逻辑回归
# 1、作用
逻辑回归是研究二分类因变量观与一些影响因素之间关系的一种多变量分析方法。但如果因变量是多个类别的,则要用到多分类逻辑回归去研究因变量与一些影响因素之间的关系。
# 2、输入输出描述
输入:因变量 Y 为分类变量,自变量 X 为至少一项定量变量或定类变量。
输出:逻辑回归系数估计以及分类预测的效果评价。
# 3、案例示例
示例:根据年龄、月收入、性别、家庭人口等影响因素(自变量)来研究工薪群体的上下班交通工具是公交地铁、自行车、还是私家车(因变量)。
# 4、案例数据
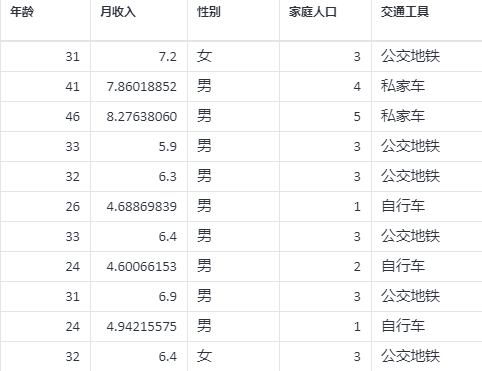
逻辑回归案例数据
# 5、案例操作
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
step4:选择【逻辑回归】;
step5:查看对应的数据数据格式,按要求输入【逻辑回归】数据;
step6:点击【开始分析】,完成全部操作。
# 6、输出结果分析
输出结果 1:多分类因变量基本汇总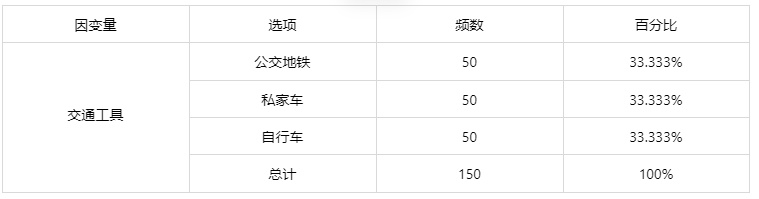
图表说明:上表展示了因变量各分组的分布情况。
由表可知,因变量各分类水平的百分比都相同,说明各分类的样本是很均衡的,不需要进行过采样或欠采样,可以接着做逻辑回归。
输出结果 2:模型评价

图表说明:表展示了模型评价指标,可用于对模型的表现进行评估或有效性进行验证,其包括似然比检验,p 值,AIC 值、BIC 值。
● 对 p 值进行分析,如果该值小于 0.05,则说明模型有效;反之则说明模型无效。
● AIC 值和 BIC 值用于对比两个模型的优劣时使用,此两个值均为越小越好。
分析:模型的似然比卡方检验的结果显示,显著性 𝑝 值 0.000***,水平上呈现显著性,拒绝原假设,因而模型是有效的。
输出结果 3:多分类逻辑回归结果 
图表说明:上表展示了模型的参数结果,可用于生成模型公式。包括模型的系数、标准误差、OR 值、置信区间等。
● OR 值(优势比):为实验组的事件发生几率/对照组的事件发生几率。
● 对于连续自变量的 OR 值的意义为:该变量每升高一个单位,发生实验组事件的几率比发生对照组事件的几率变化了(OR 值-1)%。
● 对于哑变量化的 0-1 分类自变量的 OR 值意义为:该变量每升高一个单位(即分类水平从 0 变为 1),发生实验组事件的几率比发生对照组事件的几率变化了(OR 值-1)%。
分析:对于多分类逻辑回归,需要选择有一个分类水平作为基水平,分别对这个基水平去其他分类水平建立二分类逻辑回归,在本例中,选择了“公交地铁”作为基水平,分别建立了“公交水平-私家车”和“公交水平-自行车”这两个二分类逻辑回归器。
基于参考公交地铁 ->私家车:
只有字段 性别男 是显著的,字段性别男显著性 𝑝 值为 0.000***,水平上呈现显著性,拒绝原假设,因此性别_男会对交通工具产生显著性影响,意味着性别 每增加一个单位,(在本例中,对分类变量进行了哑变量,其中性别男=1,性别女=0,意味着从分类水平从 0 变为 1,也就是当性别为男性时,交通工具为私家车的几率比公交地铁的几率高了 982.888%;)
基于参考公交地铁 ->自行车:
