data / data.sum()
e = -p * np.log2(p)
e = e.sum()
w = (1 - e) / (len(data.columns) - e.sum())
z=pd.DataFrame({'字段':data.columns,'权重':w})
#输出报告
tb = Table(form=round(z,3),name='输出结果 1:权重表格',description='上图展示了权重表格。')
bp= BarPlot(x= z['字段'],y=round(z['权重']*100,3),name='输出结果 2:柱状图',description='上图展示了权重柱状图。',percent_label=True)
report=Report(elements=[tb,bp])
# 6、可调用库
numpy、pandas、statsmodels、scipy 、random、math、re、datetime、sklearn、symbol
# 7、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.