字段年龄 显著性 𝑝 值为 0.044**,水平上呈现显著性,拒绝原假设,因此年龄 会对交通工具产生显著性影响,意味着年龄 每增加一个单位,交通工具为自行车的几率比公交地铁的几率高了 18.723%。
字段家庭人口显著性 𝑝 值为 0.000***,水平上呈现显著性,拒绝原假设,因此家庭人口会对交通工具产生显著性影响,意味着家庭人口每增加一个单位,交通工具为自行车的几率比公交地铁的几率低了 91.381%。
字段性别男显著性 𝑝 值为 0.000***,水平上呈现显著性,拒绝原假设,因此性别男会对交通工具产生显著性影响,意味着性别 每增加一个单位,(在本例中,对分类变量进行了哑变量,其中性别男=1,性别女=0,意味着从分类水平从 0 变为 1,也就是当性别为男性时,交通工具为私家车的几率比公交地铁的几率高了 9183.612%;)
输出结果 4:混淆矩阵热力图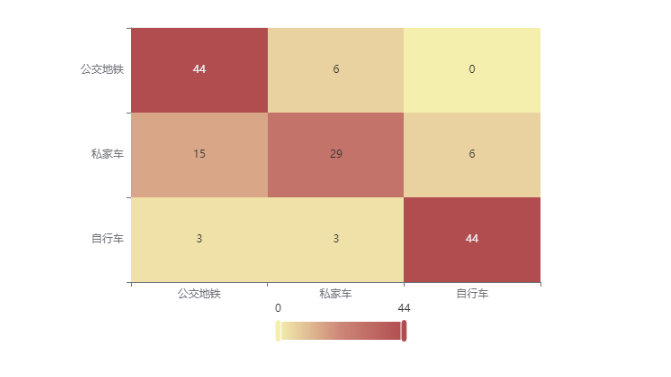
图表说明:上表以热力图的形式展示了混淆矩阵。
输出结果 5:分类评价指标
| 准确率 | 召回率 | 精确率 | F1 | AUC |
|---|---|---|---|---|
| 0.78 | 0.78 | 0.784 | 0.775 | 0.89 |
图表说明:上表中展示了分类评价指标,进一步通过量化指标来衡量逻辑回归的分类效果。
● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用 F1 指标。
● AUC:AUC 值越接近 1 说明分类效果越好。
综合各指标的值可知,建立的多分类逻辑回归的分类效果是中等偏上的,具有一定意义。
# 7、注意事项
- 对于多分类逻辑回归,spsspro 默认用了将某一类和剩余的类比较作为二分类问题,N 个类别进行 N-1 次分类,得到 N-1 个二分类模型,求出每种二分类对应的概率,概率最高的一类作为新样本的预测结果。
- 逻辑回归如果有输入定类数据,那么要求该定类数据必须为二分类定类数据(哑变量化),因此 SPSSPRO 的输入变量 X2 中要求数据为定类数据,若数据不为二分类定类数据,SPSSPRO 会自动将其哑变量化
# 8、模型理论
对于二分类问题,
考虑到 ![]() 取值是连续的,因此它不能拟合离散变量。可以考虑用它来拟合条件概率
取值是连续的,因此它不能拟合离散变量。可以考虑用它来拟合条件概率 ![]() ,因为概率的取值也是连续的。
,因为概率的取值也是连续的。
最理想的是单位阶跃函数:
但是这个阶跃函数不可微,对数几率函数是一个常用的替代函数:
上式可以化成
其中, y 视为 x 为正例的概率, 1-y 为 x 为其反例的概率。两者的比值称为几率(odds)。所以,逻辑回归中事实上因变量值应是 odds。
将 y 视为类后验概率估计,重写公式有:
针对于多分类逻辑回归,spsspro 默认用了将某一类和剩余的类比较作为二分类问题,N 个类别进行 N-1 次分类,得到 N-1 个二分类模型,求出每种二分类对应的概率,概率最高的一类作为新样本的预测结果。
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2]袁翔宇,张蓬鹤,熊素琴,等. 基于逻辑回归算法的异常用电辨识方法研究[J]. 电测与仪表,2021,58(12):81-87. DOI:10.19753/j.issn1001-1390.2021.12.012.